 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating and Preserving Lexical Stress in English-to-Chinese Speech-to-Speech Translation
Jun 13, 2026Speech-to-speech translation (S2ST) systems have achieved impressive progress in semantic accuracy and speech naturalness. However, the cross-lingual transfer of lexical stress, a vital cue for emphasis and speaker intent, remains heavily underexplored, compounded by a lack of reliable automatic evaluation metrics for tonal languages like Chinese. We investigate English-to-Chinese S2ST stress transfer by constructing a stress-annotated Chinese dataset and an XLS-R-based Mandarin stress detector. Integrating this with the English EmphAssess system, we propose a novel objective metric for cross-lingual stress evaluation. Furthermore, we fine-tune CosyVoice3 to build a stress-aware S2ST system. Experiments demonstrate that our proposed S2ST architecture significantly outperforms existing systems in stress translation capability while maintaining competitive translation quality. Furthermore, our evaluation metric exhibits a strong correlation with human subjective judgments.
Ω-QVLA: Robust Quantization for Vision-Language-Action Models via Composite Rotation and Per-step Scaling
May 27, 2026Vision-Language-Action (VLA) models unify perception, reasoning, and control within a single policy, yet their multi-billion-parameter backbones and diffusion-based action heads make on-device deployment prohibitively expensive. Prior quantization efforts offer only partial solutions, compressing the LLM backbone while leaving the DiT action head at full precision, or resorting to mixed-precision schemes, driven by the belief that uniformly quantizing the action head is inherently unstable. We challenge this assumption with Omega-QVLA, the first training-free post-training quantization framework that compresses both the language backbone and the entire diffusion action head of a VLA model to a uniform W4A4 precision, eliminating the need for mixed-precision allocation. Omega-QVLA combines a composite SVD-Hadamard rotation that equalizes per-channel weight energy while diffusing residual activation outliers with per-step DiT activation scaling quantization that absorbs dynamic-range drift across denoising steps. On LIBERO, Omega-QVLA compresses Pi 0.5 and GR00T N1.5 to W4A4 with 98.0% and 87.8% task success rates, matching or exceeding their FP16 references of 97.1% and 87.0%, while reducing the static memory footprint by 71.3%. Real-world manipulation experiments further confirm smooth, accurate manipulation where prior methods fail. Code is available at https://github.com/UCMP13753/Omega-QVLA.
Agentic Fusion of Large Atomic and Language Models to Accelerate Materials Discovery
Apr 26, 2026The discovery of novel materials is critical for global energy and quantum technology transitions. While deep learning has fundamentally reshaped this landscape, existing predictive or generative models typically operate in isolation, lacking the autonomous orchestration required to execute the full discovery process. Here we present ElementsClaw, an agentic framework for materials discovery that synergizes Large Atomic Models (LAMs) with Large Language Models (LLMs). In response to varied human requirements, ElementsClaw dynamically orchestrates a suite of LAM tools finetuned from our proposed model Elements for atomic-scale numerical computation, while leveraging LLMs for high-level semantic reasoning. This shift moves AI-driven materials science from isolated processes toward integrated and human interactive discovery. In the demanding domain of superconductors, our agentic system guides the experimental synthesis of four new superconductors, including Zr3ScRe8 with a transition temperature of 6.8 K and HfZrRe4 at 6.7 K. At scale, ElementsClaw screens more than 2.4 million stable crystals within only 28 GPU hours, identifying 68,000 high-confidence superconducting candidates and vastly expanding the known superconducting space. These results demonstrate how our agent accelerates materials discovery with high physical fidelity.
Qwen3-Coder-Next Technical Report
Feb 28, 2026We present Qwen3-Coder-Next, an open-weight language model specialized for coding agents. Qwen3-Coder-Next is an 80-billion-parameter model that activates only 3 billion parameters during inference, enabling strong coding capability with efficient inference. In this work, we explore how far strong training recipes can push the capability limits of models with small parameter footprints. To achieve this, we perform agentic training through large-scale synthesis of verifiable coding tasks paired with executable environments, allowing learning directly from environment feedback via mid-training and reinforcement learning. Across agent-centric benchmarks including SWE-Bench and Terminal-Bench, Qwen3-Coder-Next achieves competitive performance relative to its active parameter count. We release both base and instruction-tuned open-weight versions to support research and real-world coding agent development.
DMFlow: Disordered Materials Generation by Flow Matching
Feb 04, 2026The design of materials with tailored properties is crucial for technological progress. However, most deep generative models focus exclusively on perfectly ordered crystals, neglecting the important class of disordered materials. To address this gap, we introduce DMFlow, a generative framework specifically designed for disordered crystals. Our approach introduces a unified representation for ordered, Substitutionally Disordered (SD), and Positionally Disordered (PD) crystals, and employs a flow matching model to jointly generate all structural components. A key innovation is a Riemannian flow matching framework with spherical reparameterization, which ensures physically valid disorder weights on the probability simplex. The vector field is learned by a novel Graph Neural Network (GNN) that incorporates physical symmetries and a specialized message-passing scheme. Finally, a two-stage discretization procedure converts the continuous weights into multi-hot atomic assignments. To support research in this area, we release a benchmark containing SD, PD, and mixed structures curated from the Crystallography Open Database. Experiments on Crystal Structure Prediction (CSP) and De Novo Generation (DNG) tasks demonstrate that DMFlow significantly outperforms state-of-the-art baselines adapted from ordered crystal generation. We hope our work provides a foundation for the AI-driven discovery of disordered materials.
SWE-Universe: Scale Real-World Verifiable Environments to Millions
Feb 02, 2026We propose SWE-Universe, a scalable and efficient framework for automatically constructing real-world software engineering (SWE) verifiable environments from GitHub pull requests (PRs). To overcome the prevalent challenges of automatic building, such as low production yield, weak verifiers, and prohibitive cost, our framework utilizes a building agent powered by an efficient custom-trained model. This agent employs iterative self-verification and in-loop hacking detection to ensure the reliable generation of high-fidelity, verifiable tasks. Using this method, we scale the number of real-world multilingual SWE environments to a million scale (807,693). We demonstrate the profound value of our environments through large-scale agentic mid-training and reinforcement learning. Finally, we applied this technique to Qwen3-Max-Thinking and achieved a score of 75.3% on SWE-Bench Verified. Our work provides both a critical resource and a robust methodology to advance the next generation of coding agents.
InfMem: Learning System-2 Memory Control for Long-Context Agent
Feb 02, 2026Reasoning over ultra-long documents requires synthesizing sparse evidence scattered across distant segments under strict memory constraints. While streaming agents enable scalable processing, their passive memory update strategy often fails to preserve low-salience bridging evidence required for multi-hop reasoning. We propose InfMem, a control-centric agent that instantiates System-2-style control via a PreThink-Retrieve-Write protocol. InfMem actively monitors evidence sufficiency, performs targeted in-document retrieval, and applies evidence-aware joint compression to update a bounded memory. To ensure reliable control, we introduce a practical SFT-to-RL training recipe that aligns retrieval, writing, and stopping decisions with end-task correctness. On ultra-long QA benchmarks from 32k to 1M tokens, InfMem consistently outperforms MemAgent across backbones. Specifically, InfMem improves average absolute accuracy by +10.17, +11.84, and +8.23 points on Qwen3-1.7B, Qwen3-4B, and Qwen2.5-7B, respectively, while reducing inference time by $3.9\times$ on average (up to $5.1\times$) via adaptive early stopping.
From Macro to Micro: Benchmarking Microscopic Spatial Intelligence on Molecules via Vision-Language Models
Dec 12, 2025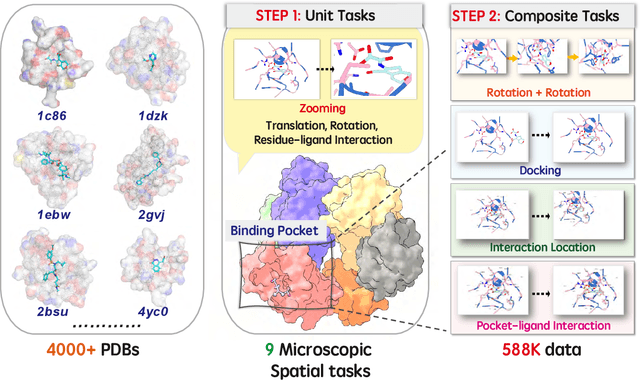
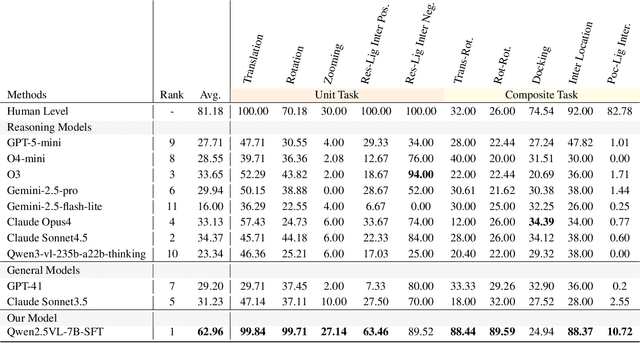
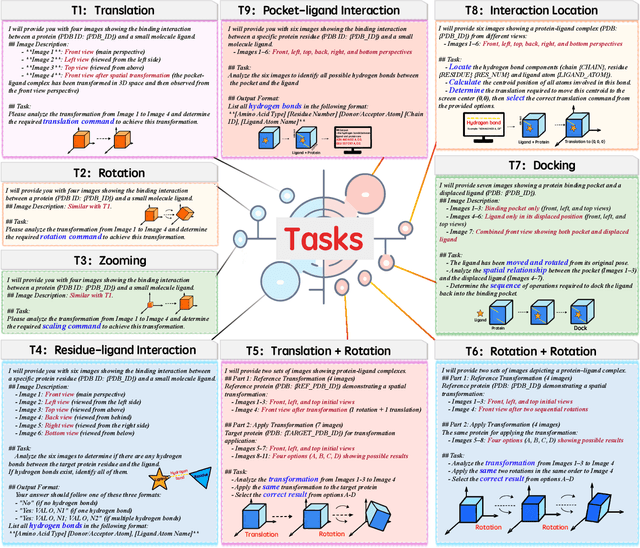
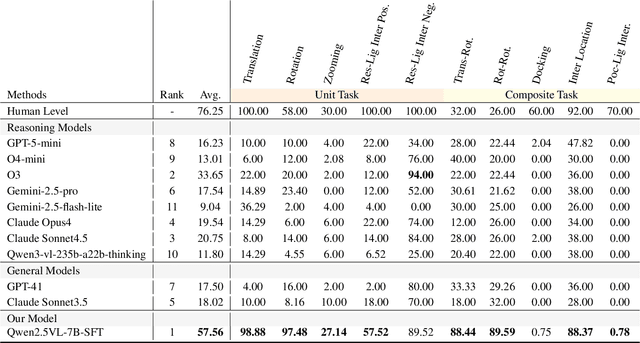
This paper introduces the concept of Microscopic Spatial Intelligence (MiSI), the capability to perceive and reason about the spatial relationships of invisible microscopic entities, which is fundamental to scientific discovery. To assess the potential of Vision-Language Models (VLMs) in this domain, we propose a systematic benchmark framework MiSI-Bench. This framework features over 163,000 question-answer pairs and 587,000 images derived from approximately 4,000 molecular structures, covering nine complementary tasks that evaluate abilities ranging from elementary spatial transformations to complex relational identifications. Experimental results reveal that current state-of-the-art VLMs perform significantly below human level on this benchmark. However, a fine-tuned 7B model demonstrates substantial potential, even surpassing humans in spatial transformation tasks, while its poor performance in scientifically-grounded tasks like hydrogen bond recognition underscores the necessity of integrating explicit domain knowledge for progress toward scientific AGI. The datasets are available at https://huggingface.co/datasets/zongzhao/MiSI-bench.
Group Sequence Policy Optimization
Jul 24, 2025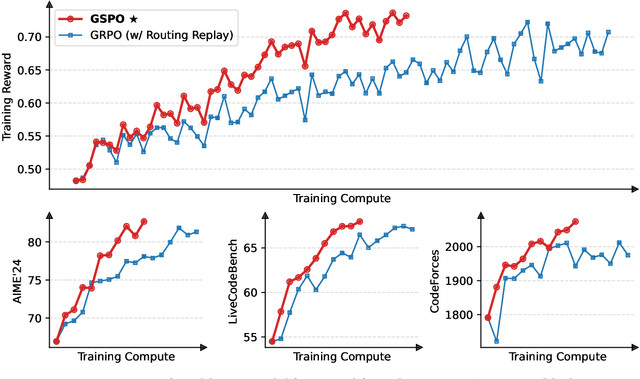
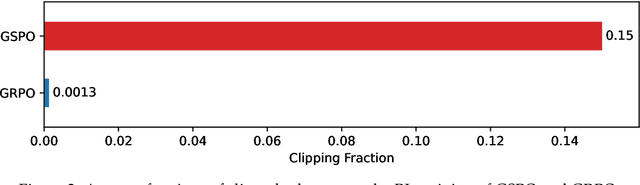
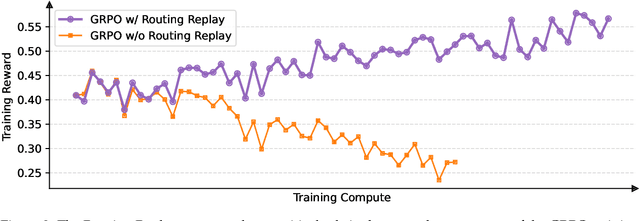
This paper introduces Group Sequence Policy Optimization (GSPO), our stable, efficient, and performant reinforcement learning algorithm for training large language models. Unlike previous algorithms that adopt token-level importance ratios, GSPO defines the importance ratio based on sequence likelihood and performs sequence-level clipping, rewarding, and optimization. We demonstrate that GSPO achieves superior training efficiency and performance compared to the GRPO algorithm, notably stabilizes Mixture-of-Experts (MoE) RL training, and has the potential for simplifying the design of RL infrastructure. These merits of GSPO have contributed to the remarkable improvements in the latest Qwen3 models.
STAR-R1: Spatial TrAnsformation Reasoning by Reinforcing Multimodal LLMs
May 26, 2025Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities across diverse tasks, yet they lag significantly behind humans in spatial reasoning. We investigate this gap through Transformation-Driven Visual Reasoning (TVR), a challenging task requiring identification of object transformations across images under varying viewpoints. While traditional Supervised Fine-Tuning (SFT) fails to generate coherent reasoning paths in cross-view settings, sparse-reward Reinforcement Learning (RL) suffers from inefficient exploration and slow convergence. To address these limitations, we propose STAR-R1, a novel framework that integrates a single-stage RL paradigm with a fine-grained reward mechanism tailored for TVR. Specifically, STAR-R1 rewards partial correctness while penalizing excessive enumeration and passive inaction, enabling efficient exploration and precise reasoning. Comprehensive evaluations demonstrate that STAR-R1 achieves state-of-the-art performance across all 11 metrics, outperforming SFT by 23% in cross-view scenarios. Further analysis reveals STAR-R1's anthropomorphic behavior and highlights its unique ability to compare all objects for improving spatial reasoning. Our work provides critical insights in advancing the research of MLLMs and reasoning models. The codes, model weights, and data will be publicly available at https://github.com/zongzhao23/STAR-R1.