 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Relation Transformer for Contextual Text Block Detection
Jan 17, 2024



Contextual Text Block Detection (CTBD) is the task of identifying coherent text blocks within the complexity of natural scenes. Previous methodologies have treated CTBD as either a visual relation extraction challenge within computer vision or as a sequence modeling problem from the perspective of natural language processing. We introduce a new framework that frames CTBD as a graph generation problem. This methodology consists of two essential procedures: identifying individual text units as graph nodes and discerning the sequential reading order relationships among these units as graph edges. Leveraging the cutting-edge capabilities of DQ-DETR for node detection, our framework innovates further by integrating a novel mechanism, a Dynamic Relation Transformer (DRFormer), dedicated to edge generation. DRFormer incorporates a dual interactive transformer decoder that deftly manages a dynamic graph structure refinement process. Through this iterative process, the model systematically enhances the graph's fidelity, ultimately resulting in improved precision in detecting contextual text blocks. Comprehensive experimental evaluations conducted on both SCUT-CTW-Context and ReCTS-Context datasets substantiate that our method achieves state-of-the-art results, underscoring the effectiveness and potential of our graph generation framework in advancing the field of CTBD.
Robust Table Structure Recognition with Dynamic Queries Enhanced Detection Transformer
Mar 21, 2023



We present a new table structure recognition (TSR) approach, called TSRFormer, to robustly recognizing the structures of complex tables with geometrical distortions from various table images. Unlike previous methods, we formulate table separation line prediction as a line regression problem instead of an image segmentation problem and propose a new two-stage dynamic queries enhanced DETR based separation line regression approach, named DQ-DETR, to predict separation lines from table images directly. Compared to Vallina DETR, we propose three improvements in DQ-DETR to make the two-stage DETR framework work efficiently and effectively for the separation line prediction task: 1) A new query design, named Dynamic Query, to decouple single line query into separable point queries which could intuitively improve the localization accuracy for regression tasks; 2) A dynamic queries based progressive line regression approach to progressively regressing points on the line which further enhances localization accuracy for distorted tables; 3) A prior-enhanced matching strategy to solve the slow convergence issue of DETR. After separation line prediction, a simple relation network based cell merging module is used to recover spanning cells. With these new techniques, our TSRFormer achieves state-of-the-art performance on several benchmark datasets, including SciTSR, PubTabNet, WTW and FinTabNet. Furthermore, we have validated the robustness and high localization accuracy of our approach to tables with complex structures, borderless cells, large blank spaces, empty or spanning cells as well as distorted or even curved shapes on a more challenging real-world in-house dataset.
TSRFormer: Table Structure Recognition with Transformers
Aug 09, 2022
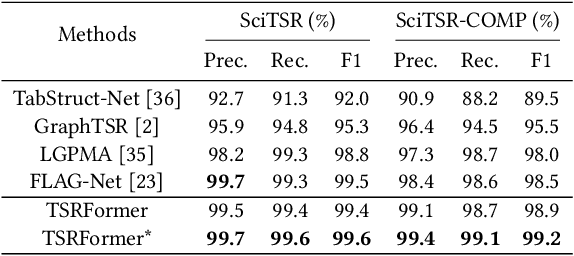
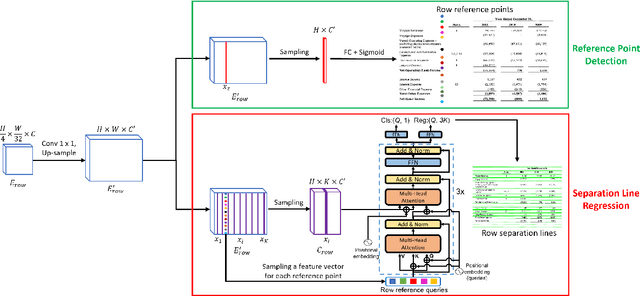
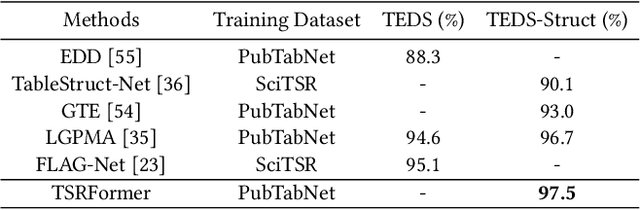
We present a new table structure recognition (TSR) approach, called TSRFormer, to robustly recognizing the structures of complex tables with geometrical distortions from various table images. Unlike previous methods, we formulate table separation line prediction as a line regression problem instead of an image segmentation problem and propose a new two-stage DETR based separator prediction approach, dubbed \textbf{Sep}arator \textbf{RE}gression \textbf{TR}ansformer (SepRETR), to predict separation lines from table images directly. To make the two-stage DETR framework work efficiently and effectively for the separation line prediction task, we propose two improvements: 1) A prior-enhanced matching strategy to solve the slow convergence issue of DETR; 2) A new cross attention module to sample features from a high-resolution convolutional feature map directly so that high localization accuracy is achieved with low computational cost. After separation line prediction, a simple relation network based cell merging module is used to recover spanning cells. With these new techniques, our TSRFormer achieves state-of-the-art performance on several benchmark datasets, including SciTSR, PubTabNet and WTW. Furthermore, we have validated the robustness of our approach to tables with complex structures, borderless cells, large blank spaces, empty or spanning cells as well as distorted or even curved shapes on a more challenging real-world in-house dataset.
Robust Table Detection and Structure Recognition from Heterogeneous Document Images
Mar 17, 2022



We introduce a new table detection and structure recognition approach named RobusTabNet to detect the boundaries of tables and reconstruct the cellular structure of the table from heterogeneous document images. For table detection, we propose to use CornerNet as a new region proposal network to generate higher quality table proposals for Faster R-CNN, which has significantly improved the localization accuracy of Faster R-CNN for table detection. Consequently, our table detection approach achieves state-of-the-art performance on three public table detection benchmarks, namely cTDaR TrackA, PubLayNet and IIIT-AR-13K, by only using a lightweight ResNet-18 backbone network. Furthermore, we propose a new split-and-merge based table structure recognition approach, in which a novel spatial CNN based separation line prediction module is proposed to split each detected table into a grid of cells, and a Grid CNN based cell merging module is applied to recover the spanning cells. As the spatial CNN module can effectively propagate contextual information across the whole table image, our table structure recognizer can robustly recognize tables with large blank spaces and geometrically distorted (even curved) tables. Thanks to these two techniques, our table structure recognition approach achieves state-of-the-art performance on three public benchmarks, including SciTSR, PubTabNet and cTDaR TrackB. Moreover, we have further demonstrated the advantages of our approach in recognizing tables with complex structures, large blank spaces, empty or spanning cells as well as geometrically distorted or even curved tables on a more challenging in-house dataset.
ReLaText: Exploiting Visual Relationships for Arbitrary-Shaped Scene Text Detection with Graph Convolutional Networks
Mar 16, 2020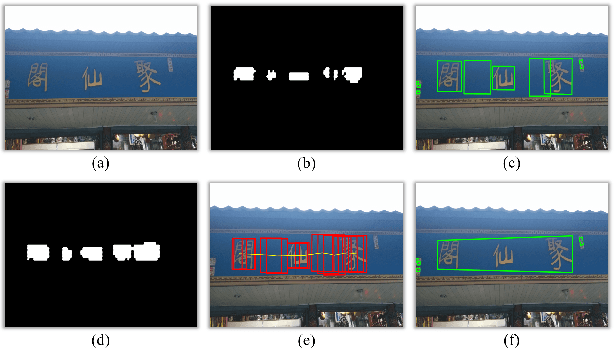
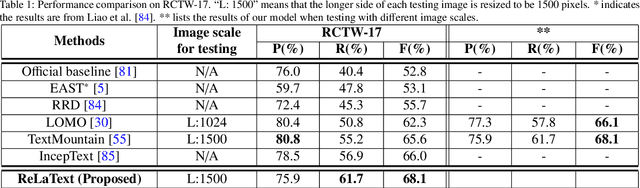
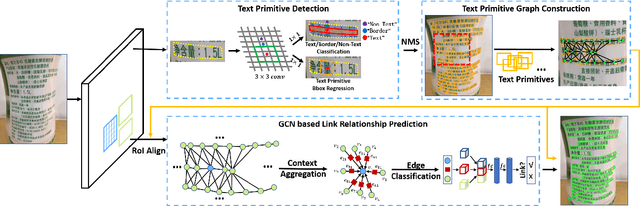
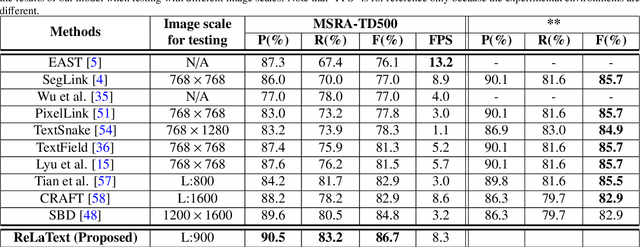
We introduce a new arbitrary-shaped text detection approach named ReLaText by formulating text detection as a visual relationship detection problem. To demonstrate the effectiveness of this new formulation, we start from using a "link" relationship to address the challenging text-line grouping problem firstly. The key idea is to decompose text detection into two subproblems, namely detection of text primitives and prediction of link relationships between nearby text primitive pairs. Specifically, an anchor-free region proposal network based text detector is first used to detect text primitives of different scales from different feature maps of a feature pyramid network, from which a text primitive graph is constructed by linking each pair of nearby text primitives detected from a same feature map with an edge. Then, a Graph Convolutional Network (GCN) based link relationship prediction module is used to prune wrongly-linked edges in the text primitive graph to generate a number of disjoint subgraphs, each representing a detected text instance. As GCN can effectively leverage context information to improve link prediction accuracy, our GCN based text-line grouping approach can achieve better text detection accuracy than previous text-line grouping methods, especially when dealing with text instances with large inter-character or very small inter-line spacings. Consequently, the proposed ReLaText achieves state-of-the-art performance on five public text detection benchmarks, namely RCTW-17, MSRA-TD500, Total-Text, CTW1500 and DAST1500.