 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Large Model Training through Overlapped Activation Recomputation
Jun 13, 2024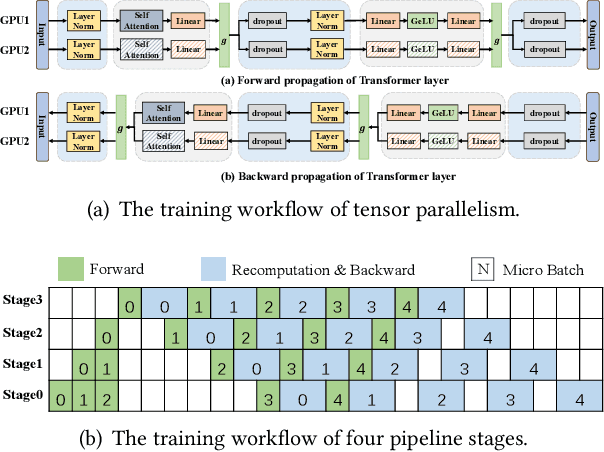
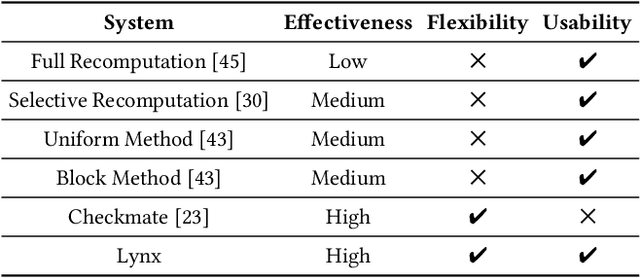
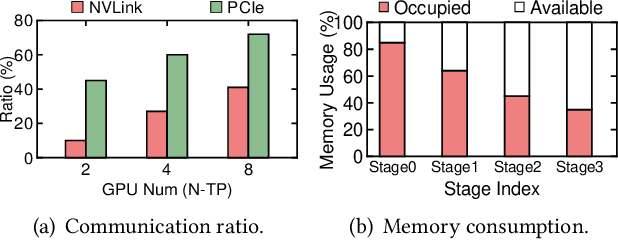
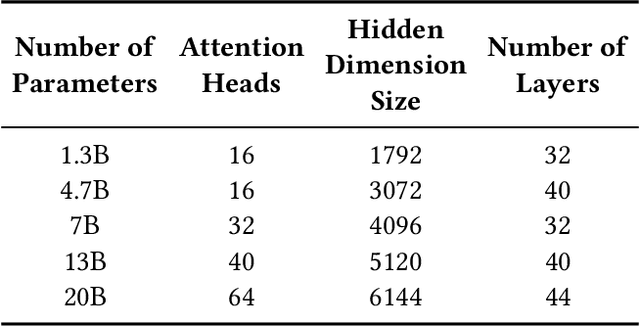
Large model training has been using recomputation to alleviate the memory pressure and pipelining to exploit the parallelism of data, tensor, and devices. The existing recomputation approaches may incur up to 40% overhead when training real-world models, e.g., the GPT model with 22B parameters. This is because they are executed on demand in the critical training path. In this paper, we design a new recomputation framework, Lynx, to reduce the overhead by overlapping the recomputation with communication occurring in training pipelines. It consists of an optimal scheduling algorithm (OPT) and a heuristic-based scheduling algorithm (HEU). OPT achieves a global optimum but suffers from a long search time. HEU was designed based on our observation that there are identical structures in large DNN models so that we can apply the same scheduling policy to all identical structures. HEU achieves a local optimum but reduces the search time by 99% compared to OPT. Our comprehensive evaluation using GPT models with 1.3B-20B parameters shows that both OPT and HEU outperform the state-of-the-art recomputation approaches (e.g., Megatron-LM and Checkmake) by 1.02-1.53x. HEU achieves a similar performance as OPT with a search time of 0.16s on average.
Adapprox: Adaptive Approximation in Adam Optimization via Randomized Low-Rank Matrices
Mar 22, 2024As deep learning models exponentially increase in size, optimizers such as Adam encounter significant memory consumption challenges due to the storage of first and second moment data. Current memory-efficient methods like Adafactor and CAME often compromise accuracy with their matrix factorization techniques. Addressing this, we introduce Adapprox, a novel approach that employs randomized low-rank matrix approximation for a more effective and accurate approximation of Adam's second moment. Adapprox features an adaptive rank selection mechanism, finely balancing accuracy and memory efficiency, and includes an optional cosine similarity guidance strategy to enhance stability and expedite convergence. In GPT-2 training and downstream tasks, Adapprox surpasses AdamW by achieving 34.5% to 49.9% and 33.8% to 49.9% memory savings for the 117M and 345M models, respectively, with the first moment enabled, and further increases these savings without the first moment. Besides, it enhances convergence speed and improves downstream task performance relative to its counterparts.
A Survey on Arabic Named Entity Recognition: Past, Recent Advances, and Future Trends
Feb 08, 2023



As more and more Arabic texts emerged on the Internet, extracting important information from these Arabic texts is especially useful. As a fundamental technology, Named entity recognition (NER) serves as the core component in information extraction technology, while also playing a critical role in many other Natural Language Processing (NLP) systems, such as question answering and knowledge graph building. In this paper, we provide a comprehensive review of the development of Arabic NER, especially the recent advances in deep learning and pre-trained language model. Specifically, we first introduce the background of Arabic NER, including the characteristics of Arabic and existing resources for Arabic NER. Then, we systematically review the development of Arabic NER methods. Traditional Arabic NER systems focus on feature engineering and designing domain-specific rules. In recent years, deep learning methods achieve significant progress by representing texts via continuous vector representations. With the growth of pre-trained language model, Arabic NER yields better performance. Finally, we conclude the method gap between Arabic NER and NER methods from other languages, which helps outline future directions for Arabic NER.
Delving Deep into Regularity: A Simple but Effective Method for Chinese Named Entity Recognition
Apr 18, 2022
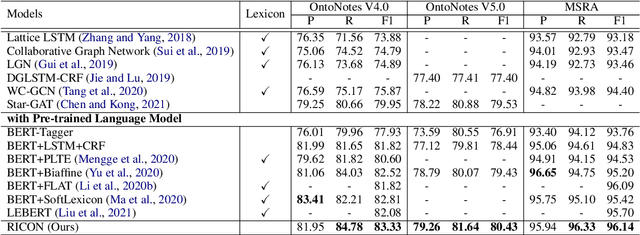
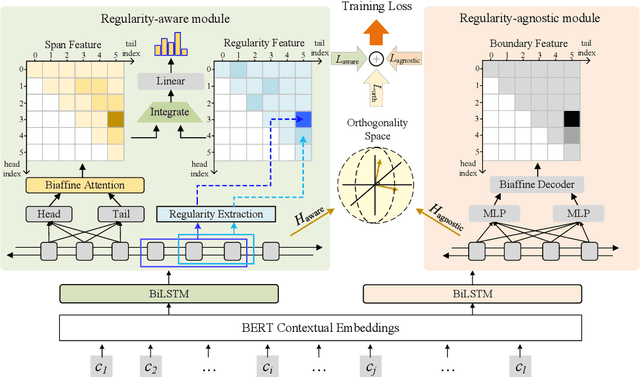
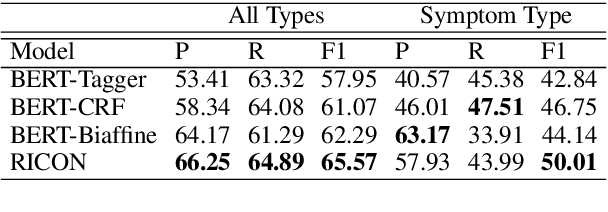
Recent years have witnessed the improving performance of Chinese Named Entity Recognition (NER) from proposing new frameworks or incorporating word lexicons. However, the inner composition of entity mentions in character-level Chinese NER has been rarely studied. Actually, most mentions of regular types have strong name regularity. For example, entities end with indicator words such as "company" or "bank" usually belong to organization. In this paper, we propose a simple but effective method for investigating the regularity of entity spans in Chinese NER, dubbed as Regularity-Inspired reCOgnition Network (RICON). Specifically, the proposed model consists of two branches: a regularity-aware module and a regularityagnostic module. The regularity-aware module captures the internal regularity of each span for better entity type prediction, while the regularity-agnostic module is employed to locate the boundary of entities and relieve the excessive attention to span regularity. An orthogonality space is further constructed to encourage two modules to extract different aspects of regularity features. To verify the effectiveness of our method, we conduct extensive experiments on three benchmark datasets and a practical medical dataset. The experimental results show that our RICON significantly outperforms previous state-of-the-art methods, including various lexicon-based methods.
Read, Retrospect, Select: An MRC Framework to Short Text Entity Linking
Jan 07, 2021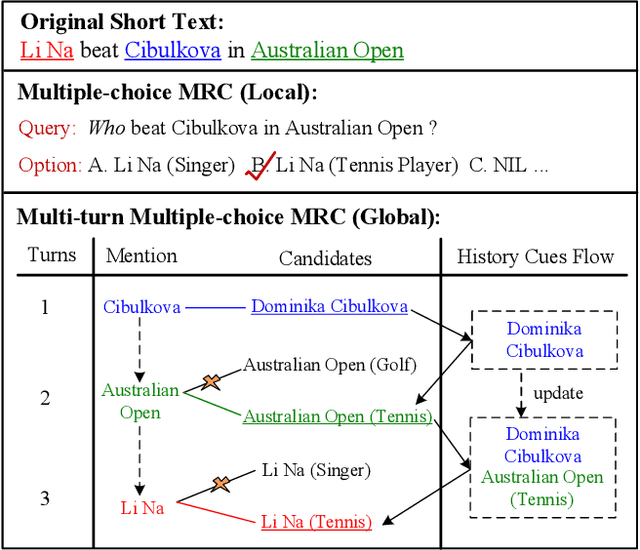
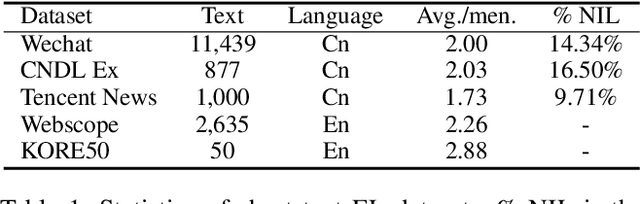
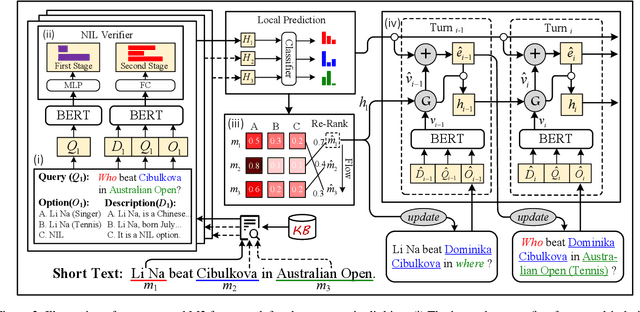
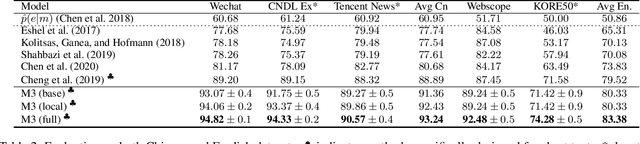
Entity linking (EL) for the rapidly growing short text (e.g. search queries and news titles) is critical to industrial applications. Most existing approaches relying on adequate context for long text EL are not effective for the concise and sparse short text. In this paper, we propose a novel framework called Multi-turn Multiple-choice Machine reading comprehension (M3}) to solve the short text EL from a new perspective: a query is generated for each ambiguous mention exploiting its surrounding context, and an option selection module is employed to identify the golden entity from candidates using the query. In this way, M3 framework sufficiently interacts limited context with candidate entities during the encoding process, as well as implicitly considers the dissimilarities inside the candidate bunch in the selection stage. In addition, we design a two-stage verifier incorporated into M3 to address the commonly existed unlinkable problem in short text. To further consider the topical coherence and interdependence among referred entities, M3 leverages a multi-turn fashion to deal with mentions in a sequence manner by retrospecting historical cues. Evaluation shows that our M3 framework achieves the state-of-the-art performance on five Chinese and English datasets for the real-world short text EL.