 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Multi-Index Semantic Hashing
Mar 26, 2021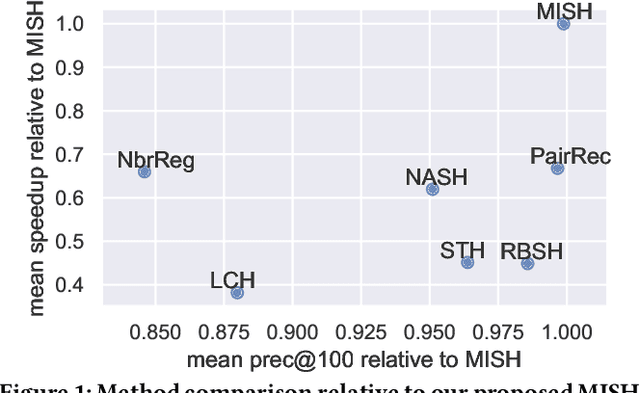

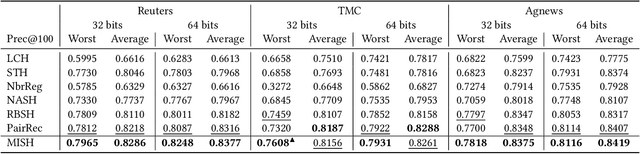
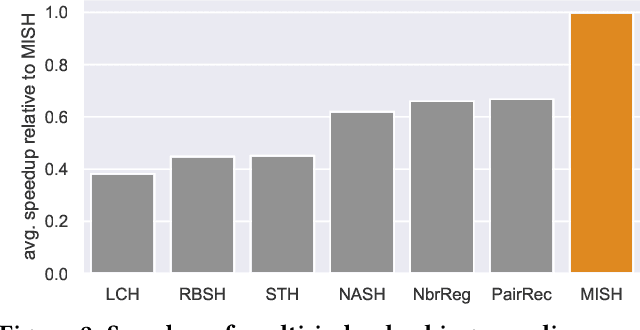
Semantic hashing represents documents as compact binary vectors (hash codes) and allows both efficient and effective similarity search in large-scale information retrieval. The state of the art has primarily focused on learning hash codes that improve similarity search effectiveness, while assuming a brute-force linear scan strategy for searching over all the hash codes, even though much faster alternatives exist. One such alternative is multi-index hashing, an approach that constructs a smaller candidate set to search over, which depending on the distribution of the hash codes can lead to sub-linear search time. In this work, we propose Multi-Index Semantic Hashing (MISH), an unsupervised hashing model that learns hash codes that are both effective and highly efficient by being optimized for multi-index hashing. We derive novel training objectives, which enable to learn hash codes that reduce the candidate sets produced by multi-index hashing, while being end-to-end trainable. In fact, our proposed training objectives are model agnostic, i.e., not tied to how the hash codes are generated specifically in MISH, and are straight-forward to include in existing and future semantic hashing models. We experimentally compare MISH to state-of-the-art semantic hashing baselines in the task of document similarity search. We find that even though multi-index hashing also improves the efficiency of the baselines compared to a linear scan, they are still upwards of 33% slower than MISH, while MISH is still able to obtain state-of-the-art effectiveness.
Unsupervised Semantic Hashing with Pairwise Reconstruction
Jul 01, 2020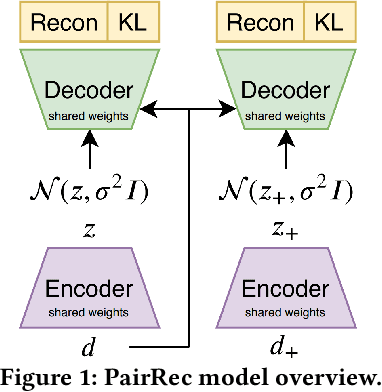
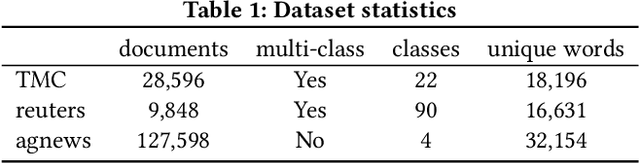
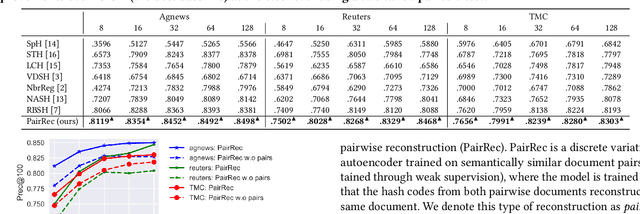
Semantic Hashing is a popular family of methods for efficient similarity search in large-scale datasets. In Semantic Hashing, documents are encoded as short binary vectors (i.e., hash codes), such that semantic similarity can be efficiently computed using the Hamming distance. Recent state-of-the-art approaches have utilized weak supervision to train better performing hashing models. Inspired by this, we present Semantic Hashing with Pairwise Reconstruction (PairRec), which is a discrete variational autoencoder based hashing model. PairRec first encodes weakly supervised training pairs (a query document and a semantically similar document) into two hash codes, and then learns to reconstruct the same query document from both of these hash codes (i.e., pairwise reconstruction). This pairwise reconstruction enables our model to encode local neighbourhood structures within the hash code directly through the decoder. We experimentally compare PairRec to traditional and state-of-the-art approaches, and obtain significant performance improvements in the task of document similarity search.
Tracking Behavioral Patterns among Students in an Online Educational System
Aug 21, 2019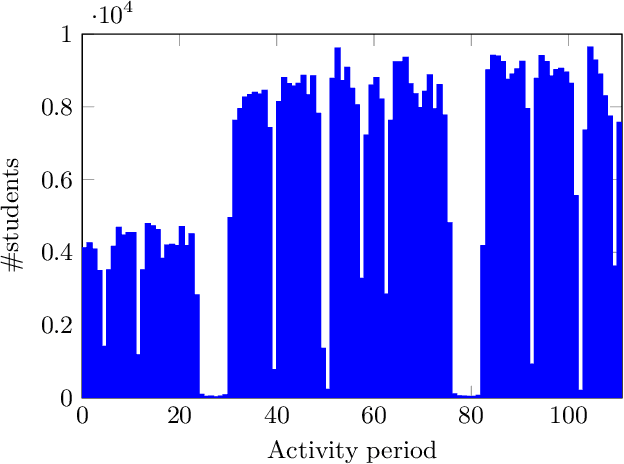
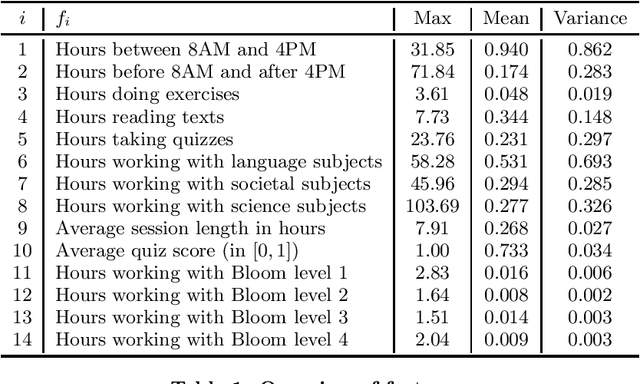
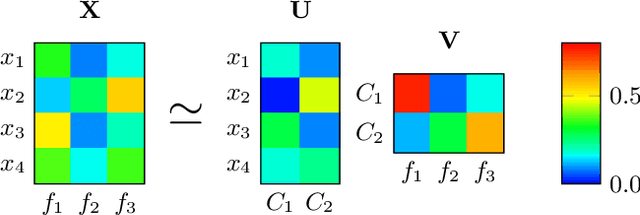
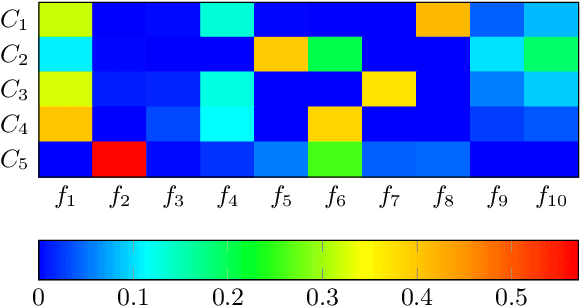
Analysis of log data generated by online educational systems is an essential task to better the educational systems and increase our understanding of how students learn. In this study we investigate previously unseen data from Clio Online, the largest provider of digital learning content for primary schools in Denmark. We consider data for 14,810 students with 3 million sessions in the period 2015-2017. We analyze student activity in periods of one week. By using non-negative matrix factorization techniques, we obtain soft clusterings, revealing dependencies among time of day, subject, activity type, activity complexity (measured by Bloom's taxonomy), and performance. Furthermore, our method allows for tracking behavioral changes of individual students over time, as well as general behavioral changes in the educational system. Based on the results, we give suggestions for behavioral changes, in order to optimize the learning experience and improve performance.
Investigating Writing Style Development in High School
Jun 04, 2019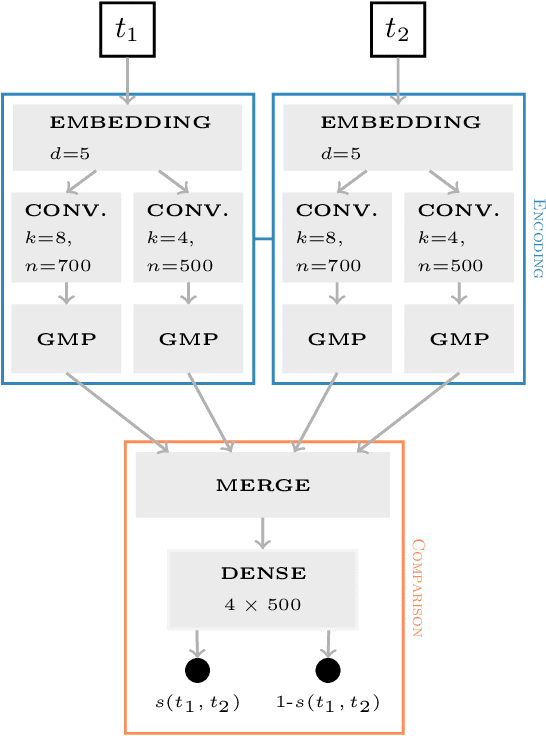
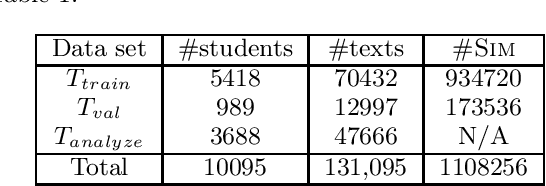
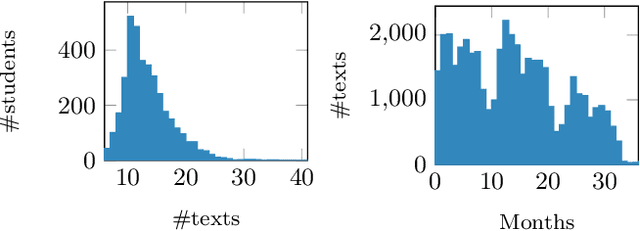
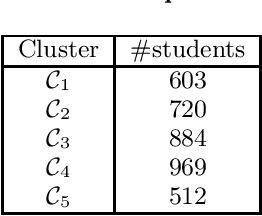
In this paper we do the first large scale analysis of writing style development among Danish high school students. More than 10K students with more than 100K essays are analyzed. Writing style itself is often studied in the natural language processing community, but usually with the goal of verifying authorship, assessing quality or popularity, or other kinds of predictions. In this work, we analyze writing style changes over time, with the goal of detecting global development trends among students, and identifying at-risk students. We train a Siamese neural network to compute the similarity between two texts. Using this similarity measure, a student's newer essays are compared to their first essays, and a writing style development profile is constructed for the student. We cluster these student profiles and analyze the resulting clusters in order to detect general development patterns. We evaluate clusters with respect to writing style quality indicators, and identify optimal clusters, showing significant improvement in writing style, while also observing suboptimal clusters, exhibiting periods of limited development and even setbacks. Furthermore, we identify general development trends between high school students, showing that as students progress through high school, their writing style deviates, leaving students less similar when they finish high school, than when they start.
Detecting Ghostwriters in High Schools
Jun 04, 2019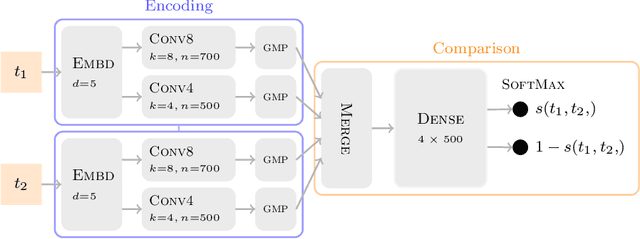
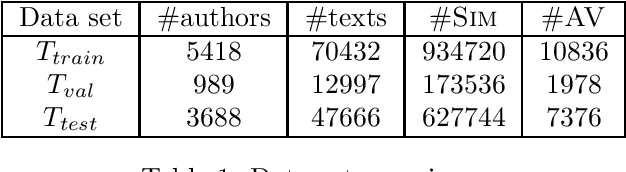
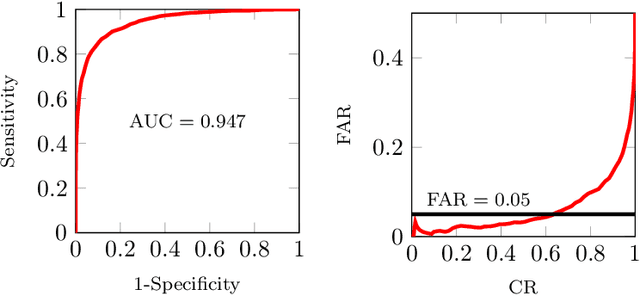
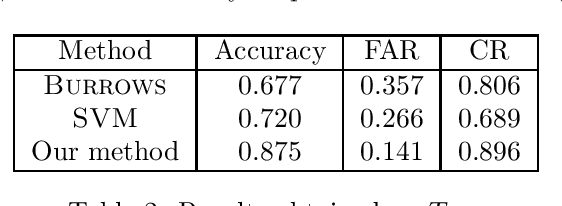
Students hiring ghostwriters to write their assignments is an increasing problem in educational institutions all over the world, with companies selling these services as a product. In this work, we develop automatic techniques with special focus on detecting such ghostwriting in high school assignments. This is done by training deep neural networks on an unprecedented large amount of data supplied by the Danish company MaCom, which covers 90% of Danish high schools. We achieve an accuracy of 0.875 and a AUC score of 0.947 on an evenly split data set.
* Presented at ESANN 2019
Contextually Propagated Term Weights for Document Representation
Jun 03, 2019
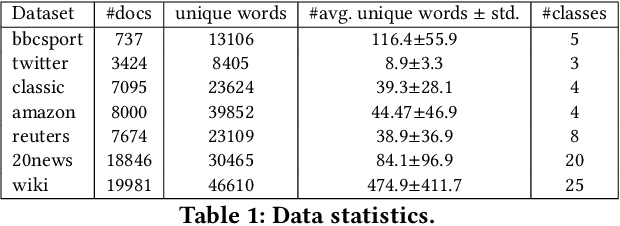
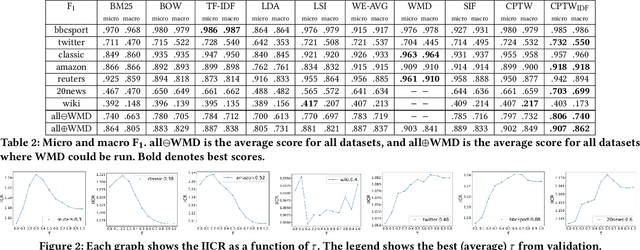
Word embeddings predict a word from its neighbours by learning small, dense embedding vectors. In practice, this prediction corresponds to a semantic score given to the predicted word (or term weight). We present a novel model that, given a target word, redistributes part of that word's weight (that has been computed with word embeddings) across words occurring in similar contexts as the target word. Thus, our model aims to simulate how semantic meaning is shared by words occurring in similar contexts, which is incorporated into bag-of-words document representations. Experimental evaluation in an unsupervised setting against 8 state of the art baselines shows that our model yields the best micro and macro F1 scores across datasets of increasing difficulty.
Unsupervised Neural Generative Semantic Hashing
Jun 03, 2019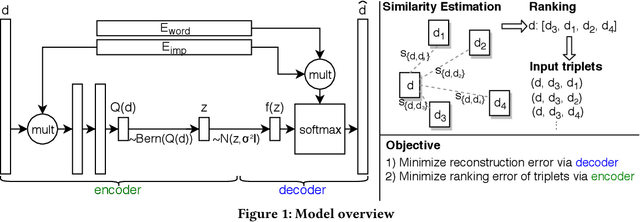
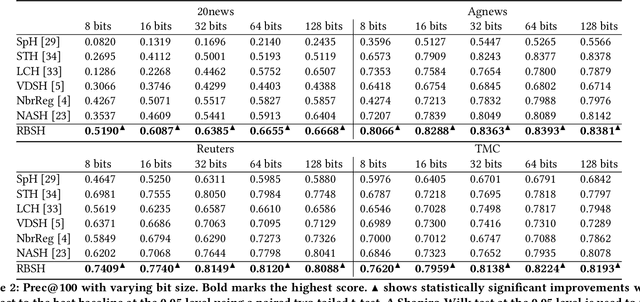
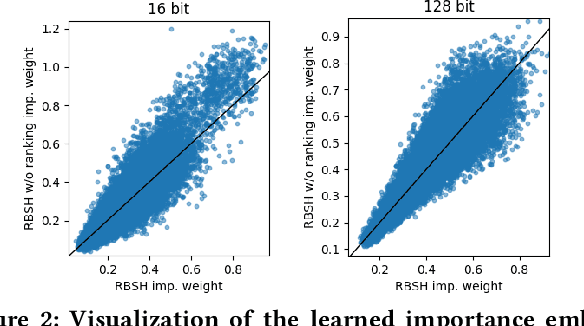
Fast similarity search is a key component in large-scale information retrieval, where semantic hashing has become a popular strategy for representing documents as binary hash codes. Recent advances in this area have been obtained through neural network based models: generative models trained by learning to reconstruct the original documents. We present a novel unsupervised generative semantic hashing approach, \textit{Ranking based Semantic Hashing} (RBSH) that consists of both a variational and a ranking based component. Similarly to variational autoencoders, the variational component is trained to reconstruct the original document conditioned on its generated hash code, and as in prior work, it only considers documents individually. The ranking component solves this limitation by incorporating inter-document similarity into the hash code generation, modelling document ranking through a hinge loss. To circumvent the need for labelled data to compute the hinge loss, we use a weak labeller and thus keep the approach fully unsupervised. Extensive experimental evaluation on four publicly available datasets against traditional baselines and recent state-of-the-art methods for semantic hashing shows that RBSH significantly outperforms all other methods across all evaluated hash code lengths. In fact, RBSH hash codes are able to perform similarly to state-of-the-art hash codes while using 2-4x fewer bits.
Neural Speed Reading with Structural-Jump-LSTM
Apr 02, 2019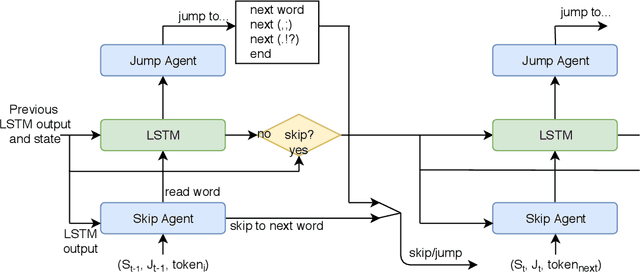


Recurrent neural networks (RNNs) can model natural language by sequentially 'reading' input tokens and outputting a distributed representation of each token. Due to the sequential nature of RNNs, inference time is linearly dependent on the input length, and all inputs are read regardless of their importance. Efforts to speed up this inference, known as 'neural speed reading', either ignore or skim over part of the input. We present Structural-Jump-LSTM: the first neural speed reading model to both skip and jump text during inference. The model consists of a standard LSTM and two agents: one capable of skipping single words when reading, and one capable of exploiting punctuation structure (sub-sentence separators (,:), sentence end symbols (.!?), or end of text markers) to jump ahead after reading a word. A comprehensive experimental evaluation of our model against all five state-of-the-art neural reading models shows that Structural-Jump-LSTM achieves the best overall floating point operations (FLOP) reduction (hence is faster), while keeping the same accuracy or even improving it compared to a vanilla LSTM that reads the whole text.
* 10 pages
Modelling Sequential Music Track Skips using a Multi-RNN Approach
Mar 20, 2019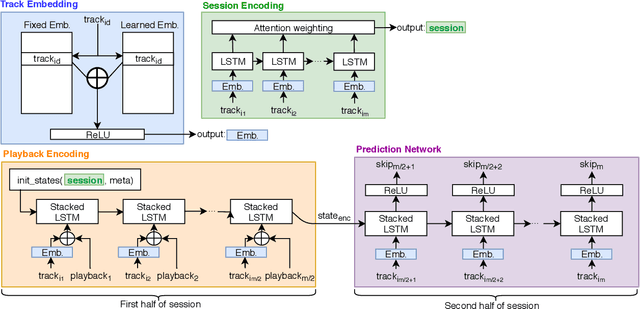
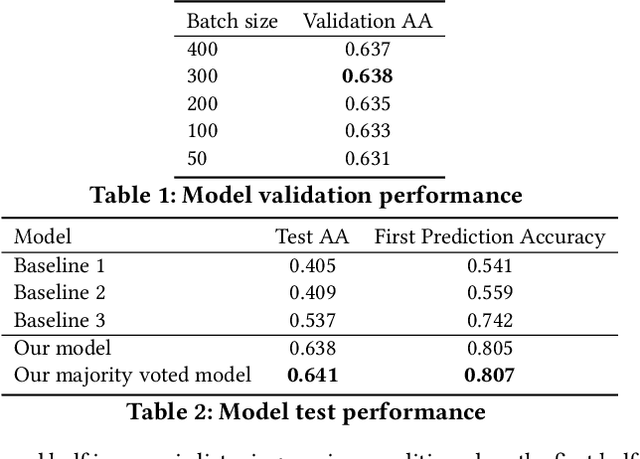
Modelling sequential music skips provides streaming companies the ability to better understand the needs of the user base, resulting in a better user experience by reducing the need to manually skip certain music tracks. This paper describes the solution of the University of Copenhagen DIKU-IR team in the 'Spotify Sequential Skip Prediction Challenge', where the task was to predict the skip behaviour of the second half in a music listening session conditioned on the first half. We model this task using a Multi-RNN approach consisting of two distinct stacked recurrent neural networks, where one network focuses on encoding the first half of the session and the other network focuses on utilizing the encoding to make sequential skip predictions. The encoder network is initialized by a learned session-wide music encoding, and both of them utilize a learned track embedding. Our final model consists of a majority voted ensemble of individually trained models, and ranked 2nd out of 45 participating teams in the competition with a mean average accuracy of 0.641 and an accuracy on the first skip prediction of 0.807. Our code is released at https://github.com/Varyn/WSDM-challenge-2019-spotify.
* 4 pages
Neural Check-Worthiness Ranking with Weak Supervision: Finding Sentences for Fact-Checking
Mar 20, 2019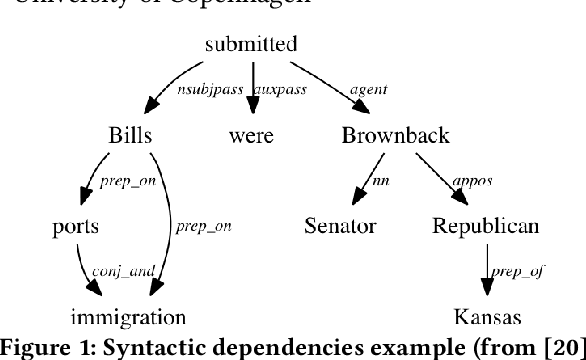
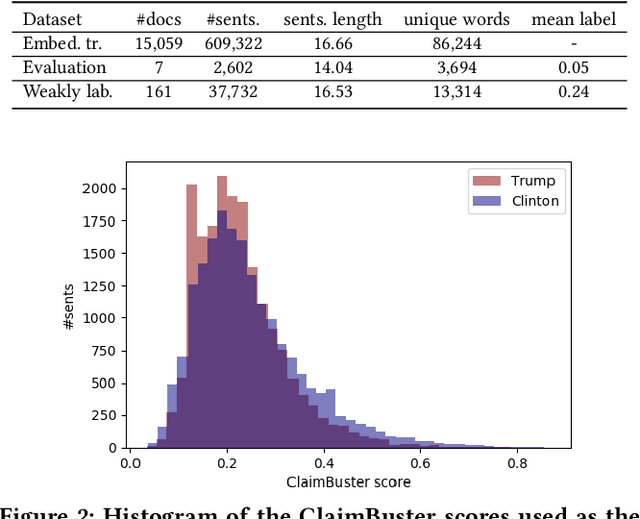
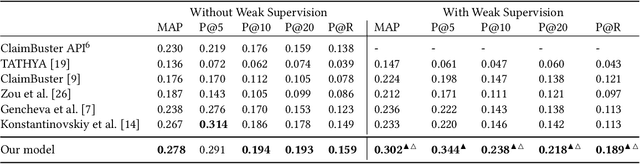
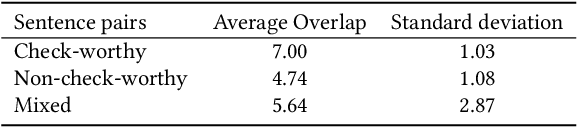
Automatic fact-checking systems detect misinformation, such as fake news, by (i) selecting check-worthy sentences for fact-checking, (ii) gathering related information to the sentences, and (iii) inferring the factuality of the sentences. Most prior research on (i) uses hand-crafted features to select check-worthy sentences, and does not explicitly account for the recent finding that the top weighted terms in both check-worthy and non-check-worthy sentences are actually overlapping [15]. Motivated by this, we present a neural check-worthiness sentence ranking model that represents each word in a sentence by \textit{both} its embedding (aiming to capture its semantics) and its syntactic dependencies (aiming to capture its role in modifying the semantics of other terms in the sentence). Our model is an end-to-end trainable neural network for check-worthiness ranking, which is trained on large amounts of unlabelled data through weak supervision. Thorough experimental evaluation against state of the art baselines, with and without weak supervision, shows our model to be superior at all times (+13% in MAP and +28% at various Precision cut-offs from the best baseline with statistical significance). Empirical analysis of the use of weak supervision, word embedding pretraining on domain-specific data, and the use of syntactic dependencies of our model reveals that check-worthy sentences contain notably more identical syntactic dependencies than non-check-worthy sentences.
* 6 pages