 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextually Propagated Term Weights for Document Representation
Paper and Code

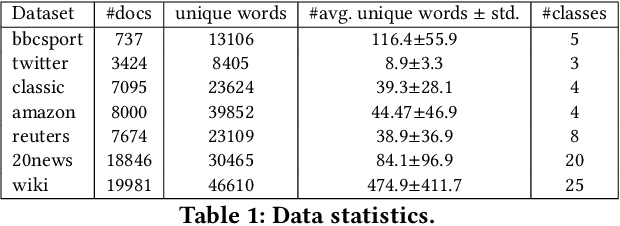
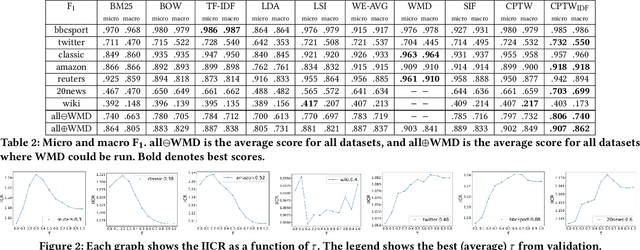
Word embeddings predict a word from its neighbours by learning small, dense embedding vectors. In practice, this prediction corresponds to a semantic score given to the predicted word (or term weight). We present a novel model that, given a target word, redistributes part of that word's weight (that has been computed with word embeddings) across words occurring in similar contexts as the target word. Thus, our model aims to simulate how semantic meaning is shared by words occurring in similar contexts, which is incorporated into bag-of-words document representations. Experimental evaluation in an unsupervised setting against 8 state of the art baselines shows that our model yields the best micro and macro F1 scores across datasets of increasing difficulty.