 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormalized Information Needs Improve Large-Language-Model Relevance Judgments
Apr 05, 2026Cranfield-style retrieval evaluations with too few or too many relevant documents or with low inter-assessor agreement on relevance can reduce the reliability of observations. In evaluations with human assessors, information needs are often formalized as retrieval topics to avoid an excessive number of relevant documents while maintaining good agreement. However, emerging evaluation setups that use Large Language Models (LLMs) as relevance assessors often use only queries, potentially decreasing the reliability. To study whether LLM relevance assessors benefit from formalized information needs, we synthetically formalize information needs with LLMs into topics that follow the established structure from previous human relevance assessments (i.e., descriptions and narratives). We compare assessors using synthetically formalized topics against the LLM-default query-only assessor on Robust04 and the 2019/2020 editions of TREC Deep Learning. We find that assessors without formalization judge many more documents relevant and have a lower agreement, leading to reduced reliability in retrieval evaluations. Furthermore, we show that the formalized topics improve agreement between human and LLM relevance judgments, even when the topics are not highly similar to their human counterparts. Our findings indicate that LLM relevance assessors should use formalized information needs, as is standard for human assessment, and synthetically formalize topics when no human formalization exists to improve evaluation reliability.
Denmark's Participation in the Search Engine TREC COVID-19 Challenge: Lessons Learned about Searching for Precise Biomedical Scientific Information on COVID-19
Nov 26, 2020
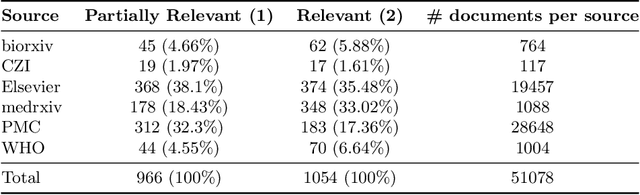
This report describes the participation of two Danish universities, University of Copenhagen and Aalborg University, in the international search engine competition on COVID-19 (the 2020 TREC-COVID Challenge) organised by the U.S. National Institute of Standards and Technology (NIST) and its Text Retrieval Conference (TREC) division. The aim of the competition was to find the best search engine strategy for retrieving precise biomedical scientific information on COVID-19 from the largest, at that point in time, dataset of curated scientific literature on COVID-19 -- the COVID-19 Open Research Dataset (CORD-19). CORD-19 was the result of a call to action to the tech community by the U.S. White House in March 2020, and was shortly thereafter posted on Kaggle as an AI competition by the Allen Institute for AI, the Chan Zuckerberg Initiative, Georgetown University's Center for Security and Emerging Technology, Microsoft, and the National Library of Medicine at the US National Institutes of Health. CORD-19 contained over 200,000 scholarly articles (of which more than 100,000 were with full text) about COVID-19, SARS-CoV-2, and related coronaviruses, gathered from curated biomedical sources. The TREC-COVID challenge asked for the best way to (a) retrieve accurate and precise scientific information, in response to some queries formulated by biomedical experts, and (b) rank this information decreasingly by its relevance to the query. In this document, we describe the TREC-COVID competition setup, our participation to it, and our resulting reflections and lessons learned about the state-of-art technology when faced with the acute task of retrieving precise scientific information from a rapidly growing corpus of literature, in response to highly specialised queries, in the middle of a pandemic.
Rhetorical relations for information retrieval
Apr 05, 2017

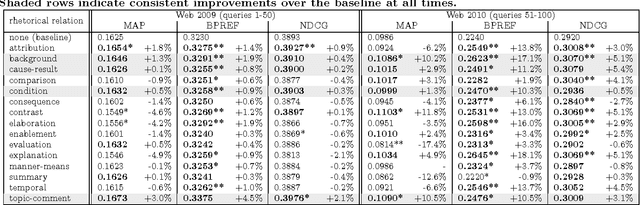
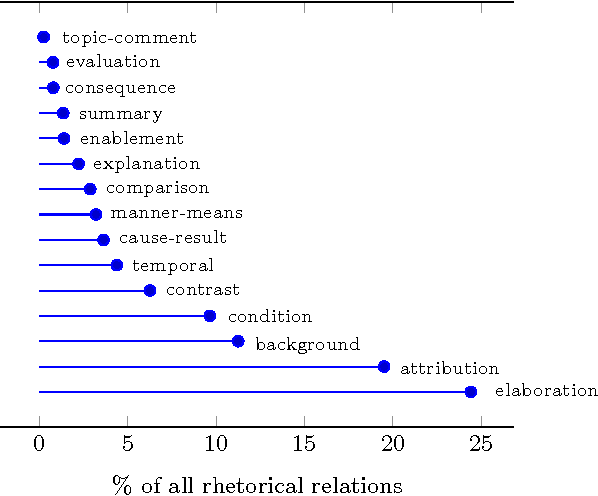
Typically, every part in most coherent text has some plausible reason for its presence, some function that it performs to the overall semantics of the text. Rhetorical relations, e.g. contrast, cause, explanation, describe how the parts of a text are linked to each other. Knowledge about this socalled discourse structure has been applied successfully to several natural language processing tasks. This work studies the use of rhetorical relations for Information Retrieval (IR): Is there a correlation between certain rhetorical relations and retrieval performance? Can knowledge about a document's rhetorical relations be useful to IR? We present a language model modification that considers rhetorical relations when estimating the relevance of a document to a query. Empirical evaluation of different versions of our model on TREC settings shows that certain rhetorical relations can benefit retrieval effectiveness notably (> 10% in mean average precision over a state-of-the-art baseline).