 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFact Checking with Insufficient Evidence
Paper and Code
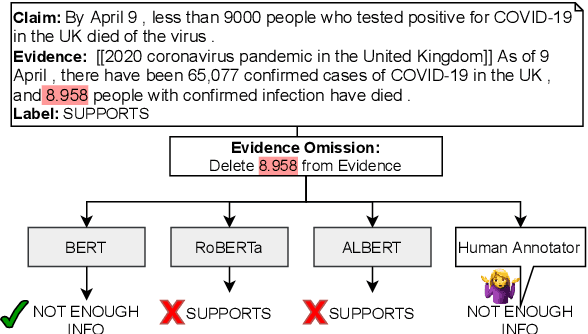



Automating the fact checking (FC) process relies on information obtained from external sources. In this work, we posit that it is crucial for FC models to make veracity predictions only when there is sufficient evidence and otherwise indicate when it is not enough. To this end, we are the first to study what information FC models consider sufficient by introducing a novel task and advancing it with three main contributions. First, we conduct an in-depth empirical analysis of the task with a new fluency-preserving method for omitting information from the evidence at the constituent and sentence level. We identify when models consider the remaining evidence (in)sufficient for FC, based on three trained models with different Transformer architectures and three FC datasets. Second, we ask annotators whether the omitted evidence was important for FC, resulting in a novel diagnostic dataset, SufficientFacts, for FC with omitted evidence. We find that models are least successful in detecting missing evidence when adverbial modifiers are omitted (21% accuracy), whereas it is easiest for omitted date modifiers (63% accuracy). Finally, we propose a novel data augmentation strategy for contrastive self-learning of missing evidence by employing the proposed omission method combined with tri-training. It improves performance for Evidence Sufficiency Prediction by up to 17.8 F1 score, which in turn improves FC performance by up to 2.6 F1 score.