 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Speech from Intracranial Depth Electrodes using an Encoder-Decoder Framework
Paper and Code

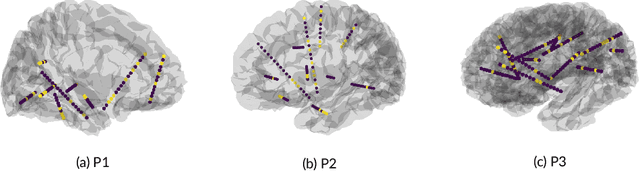
Speech Neuroprostheses have the potential to enable communication for people with dysarthria or anarthria. Recent advances have demonstrated high-quality text decoding and speech synthesis from electrocorticographic grids placed on the cortical surface. Here, we investigate a less invasive measurement modality, namely stereotactic EEG (sEEG) that provides sparse sampling from multiple brain regions, including subcortical regions. To evaluate whether sEEG can also be used to synthesize high-quality audio from neural recordings, we employ a recurrent encoder-decoder framework based on modern deep learning methods. We demonstrate that high-quality speech can be reconstructed from these minimally invasive recordings, despite a limited amount of training data. Finally, we utilize variational feature dropout to successfully identify the most informative electrode contacts.