 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStorybooth: Training-free Multi-Subject Consistency for Improved Visual Storytelling
Apr 08, 2025Training-free consistent text-to-image generation depicting the same subjects across different images is a topic of widespread recent interest. Existing works in this direction predominantly rely on cross-frame self-attention; which improves subject-consistency by allowing tokens in each frame to pay attention to tokens in other frames during self-attention computation. While useful for single subjects, we find that it struggles when scaling to multiple characters. In this work, we first analyze the reason for these limitations. Our exploration reveals that the primary-issue stems from self-attention-leakage, which is exacerbated when trying to ensure consistency across multiple-characters. This happens when tokens from one subject pay attention to other characters, causing them to appear like each other (e.g., a dog appearing like a duck). Motivated by these findings, we propose StoryBooth: a training-free approach for improving multi-character consistency. In particular, we first leverage multi-modal chain-of-thought reasoning and region-based generation to apriori localize the different subjects across the desired story outputs. The final outputs are then generated using a modified diffusion model which consists of two novel layers: 1) a bounded cross-frame self-attention layer for reducing inter-character attention leakage, and 2) token-merging layer for improving consistency of fine-grain subject details. Through both qualitative and quantitative results we find that the proposed approach surpasses prior state-of-the-art, exhibiting improved consistency across both multiple-characters and fine-grain subject details.
Motion-Based Handwriting Recognition and Word Reconstruction
Jan 15, 2021
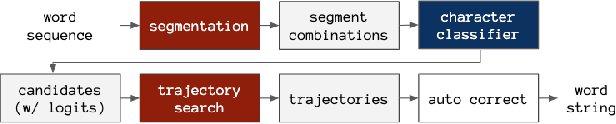


In this project, we leverage a trained single-letter classifier to predict the written word from a continuously written word sequence, by designing a word reconstruction pipeline consisting of a dynamic-programming algorithm and an auto-correction model. We conduct experiments to optimize models in this pipeline, then employ domain adaptation to explore using this pipeline on unseen data distributions.
Motion-Based Handwriting Recognition
Jan 15, 2021
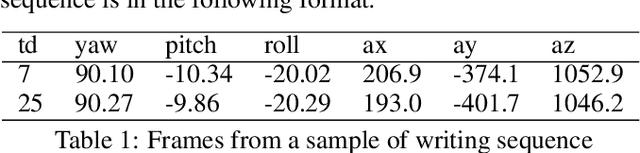


We attempt to overcome the restriction of requiring a writing surface for handwriting recognition. In this study, we design a prototype of a stylus equipped with motion sensor, and utilizes gyroscopic and acceleration sensor reading to perform written letter classification using various deep learning techniques such as CNN and RNNs. We also explore various data augmentation techniques and their effects, reaching up to 86% accuracy.