 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards High-Frequency Tracking and Fast Edge-Aware Optimization
Sep 02, 2023This dissertation advances the state of the art for AR/VR tracking systems by increasing the tracking frequency by orders of magnitude and proposes an efficient algorithm for the problem of edge-aware optimization. AR/VR is a natural way of interacting with computers, where the physical and digital worlds coexist. We are on the cusp of a radical change in how humans perform and interact with computing. Humans are sensitive to small misalignments between the real and the virtual world, and tracking at kilo-Hertz frequencies becomes essential. Current vision-based systems fall short, as their tracking frequency is implicitly limited by the frame-rate of the camera. This thesis presents a prototype system which can track at orders of magnitude higher than the state-of-the-art methods using multiple commodity cameras. The proposed system exploits characteristics of the camera traditionally considered as flaws, namely rolling shutter and radial distortion. The experimental evaluation shows the effectiveness of the method for various degrees of motion. Furthermore, edge-aware optimization is an indispensable tool in the computer vision arsenal for accurate filtering of depth-data and image-based rendering, which is increasingly being used for content creation and geometry processing for AR/VR. As applications increasingly demand higher resolution and speed, there exists a need to develop methods that scale accordingly. This dissertation proposes such an edge-aware optimization framework which is efficient, accurate, and algorithmically scales well, all of which are much desirable traits not found jointly in the state of the art. The experiments show the effectiveness of the framework in a multitude of computer vision tasks such as computational photography and stereo.
A Practical Stereo Depth System for Smart Glasses
Nov 19, 2022



We present the design of a productionized end-to-end stereo depth sensing system that does pre-processing, online stereo rectification, and stereo depth estimation with a fallback to monocular depth estimation when rectification is unreliable. The output of our depth sensing system is then used in a novel view generation pipeline to create 3D computational photography effect using point-of-view images captured by smart glasses. All these steps are executed on-device on the stringent compute budget of a mobile phone, and because we expect the users can use a wide range of smartphones, our design needs to be general and cannot be dependent on a particular hardware or ML accelerator such as a smartphone GPU. Although each of these steps is well-studied, a description of a practical system is still lacking. For such a system, each of these steps need to work in tandem with one another and fallback gracefully on failures within the system or less than ideal input data. We show how we handle unforeseen changes to calibration, e.g. due to heat, robustly support depth estimation in the wild, and still abide by the memory and latency constraints required for a smooth user experience. We show that our trained models are fast, that run in less than 1s on a six-year-old Samsung Galaxy S8 phone's CPU. Our models generalize well to unseen data and achieve good results on Middlebury and in-the-wild images captured from the smart glasses.
Mapped Convolutions
Jun 26, 2019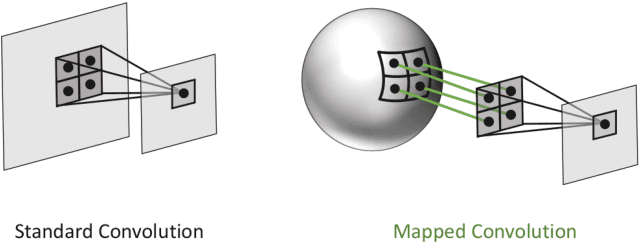

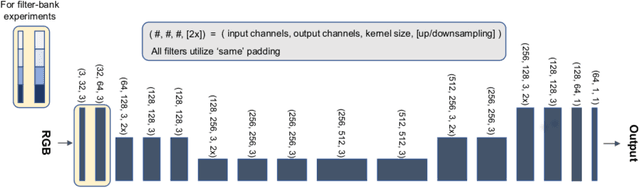

We present a versatile formulation of the convolution operation that we term a "mapped convolution." The standard convolution operation implicitly samples the pixel grid and computes a weighted sum. Our mapped convolution decouples these two components, freeing the operation from the confines of the image grid and allowing the kernel to process any type of structured data. As a test case, we demonstrate its use by applying it to dense inference on spherical data. We perform an in-depth study of existing spherical image convolution methods and propose an improved sampling method for equirectangular images. Then, we discuss the impact of data discretization when deriving a sampling function, highlighting drawbacks of the cube map representation for spherical data. Finally, we illustrate how mapped convolutions enable us to convolve directly on a mesh by projecting the spherical image onto a geodesic grid and training on the textured mesh. This method exceeds the state of the art for spherical depth estimation by nearly 17%. Our findings suggest that mapped convolutions can be instrumental in expanding the application scope of convolutional neural networks.
The Domain Transform Solver
May 11, 2018
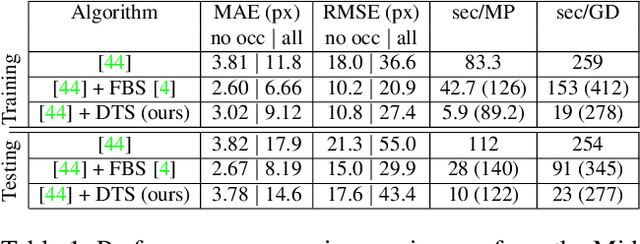

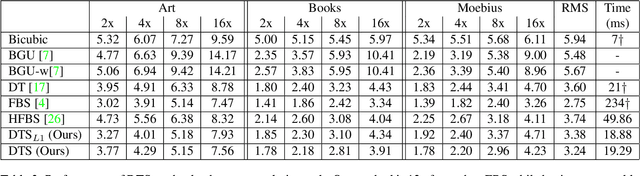
We present a framework for edge-aware optimization that is an order of magnitude faster than the state of the art while having comparable performance. Our key insight is that the optimization can be formulated by leveraging properties of the domain transform, a method for edge-aware filtering that defines a distance-preserving 1D mapping of the input space. This enables our method to improve performance for a variety of problems including stereo, depth super-resolution, and render from defocus, while keeping the computational complexity linear in the number of pixels. Our method is highly parallelizable and adaptable, and it has demonstrable scalability with respect to image resolution.