 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Novel View Synthesis using Depth Aware 3D Gaussian Splatting
Oct 14, 2024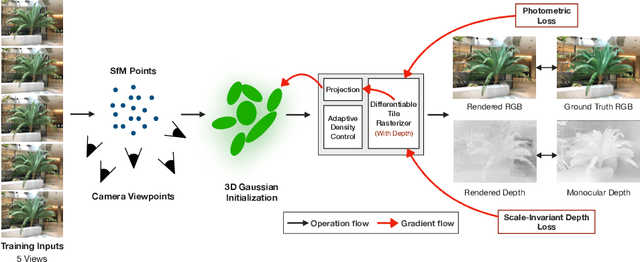



3D Gaussian splatting has surpassed neural radiance field methods in novel view synthesis by achieving lower computational costs and real-time high-quality rendering. Although it produces a high-quality rendering with a lot of input views, its performance drops significantly when only a few views are available. In this work, we address this by proposing a depth-aware Gaussian splatting method for few-shot novel view synthesis. We use monocular depth prediction as a prior, along with a scale-invariant depth loss, to constrain the 3D shape under just a few input views. We also model color using lower-order spherical harmonics to avoid overfitting. Further, we observe that removing splats with lower opacity periodically, as performed in the original work, leads to a very sparse point cloud and, hence, a lower-quality rendering. To mitigate this, we retain all the splats, leading to a better reconstruction in a few view settings. Experimental results show that our method outperforms the traditional 3D Gaussian splatting methods by achieving improvements of 10.5% in peak signal-to-noise ratio, 6% in structural similarity index, and 14.1% in perceptual similarity, thereby validating the effectiveness of our approach. The code will be made available at: https://github.com/raja-kumar/depth-aware-3DGS
Harnessing Shared Relations via Multimodal Mixup Contrastive Learning for Multimodal Classification
Sep 26, 2024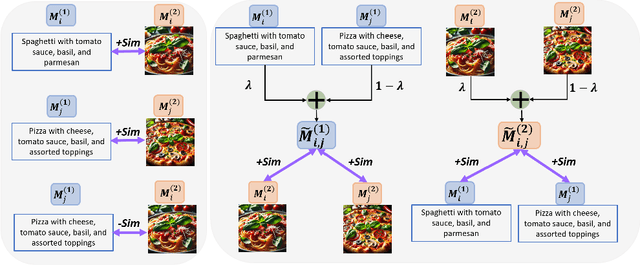
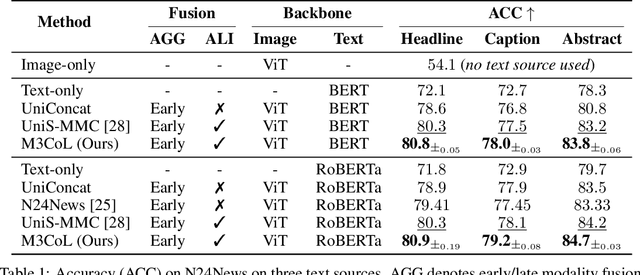
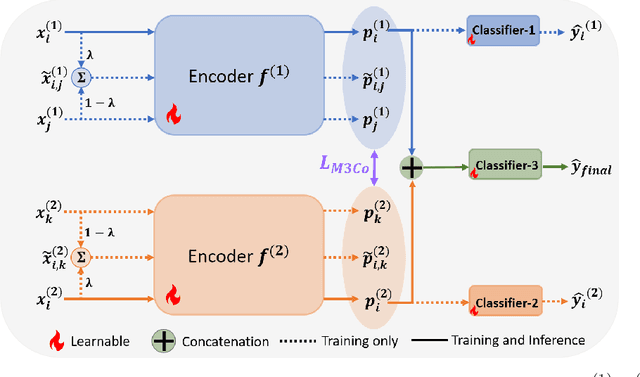
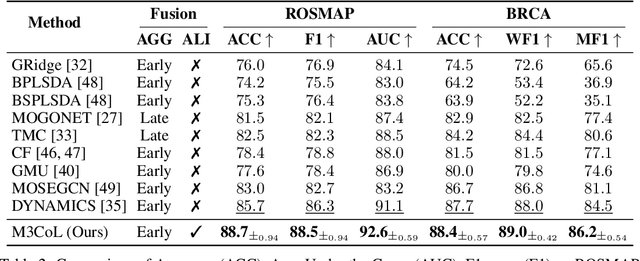
Deep multimodal learning has shown remarkable success by leveraging contrastive learning to capture explicit one-to-one relations across modalities. However, real-world data often exhibits shared relations beyond simple pairwise associations. We propose M3CoL, a Multimodal Mixup Contrastive Learning approach to capture nuanced shared relations inherent in multimodal data. Our key contribution is a Mixup-based contrastive loss that learns robust representations by aligning mixed samples from one modality with their corresponding samples from other modalities thereby capturing shared relations between them. For multimodal classification tasks, we introduce a framework that integrates a fusion module with unimodal prediction modules for auxiliary supervision during training, complemented by our proposed Mixup-based contrastive loss. Through extensive experiments on diverse datasets (N24News, ROSMAP, BRCA, and Food-101), we demonstrate that M3CoL effectively captures shared multimodal relations and generalizes across domains. It outperforms state-of-the-art methods on N24News, ROSMAP, and BRCA, while achieving comparable performance on Food-101. Our work highlights the significance of learning shared relations for robust multimodal learning, opening up promising avenues for future research.
Mental Disorder Classification via Temporal Representation of Text
Jun 15, 2024



Mental disorders pose a global challenge, aggravated by the shortage of qualified mental health professionals. Mental disorder prediction from social media posts by current LLMs is challenging due to the complexities of sequential text data and the limited context length of language models. Current language model-based approaches split a single data instance into multiple chunks to compensate for limited context size. The predictive model is then applied to each chunk individually, and the most voted output is selected as the final prediction. This results in the loss of inter-post dependencies and important time variant information, leading to poor performance. We propose a novel framework which first compresses the large sequence of chronologically ordered social media posts into a series of numbers. We then use this time variant representation for mental disorder classification. We demonstrate the generalization capabilities of our framework by outperforming the current SOTA in three different mental conditions: depression, self-harm, and anorexia, with an absolute improvement of 5% in the F1 score. We investigate the situation where current data instances fall within the context length of language models and present empirical results highlighting the importance of temporal properties of textual data. Furthermore, we utilize the proposed framework for a cross-domain study, exploring commonalities across disorders and the possibility of inter-domain data usage.
Disjoint Pose and Shape for 3D Face Reconstruction
Aug 26, 2023



Existing methods for 3D face reconstruction from a few casually captured images employ deep learning based models along with a 3D Morphable Model(3DMM) as face geometry prior. Structure From Motion(SFM), followed by Multi-View Stereo (MVS), on the other hand, uses dozens of high-resolution images to reconstruct accurate 3D faces.However, it produces noisy and stretched-out results with only two views available. In this paper, taking inspiration from both these methods, we propose an end-to-end pipeline that disjointly solves for pose and shape to make the optimization stable and accurate. We use a face shape prior to estimate face pose and use stereo matching followed by a 3DMM to solve for the shape. The proposed method achieves end-to-end topological consistency, enables iterative face pose refinement procedure, and show remarkable improvement on both quantitative and qualitative results over existing state-of-the-art methods.
Task Oriented Conversational Modelling With Subjective Knowledge
Mar 30, 2023Existing conversational models are handled by a database(DB) and API based systems. However, very often users' questions require information that cannot be handled by such systems. Nonetheless, answers to these questions are available in the form of customer reviews and FAQs. DSTC-11 proposes a three stage pipeline consisting of knowledge seeking turn detection, knowledge selection and response generation to create a conversational model grounded on this subjective knowledge. In this paper, we focus on improving the knowledge selection module to enhance the overall system performance. In particular, we propose entity retrieval methods which result in an accurate and faster knowledge search. Our proposed Named Entity Recognition (NER) based entity retrieval method results in 7X faster search compared to the baseline model. Additionally, we also explore a potential keyword extraction method which can improve the accuracy of knowledge selection. Preliminary results show a 4 \% improvement in exact match score on knowledge selection task. The code is available https://github.com/raja-kumar/knowledge-grounded-TODS
Hybrid and Non-Uniform quantization methods using retro synthesis data for efficient inference
Dec 26, 2020


Existing quantization aware training methods attempt to compensate for the quantization loss by leveraging on training data, like most of the post-training quantization methods, and are also time consuming. Both these methods are not effective for privacy constraint applications as they are tightly coupled with training data. In contrast, this paper proposes a data-independent post-training quantization scheme that eliminates the need for training data. This is achieved by generating a faux dataset, hereafter referred to as Retro-Synthesis Data, from the FP32 model layer statistics and further using it for quantization. This approach outperformed state-of-the-art methods including, but not limited to, ZeroQ and DFQ on models with and without Batch-Normalization layers for 8, 6, and 4 bit precisions on ImageNet and CIFAR-10 datasets. We also introduced two futuristic variants of post-training quantization methods namely Hybrid Quantization and Non-Uniform Quantization