 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Shaping for Inference-Time Alignment: A Stackelberg Game Perspective
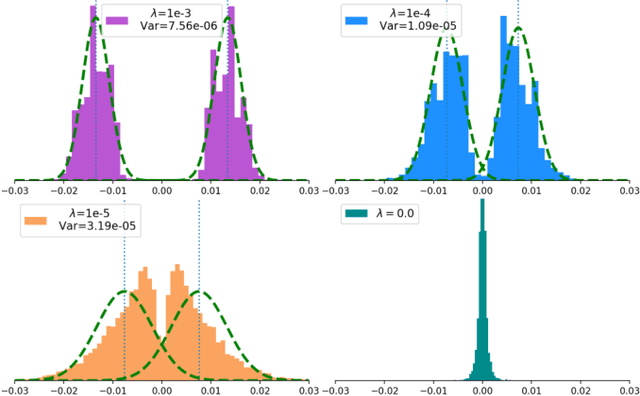
Jan 31, 2026Existing alignment methods directly use the reward model learned from user preference data to optimize an LLM policy, subject to KL regularization with respect to the base policy. This practice is suboptimal for maximizing user's utility because the KL regularization may cause the LLM to inherit the bias in the base policy that conflicts with user preferences. While amplifying rewards for preferred outputs can mitigate this bias, it also increases the risk of reward hacking. This tradeoff motivates the problem of optimally designing reward models under KL regularization. We formalize this reward model optimization problem as a Stackelberg game, and show that a simple reward shaping scheme can effectively approximate the optimal reward model. We empirically evaluate our method in inference-time alignment settings and demonstrate that it integrates seamlessly into existing alignment methods with minimal overhead. Our method consistently improves average reward and achieves win-tie rates exceeding 66% against all baselines, averaged across evaluation settings.
Are LLMs Smarter Than Chimpanzees? An Evaluation on Perspective Taking and Knowledge State Estimation
Jan 18, 2026Cognitive anthropology suggests that the distinction of human intelligence lies in the ability to infer other individuals' knowledge states and understand their intentions. In comparison, our closest animal relative, chimpanzees, lack the capacity to do so. With this paper, we aim to evaluate LLM performance in the area of knowledge state tracking and estimation. We design two tasks to test (1) if LLMs can detect when story characters, through their actions, demonstrate knowledge they should not possess, and (2) if LLMs can predict story characters' next actions based on their own knowledge vs. objective truths they do not know. Results reveal that most current state-of-the-art LLMs achieve near-random performance on both tasks, and are substantially inferior to humans. We argue future LLM research should place more weight on the abilities of knowledge estimation and intention understanding.
Information Design with Unknown Prior
Oct 07, 2024Classical information design models (e.g., Bayesian persuasion and cheap talk) require players to have perfect knowledge of the prior distribution of the state of the world. Our paper studies repeated persuasion problems in which the information designer does not know the prior. The information designer learns to design signaling schemes from repeated interactions with the receiver. We design learning algorithms for the information designer to achieve no regret compared to using the optimal signaling scheme with known prior, under two models of the receiver's decision-making. (1) The first model assumes that the receiver knows the prior and can perform posterior update and best respond to signals. In this model, we design a learning algorithm for the information designer with $O(\log T)$ regret in the general case, and another algorithm with $\Theta(\log \log T)$ regret in the case where the receiver has only two actions. (2) The second model assumes that the receiver does not know the prior and employs a no-regret learning algorithm to take actions. We show that the information designer can achieve regret $O(\sqrt{\mathrm{rReg}(T) T})$, where $\mathrm{rReg}(T)=o(T)$ is an upper bound on the receiver's learning regret. Our work thus provides a learning foundation for the problem of information design with unknown prior.
Domain Adaptive Semantic Segmentation by Optimal Transport
Mar 29, 2023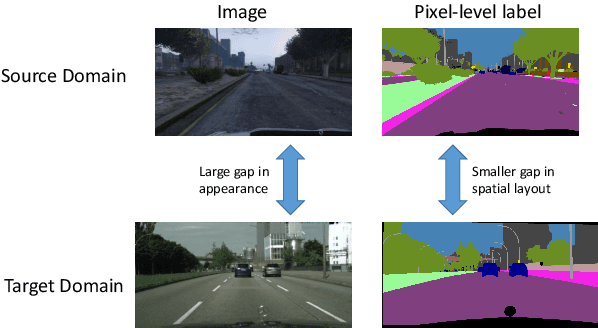
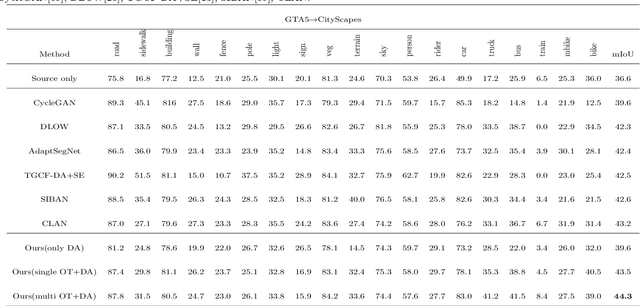
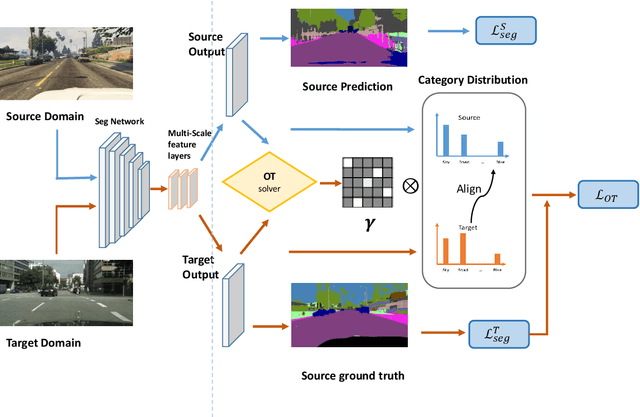
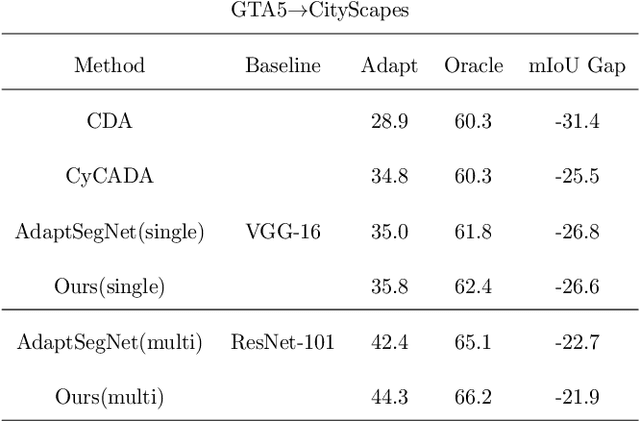
Scene segmentation is widely used in the field of autonomous driving for environment perception, and semantic scene segmentation (3S) has received a great deal of attention due to the richness of the semantic information it contains. It aims to assign labels to pixels in an image, thus enabling automatic image labeling. Current approaches are mainly based on convolutional neural networks (CNN), but they rely on a large number of labels. Therefore, how to use a small size of labeled data to achieve semantic segmentation becomes more and more important. In this paper, we propose a domain adaptation (DA) framework based on optimal transport (OT) and attention mechanism to address this issue. Concretely, first we generate the output space via CNN due to its superiority of feature representation. Second, we utilize OT to achieve a more robust alignment of source and target domains in output space, where the OT plan defines a well attention mechanism to improve the adaptation of the model. In particular, with OT, the number of network parameters has been reduced and the network has been better interpretable. Third, to better describe the multi-scale property of features, we construct a multi-scale segmentation network to perform domain adaptation. Finally, in order to verify the performance of our proposed method, we conduct experimental comparison with three benchmark and four SOTA methods on three scene datasets, and the mean intersection-over-union (mIOU) has been significant improved, and visualization results under multiple domain adaptation scenarios also show that our proposed method has better performance than compared semantic segmentation methods.
A Heterogeneous Dynamical Graph Neural Networks Approach to Quantify Scientific Impact
Mar 26, 2020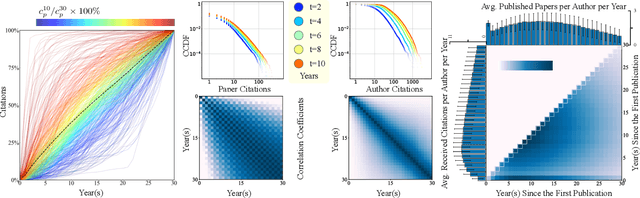
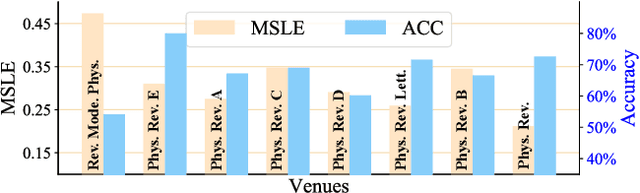
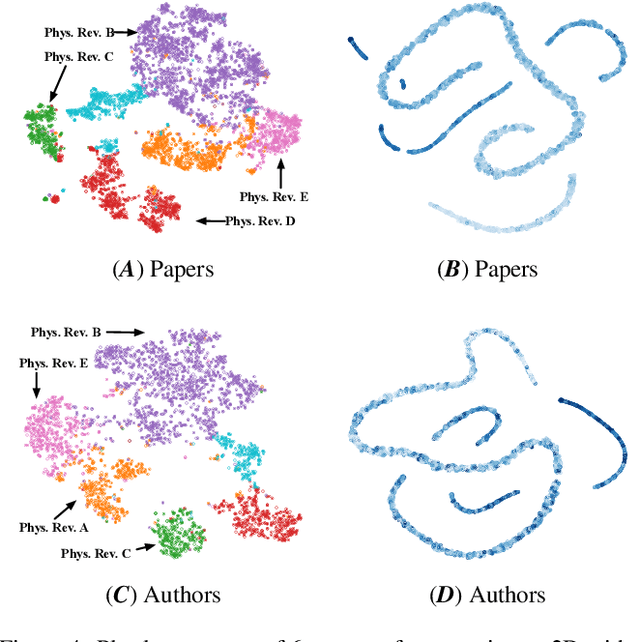
Quantifying and predicting the long-term impact of scientific writings or individual scholars has important implications for many policy decisions, such as funding proposal evaluation and identifying emerging research fields. In this work, we propose an approach based on Heterogeneous Dynamical Graph Neural Network (HDGNN) to explicitly model and predict the cumulative impact of papers and authors. HDGNN extends heterogeneous GNNs by incorporating temporally evolving characteristics and capturing both structural properties of attributed graph and the growing sequence of citation behavior. HDGNN is significantly different from previous models in its capability of modeling the node impact in a dynamic manner while taking into account the complex relations among nodes. Experiments conducted on a real citation dataset demonstrate its superior performance of predicting the impact of both papers and authors.
Projection Convolutional Neural Networks for 1-bit CNNs via Discrete Back Propagation
Dec 12, 2018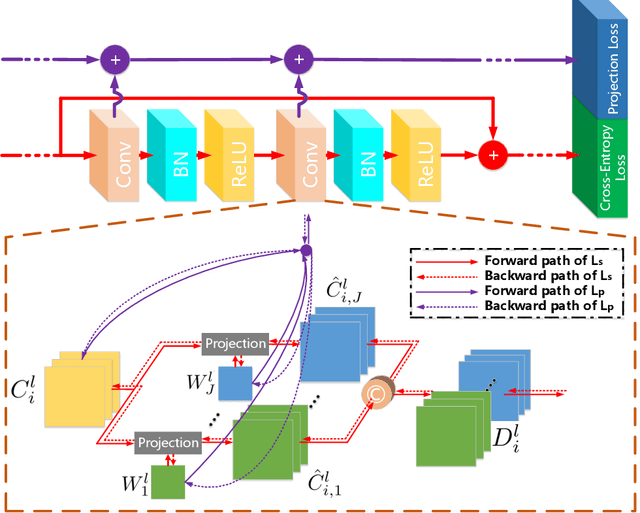


The advancement of deep convolutional neural networks (DCNNs) has driven significant improvement in the accuracy of recognition systems for many computer vision tasks. However, their practical applications are often restricted in resource-constrained environments. In this paper, we introduce projection convolutional neural networks (PCNNs) with a discrete back propagation via projection (DBPP) to improve the performance of binarized neural networks (BNNs). The contributions of our paper include: 1) for the first time, the projection function is exploited to efficiently solve the discrete back propagation problem, which leads to a new highly compressed CNNs (termed PCNNs); 2) by exploiting multiple projections, we learn a set of diverse quantized kernels that compress the full-precision kernels in a more efficient way than those proposed previously; 3) PCNNs achieve the best classification performance compared to other state-of-the-art BNNs on the ImageNet and CIFAR datasets.
Memory Attention Networks for Skeleton-based Action Recognition
May 03, 2018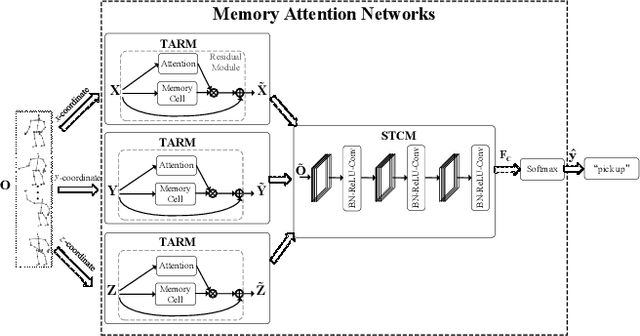
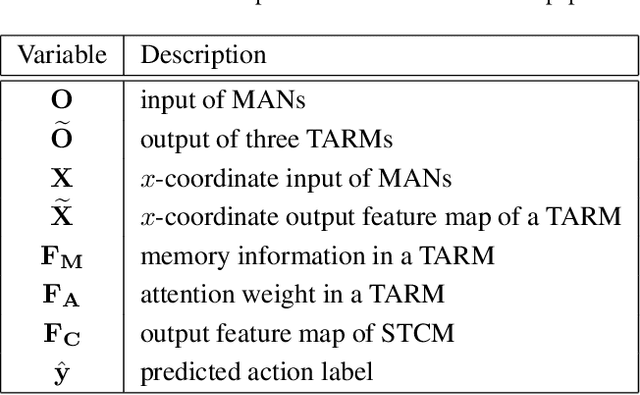
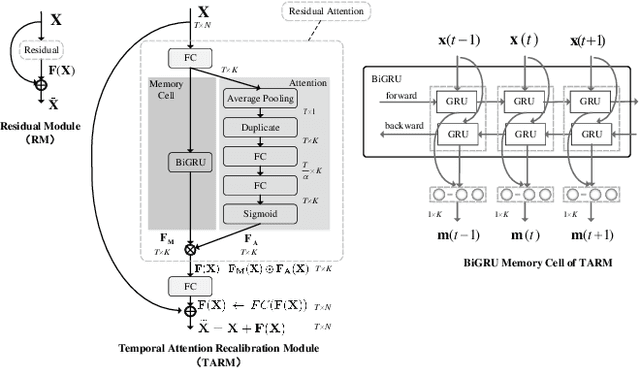
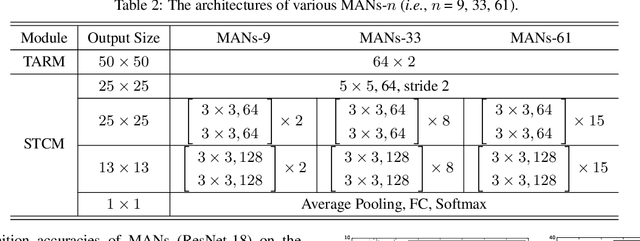
Skeleton-based action recognition task is entangled with complex spatio-temporal variations of skeleton joints, and remains challenging for Recurrent Neural Networks (RNNs). In this work, we propose a temporal-then-spatial recalibration scheme to alleviate such complex variations, resulting in an end-to-end Memory Attention Networks (MANs) which consist of a Temporal Attention Recalibration Module (TARM) and a Spatio-Temporal Convolution Module (STCM). Specifically, the TARM is deployed in a residual learning module that employs a novel attention learning network to recalibrate the temporal attention of frames in a skeleton sequence. The STCM treats the attention calibrated skeleton joint sequences as images and leverages the Convolution Neural Networks (CNNs) to further model the spatial and temporal information of skeleton data. These two modules (TARM and STCM) seamlessly form a single network architecture that can be trained in an end-to-end fashion. MANs significantly boost the performance of skeleton-based action recognition and achieve the best results on four challenging benchmark datasets: NTU RGB+D, HDM05, SYSU-3D and UT-Kinect.
Deep Fisher Discriminant Learning for Mobile Hand Gesture Recognition
Jul 12, 2017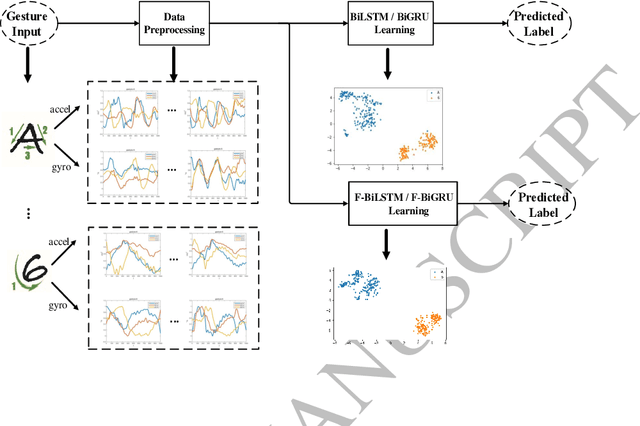
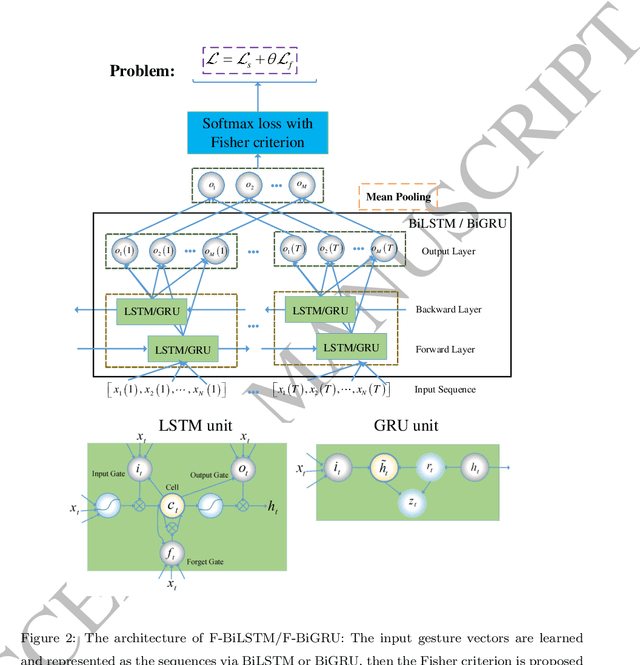
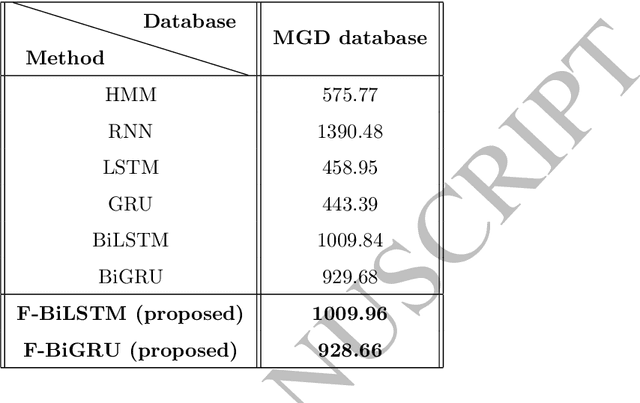
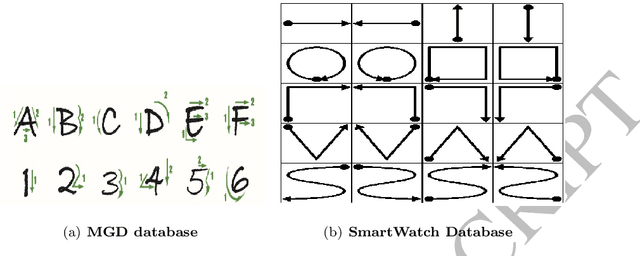
Gesture recognition is a challenging problem in the field of biometrics. In this paper, we integrate Fisher criterion into Bidirectional Long-Short Term Memory (BLSTM) network and Bidirectional Gated Recurrent Unit (BGRU),thus leading to two new deep models termed as F-BLSTM and F-BGRU. BothFisher discriminative deep models can effectively classify the gesture based on analyzing the acceleration and angular velocity data of the human gestures. Moreover, we collect a large Mobile Gesture Database (MGD) based on the accelerations and angular velocities containing 5547 sequences of 12 gestures. Extensive experiments are conducted to validate the superior performance of the proposed networks as compared to the state-of-the-art BLSTM and BGRU on MGD database and two benchmark databases (i.e. BUAA mobile gesture and SmartWatch gesture).
GM-Net: Learning Features with More Efficiency
Jun 21, 2017
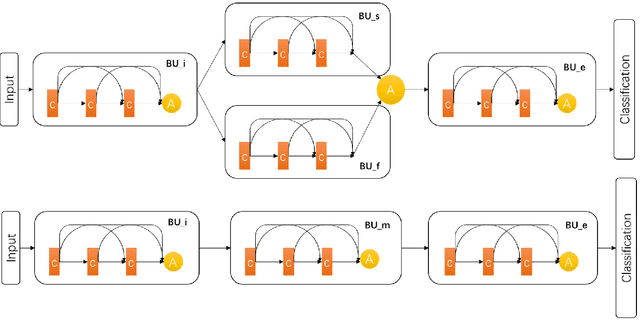

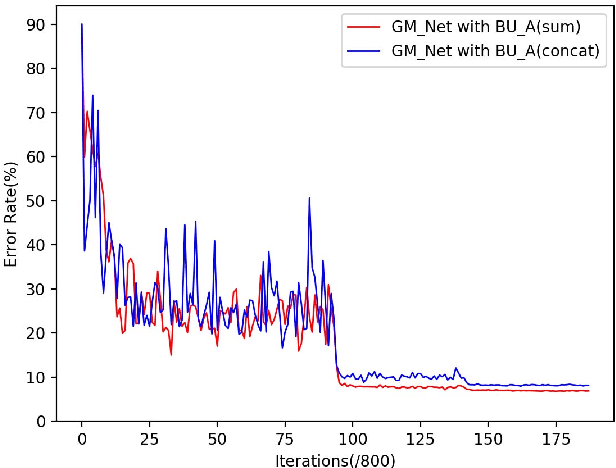
Deep Convolutional Neural Networks (CNNs) are capable of learning unprecedentedly effective features from images. Some researchers have struggled to enhance the parameters' efficiency using grouped convolution. However, the relation between the optimal number of convolutional groups and the recognition performance remains an open problem. In this paper, we propose a series of Basic Units (BUs) and a two-level merging strategy to construct deep CNNs, referred to as a joint Grouped Merging Net (GM-Net), which can produce joint grouped and reused deep features while maintaining the feature discriminability for classification tasks. Our GM-Net architectures with the proposed BU_A (dense connection) and BU_B (straight mapping) lead to significant reduction in the number of network parameters and obtain performance improvement in image classification tasks. Extensive experiments are conducted to validate the superior performance of the GM-Net than the state-of-the-arts on the benchmark datasets, e.g., MNIST, CIFAR-10, CIFAR-100 and SVHN.
Deep Spatio-temporal Manifold Network for Action Recognition
May 09, 2017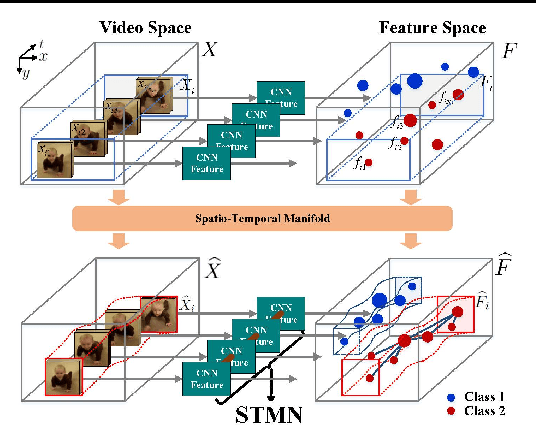
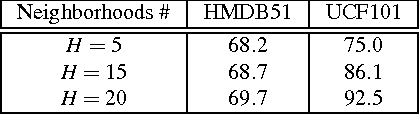
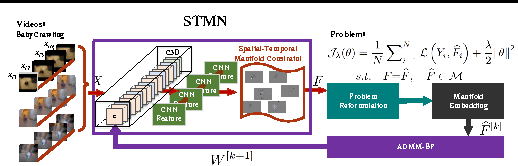
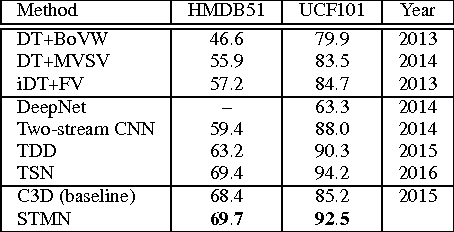
Visual data such as videos are often sampled from complex manifold. We propose leveraging the manifold structure to constrain the deep action feature learning, thereby minimizing the intra-class variations in the feature space and alleviating the over-fitting problem. Considering that manifold can be transferred, layer by layer, from the data domain to the deep features, the manifold priori is posed from the top layer into the back propagation learning procedure of convolutional neural network (CNN). The resulting algorithm --Spatio-Temporal Manifold Network-- is solved with the efficient Alternating Direction Method of Multipliers and Backward Propagation (ADMM-BP). We theoretically show that STMN recasts the problem as projection over the manifold via an embedding method. The proposed approach is evaluated on two benchmark datasets, showing significant improvements to the baselines.