 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptive Semantic Segmentation by Optimal Transport
Mar 29, 2023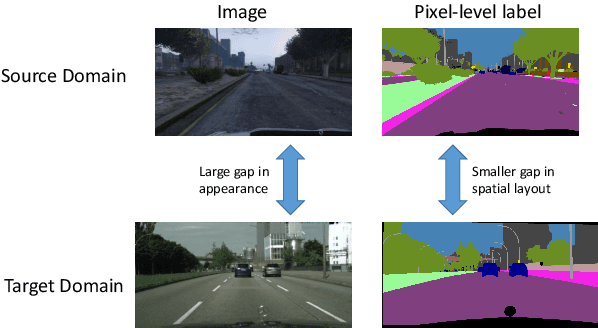
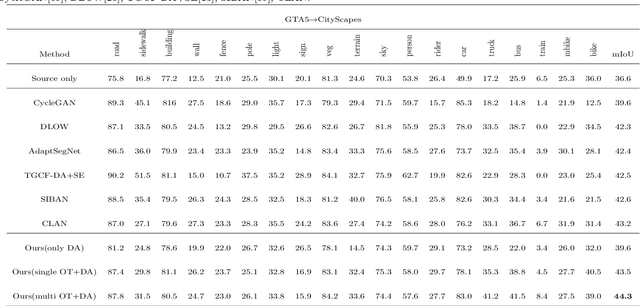
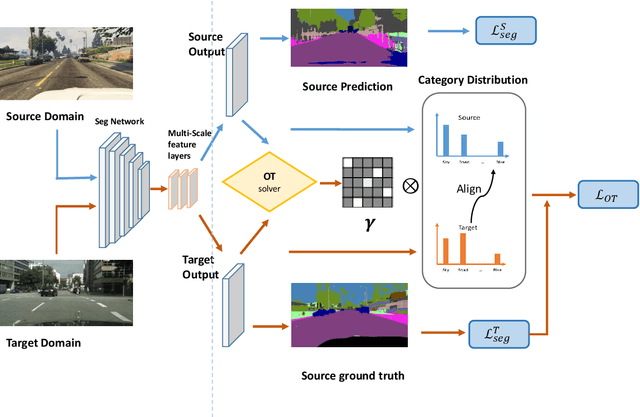
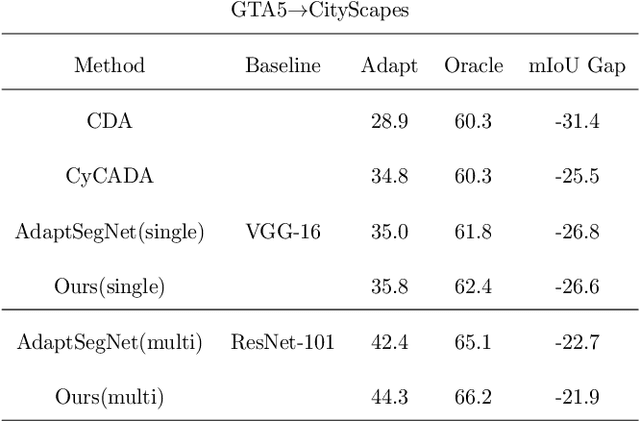
Scene segmentation is widely used in the field of autonomous driving for environment perception, and semantic scene segmentation (3S) has received a great deal of attention due to the richness of the semantic information it contains. It aims to assign labels to pixels in an image, thus enabling automatic image labeling. Current approaches are mainly based on convolutional neural networks (CNN), but they rely on a large number of labels. Therefore, how to use a small size of labeled data to achieve semantic segmentation becomes more and more important. In this paper, we propose a domain adaptation (DA) framework based on optimal transport (OT) and attention mechanism to address this issue. Concretely, first we generate the output space via CNN due to its superiority of feature representation. Second, we utilize OT to achieve a more robust alignment of source and target domains in output space, where the OT plan defines a well attention mechanism to improve the adaptation of the model. In particular, with OT, the number of network parameters has been reduced and the network has been better interpretable. Third, to better describe the multi-scale property of features, we construct a multi-scale segmentation network to perform domain adaptation. Finally, in order to verify the performance of our proposed method, we conduct experimental comparison with three benchmark and four SOTA methods on three scene datasets, and the mean intersection-over-union (mIOU) has been significant improved, and visualization results under multiple domain adaptation scenarios also show that our proposed method has better performance than compared semantic segmentation methods.