 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Spatio-temporal Manifold Network for Action Recognition
Paper and Code
May 09, 2017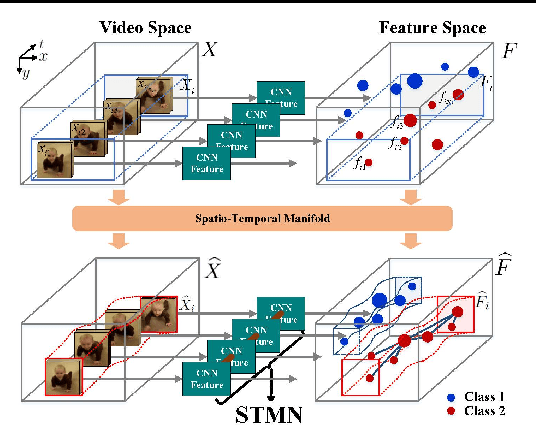
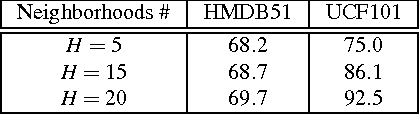
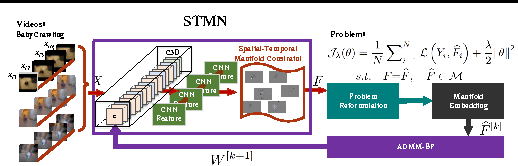
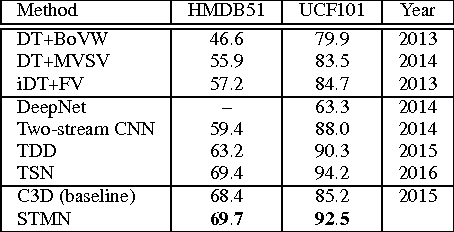
Visual data such as videos are often sampled from complex manifold. We propose leveraging the manifold structure to constrain the deep action feature learning, thereby minimizing the intra-class variations in the feature space and alleviating the over-fitting problem. Considering that manifold can be transferred, layer by layer, from the data domain to the deep features, the manifold priori is posed from the top layer into the back propagation learning procedure of convolutional neural network (CNN). The resulting algorithm --Spatio-Temporal Manifold Network-- is solved with the efficient Alternating Direction Method of Multipliers and Backward Propagation (ADMM-BP). We theoretically show that STMN recasts the problem as projection over the manifold via an embedding method. The proposed approach is evaluated on two benchmark datasets, showing significant improvements to the baselines.