 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Seq2Seq Autoencoder via Contrastive Learning for Abstractive Text Summarization
Aug 26, 2021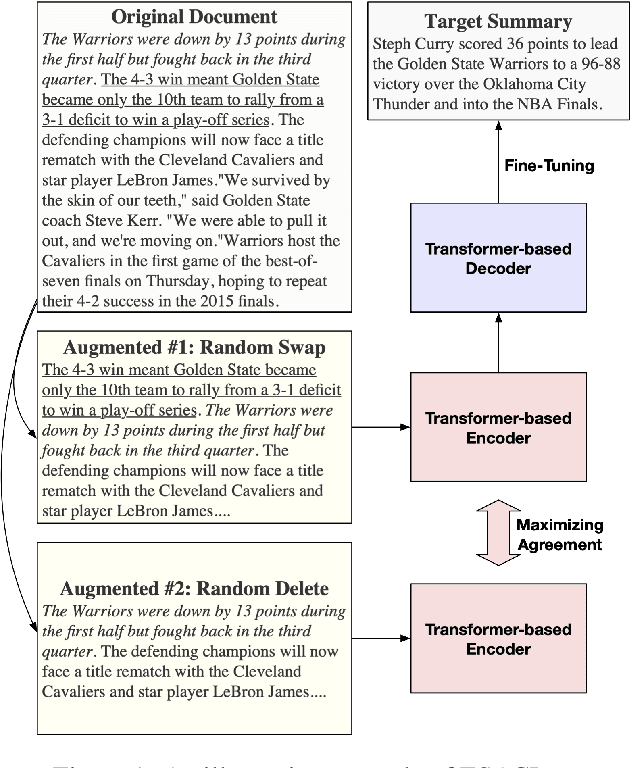
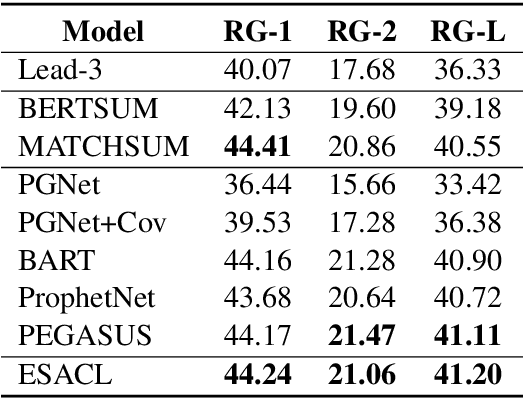
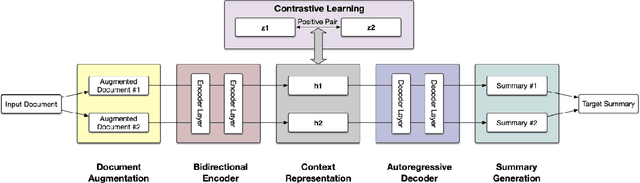
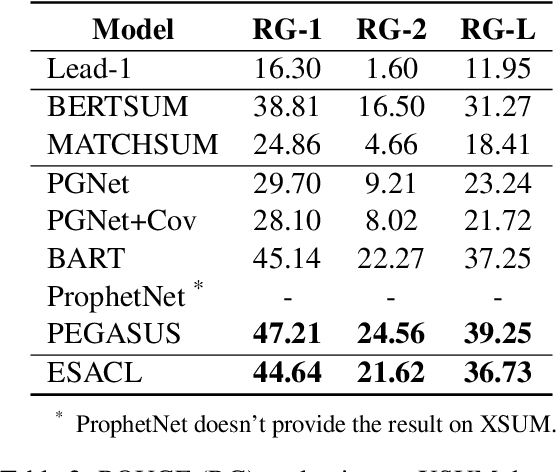
In this paper, we present a denoising sequence-to-sequence (seq2seq) autoencoder via contrastive learning for abstractive text summarization. Our model adopts a standard Transformer-based architecture with a multi-layer bi-directional encoder and an auto-regressive decoder. To enhance its denoising ability, we incorporate self-supervised contrastive learning along with various sentence-level document augmentation. These two components, seq2seq autoencoder and contrastive learning, are jointly trained through fine-tuning, which improves the performance of text summarization with regard to ROUGE scores and human evaluation. We conduct experiments on two datasets and demonstrate that our model outperforms many existing benchmarks and even achieves comparable performance to the state-of-the-art abstractive systems trained with more complex architecture and extensive computation resources.
Culture-inspired Multi-modal Color Palette Generation and Colorization: A Chinese Youth Subculture Case
Feb 10, 2021

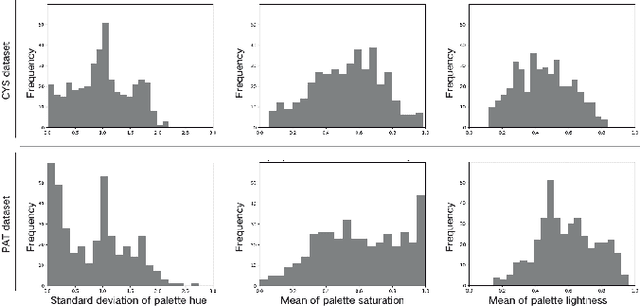
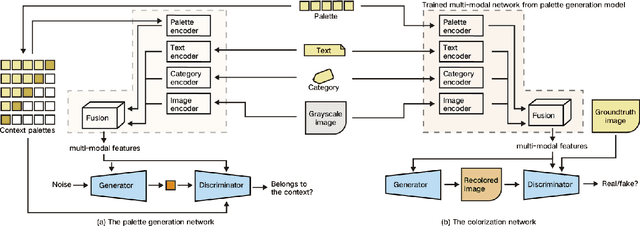
Color is an essential component of graphic design, acting not only as a visual factor but also carrying cultural implications. However, existing research on algorithmic color palette generation and colorization largely ignores the cultural aspect. In this paper, we contribute to this line of research by first constructing a unique color dataset inspired by a specific culture, i.e., Chinese Youth Subculture (CYS), which is an vibrant and trending cultural group especially for the Gen Z population. We show that the colors used in CYS have special aesthetic and semantic characteristics that are different from generic color theory. We then develop an interactive multi-modal generative framework to create CYS-styled color palettes, which can be used to put a CYS twist on images using our automatic colorization model. Our framework is illustrated via a demo system designed with the human-in-the-loop principle that constantly provides feedback to our algorithms. User studies are also conducted to evaluate our generation results.
A Framework and Dataset for Abstract Art Generation via CalligraphyGAN
Dec 02, 2020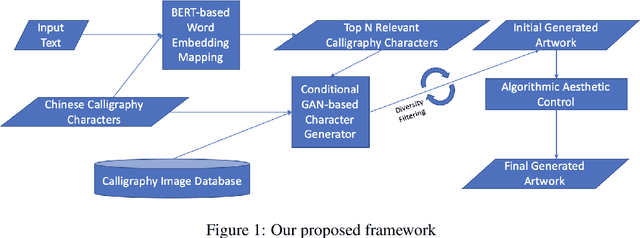

With the advancement of deep learning, artificial intelligence (AI) has made many breakthroughs in recent years and achieved superhuman performance in various tasks such as object detection, reading comprehension, and video games. Generative Modeling, such as various Generative Adversarial Networks (GAN) models, has been applied to generate paintings and music. Research in Natural Language Processing (NLP) also had a leap forward in 2018 since the release of the pre-trained contextual neural language models such as BERT and recently released GPT3. Despite the exciting AI applications aforementioned, AI is still significantly lagging behind humans in creativity, which is often considered the ultimate moonshot for AI. Our work is inspired by Chinese calligraphy, which is a unique form of visual art where the character itself is an aesthetic painting. We also draw inspirations from paintings of the Abstract Expressionist movement in the 1940s and 1950s, such as the work by American painter Franz Kline. In this paper, we present a creative framework based on Conditional Generative Adversarial Networks and Contextual Neural Language Model to generate abstract artworks that have intrinsic meaning and aesthetic value, which is different from the existing work, such as image captioning and text-to-image generation, where the texts are the descriptions of the images. In addition, we have publicly released a Chinese calligraphy image dataset and demonstrate our framework using a prototype system and a user study.
A Two-Phase Approach for Abstractive Podcast Summarization
Nov 16, 2020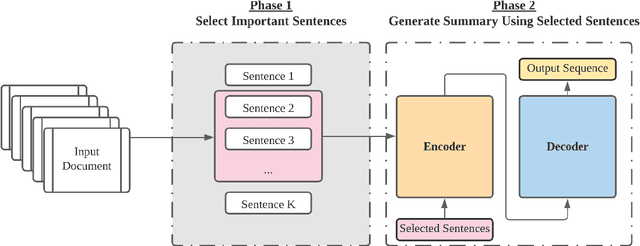


Podcast summarization is different from summarization of other data formats, such as news, patents, and scientific papers in that podcasts are often longer, conversational, colloquial, and full of sponsorship and advertising information, which imposes great challenges for existing models. In this paper, we focus on abstractive podcast summarization and propose a two-phase approach: sentence selection and seq2seq learning. Specifically, we first select important sentences from the noisy long podcast transcripts. The selection is based on sentence similarity to the reference to reduce the redundancy and the associated latent topics to preserve semantics. Then the selected sentences are fed into a pre-trained encoder-decoder framework for the summary generation. Our approach achieves promising results regarding both ROUGE-based measures and human evaluations.
Topic-Aware Abstractive Text Summarization
Oct 20, 2020
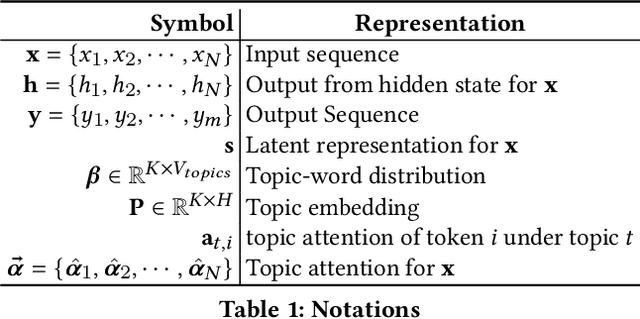
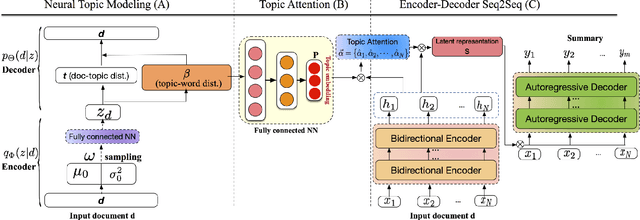
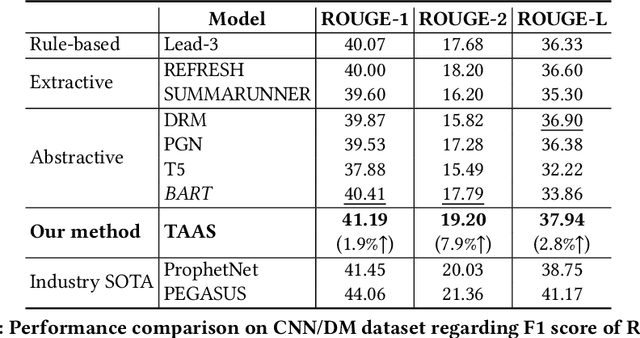
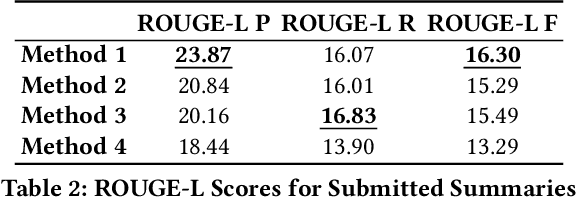
Automatic text summarization aims at condensing a document to a shorter version while preserving the key information. Different from extractive summarization which simply selects text fragments from the document, abstractive summarization generates the summary in a word-by-word manner. Most current state-of-the-art (SOTA) abstractive summarization methods are based on the Transformer-based encoder-decoder architecture and focus on novel self-supervised objectives in pre-training. While these models well capture the contextual information among words in documents, little attention has been paid to incorporating global semantics to better fine-tune for the downstream abstractive summarization task. In this study, we propose a topic-aware abstractive summarization (TAAS) framework by leveraging the underlying semantic structure of documents represented by their latent topics. Specifically, TAAS seamlessly incorporates a neural topic modeling into an encoder-decoder based sequence generation procedure via attention for summarization. This design is able to learn and preserve global semantics of documents and thus makes summarization effective, which has been proved by our experiments on real-world datasets. As compared to several cutting-edge baseline methods, we show that TAAS outperforms BART, a well-recognized SOTA model, by 2%, 8%, and 12% regarding the F measure of ROUGE-1, ROUGE-2, and ROUGE-L, respectively. TAAS also achieves comparable performance to PEGASUS and ProphetNet, which is difficult to accomplish given that training PEGASUS and ProphetNet requires enormous computing capacity beyond what we used in this study.
A Baseline Analysis for Podcast Abstractive Summarization
Aug 26, 2020
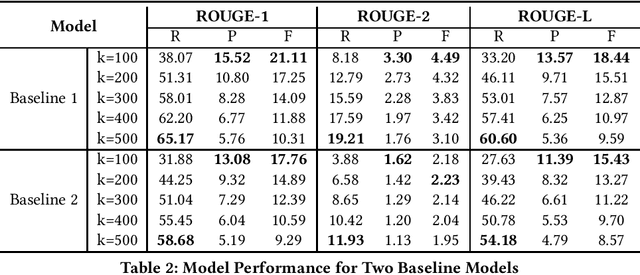

Podcast summary, an important factor affecting end-users' listening decisions, has often been considered a critical feature in podcast recommendation systems, as well as many downstream applications. Existing abstractive summarization approaches are mainly built on fine-tuned models on professionally edited texts such as CNN and DailyMail news. Different from news, podcasts are often longer, more colloquial and conversational, and noisier with contents on commercials and sponsorship, which makes automatic podcast summarization extremely challenging. This paper presents a baseline analysis of podcast summarization using the Spotify Podcast Dataset provided by TREC 2020. It aims to help researchers understand current state-of-the-art pre-trained models and hence build a foundation for creating better models.