 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Baseline Analysis for Podcast Abstractive Summarization
Paper and Code

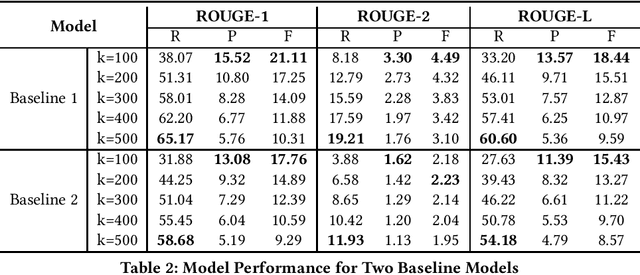

Podcast summary, an important factor affecting end-users' listening decisions, has often been considered a critical feature in podcast recommendation systems, as well as many downstream applications. Existing abstractive summarization approaches are mainly built on fine-tuned models on professionally edited texts such as CNN and DailyMail news. Different from news, podcasts are often longer, more colloquial and conversational, and noisier with contents on commercials and sponsorship, which makes automatic podcast summarization extremely challenging. This paper presents a baseline analysis of podcast summarization using the Spotify Podcast Dataset provided by TREC 2020. It aims to help researchers understand current state-of-the-art pre-trained models and hence build a foundation for creating better models.