 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Data Augmentation for Image Captioning using Diffusion Models
Paper and Code

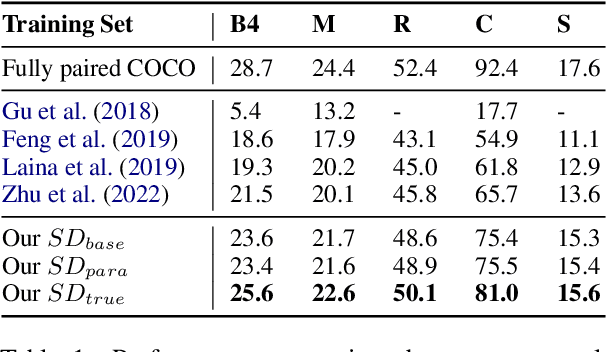
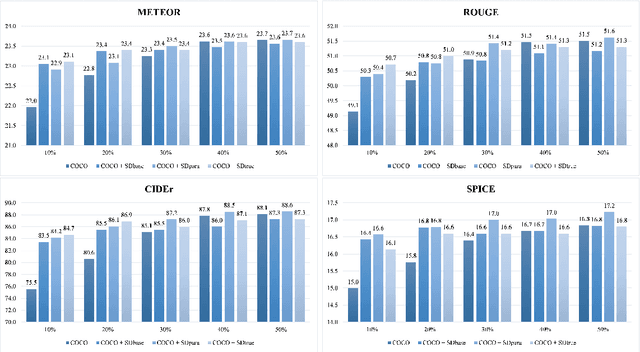
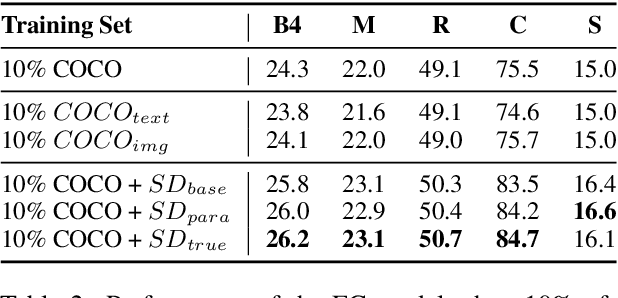
Image captioning, an important vision-language task, often requires a tremendous number of finely labeled image-caption pairs for learning the underlying alignment between images and texts. In this paper, we proposed a multimodal data augmentation method, leveraging a recent text-to-image model called Stable Diffusion, to expand the training set via high-quality generation of image-caption pairs. Extensive experiments on the MS COCO dataset demonstrate the advantages of our approach over several benchmark methods, and particularly a significant boost when having fewer training instances. In addition, models trained on our augmented datasets also outperform prior unpaired image captioning methods by a large margin. Finally, further improvement regarding the training efficiency and effectiveness can be obtained after intentionally filtering the generated data based on quality assessment.