 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Automation to Augmentation: Large Language Models Elevating Essay Scoring Landscape
Jan 12, 2024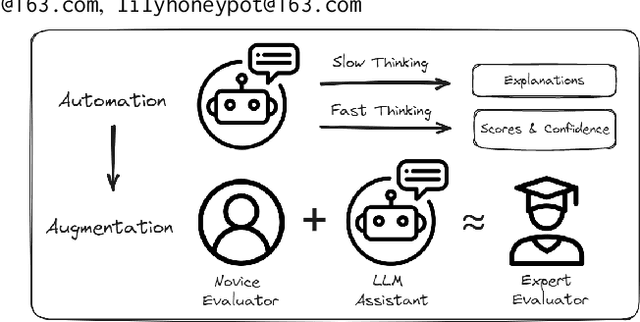
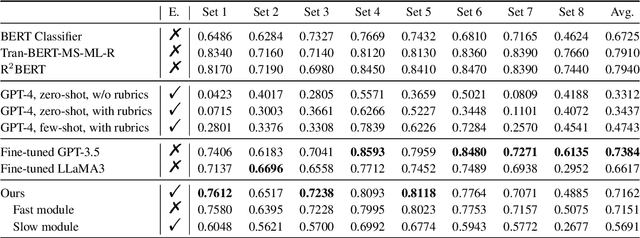

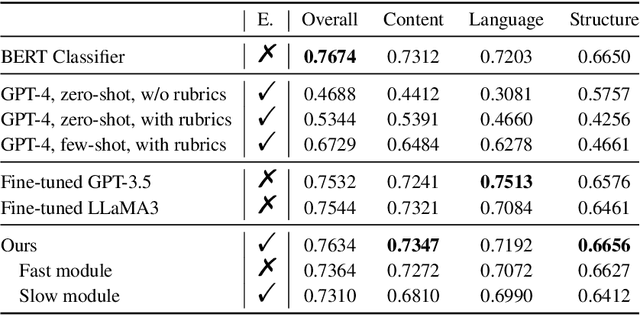
Receiving immediate and personalized feedback is crucial for second-language learners, and Automated Essay Scoring (AES) systems are a vital resource when human instructors are unavailable. This study investigates the effectiveness of Large Language Models (LLMs), specifically GPT-4 and fine-tuned GPT-3.5, as tools for AES. Our comprehensive set of experiments, conducted on both public and private datasets, highlights the remarkable advantages of LLM-based AES systems. They include superior accuracy, consistency, generalizability, and interpretability, with fine-tuned GPT-3.5 surpassing traditional grading models. Additionally, we undertake LLM-assisted human evaluation experiments involving both novice and expert graders. One pivotal discovery is that LLMs not only automate the grading process but also enhance the performance of human graders. Novice graders when provided with feedback generated by LLMs, achieve a level of accuracy on par with experts, while experts become more efficient and maintain greater consistency in their assessments. These results underscore the potential of LLMs in educational technology, paving the way for effective collaboration between humans and AI, ultimately leading to transformative learning experiences through AI-generated feedback.