 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Correlated Prompting for Visual Recognition with Missing Modalities
Oct 10, 2024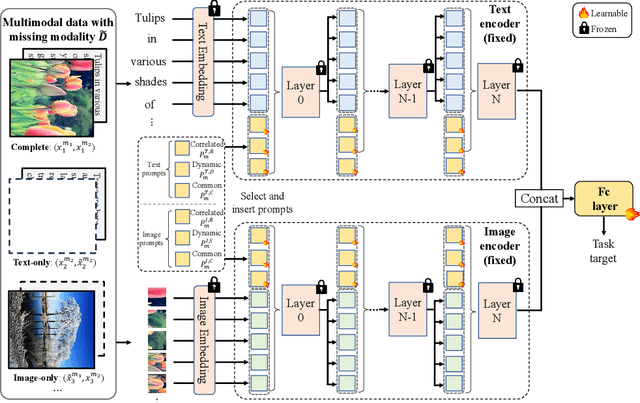
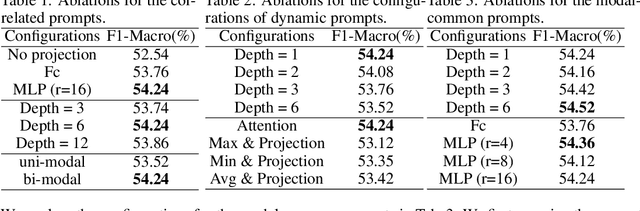
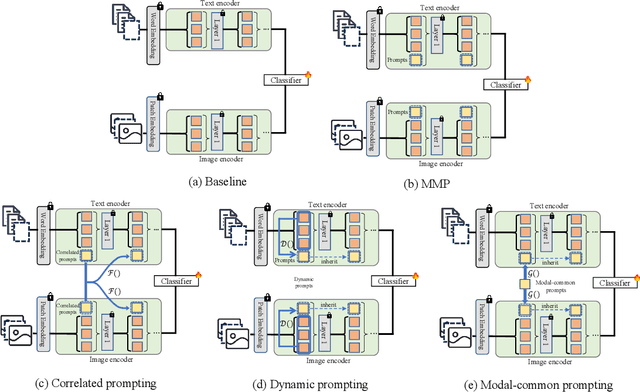
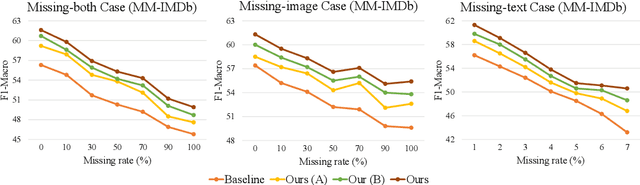
Large-scale multimodal models have shown excellent performance over a series of tasks powered by the large corpus of paired multimodal training data. Generally, they are always assumed to receive modality-complete inputs. However, this simple assumption may not always hold in the real world due to privacy constraints or collection difficulty, where models pretrained on modality-complete data easily demonstrate degraded performance on missing-modality cases. To handle this issue, we refer to prompt learning to adapt large pretrained multimodal models to handle missing-modality scenarios by regarding different missing cases as different types of input. Instead of only prepending independent prompts to the intermediate layers, we present to leverage the correlations between prompts and input features and excavate the relationships between different layers of prompts to carefully design the instructions. We also incorporate the complementary semantics of different modalities to guide the prompting design for each modality. Extensive experiments on three commonly-used datasets consistently demonstrate the superiority of our method compared to the previous approaches upon different missing scenarios. Plentiful ablations are further given to show the generalizability and reliability of our method upon different modality-missing ratios and types.
Pose-Guided Fine-Grained Sign Language Video Generation
Sep 25, 2024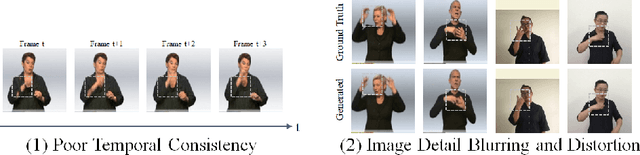

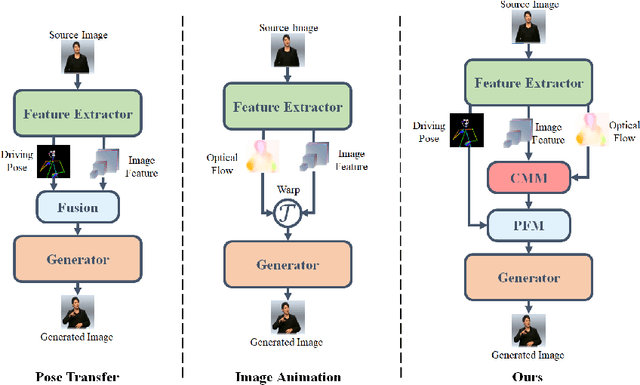
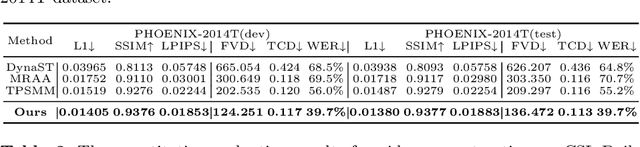
Sign language videos are an important medium for spreading and learning sign language. However, most existing human image synthesis methods produce sign language images with details that are distorted, blurred, or structurally incorrect. They also produce sign language video frames with poor temporal consistency, with anomalies such as flickering and abrupt detail changes between the previous and next frames. To address these limitations, we propose a novel Pose-Guided Motion Model (PGMM) for generating fine-grained and motion-consistent sign language videos. Firstly, we propose a new Coarse Motion Module (CMM), which completes the deformation of features by optical flow warping, thus transfering the motion of coarse-grained structures without changing the appearance; Secondly, we propose a new Pose Fusion Module (PFM), which guides the modal fusion of RGB and pose features, thus completing the fine-grained generation. Finally, we design a new metric, Temporal Consistency Difference (TCD) to quantitatively assess the degree of temporal consistency of a video by comparing the difference between the frames of the reconstructed video and the previous and next frames of the target video. Extensive qualitative and quantitative experiments show that our method outperforms state-of-the-art methods in most benchmark tests, with visible improvements in details and temporal consistency.
Improving Continuous Sign Language Recognition with Adapted Image Models
Apr 12, 2024



The increase of web-scale weakly labelled image-text pairs have greatly facilitated the development of large-scale vision-language models (e.g., CLIP), which have shown impressive generalization performance over a series of downstream tasks. However, the massive model size and scarcity of available data limit their applications to fine-tune the whole model in downstream tasks. Besides, fully fine-tuning the model easily forgets the generic essential knowledge acquired in the pretraining stage and overfits the downstream data. To enable high efficiency when adapting these large vision-language models (e.g., CLIP) to performing continuous sign language recognition (CSLR) while preserving their generalizability, we propose a novel strategy (AdaptSign). Especially, CLIP is adopted as the visual backbone to extract frame-wise features whose parameters are fixed, and a set of learnable modules are introduced to model spatial sign variations or capture temporal sign movements. The introduced additional modules are quite lightweight, only owning 3.2% extra computations with high efficiency. The generic knowledge acquired in the pretraining stage is well-preserved in the frozen CLIP backbone in this process. Extensive experiments show that despite being efficient, AdaptSign is able to demonstrate superior performance across a series of CSLR benchmarks including PHOENIX14, PHOENIX14-T, CSL-Daily and CSL compared to existing methods. Visualizations show that AdaptSign could learn to dynamically pay major attention to the informative spatial regions and cross-frame trajectories in sign videos.