 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSL-SSAW: Self-Supervised Learning with Sigmoid Self-Attention Weighting for Question-Based Sign Language Translation
Sep 17, 2025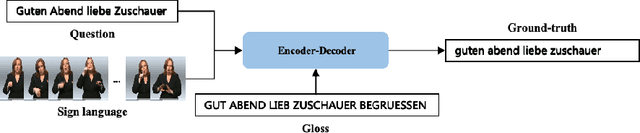
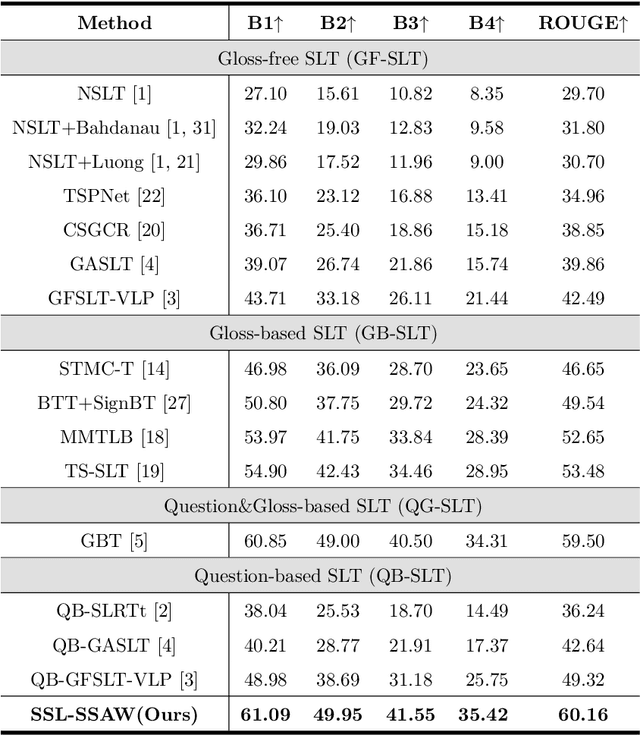
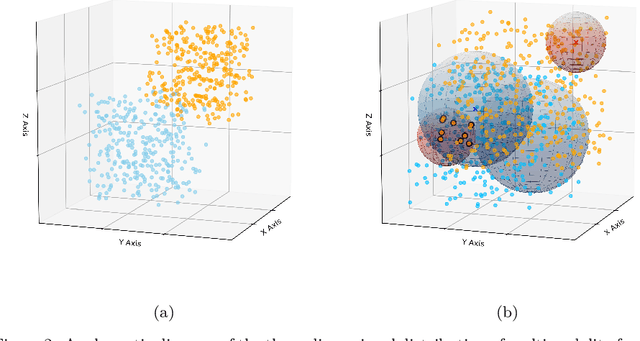
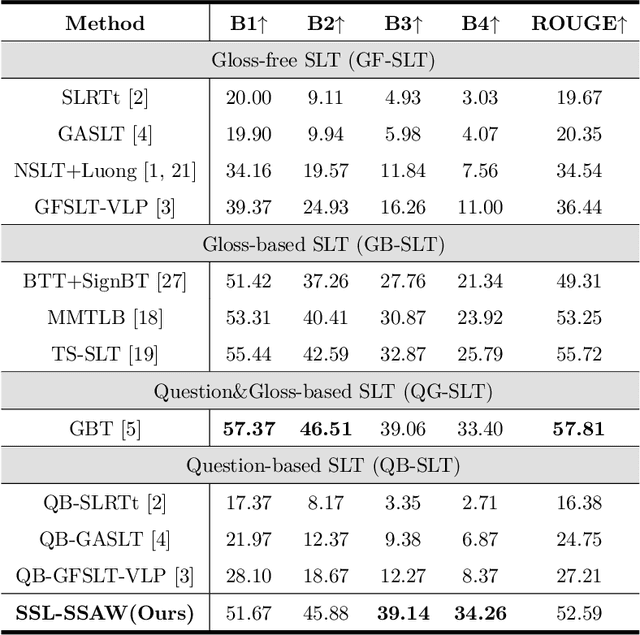
Sign Language Translation (SLT) bridges the communication gap between deaf people and hearing people, where dialogue provides crucial contextual cues to aid in translation. Building on this foundational concept, this paper proposes Question-based Sign Language Translation (QB-SLT), a novel task that explores the efficient integration of dialogue. Unlike gloss (sign language transcription) annotations, dialogue naturally occurs in communication and is easier to annotate. The key challenge lies in aligning multimodality features while leveraging the context of the question to improve translation. To address this issue, we propose a cross-modality Self-supervised Learning with Sigmoid Self-attention Weighting (SSL-SSAW) fusion method for sign language translation. Specifically, we employ contrastive learning to align multimodality features in QB-SLT, then introduce a Sigmoid Self-attention Weighting (SSAW) module for adaptive feature extraction from question and sign language sequences. Additionally, we leverage available question text through self-supervised learning to enhance representation and translation capabilities. We evaluated our approach on newly constructed CSL-Daily-QA and PHOENIX-2014T-QA datasets, where SSL-SSAW achieved SOTA performance. Notably, easily accessible question assistance can achieve or even surpass the performance of gloss assistance. Furthermore, visualization results demonstrate the effectiveness of incorporating dialogue in improving translation quality.
CorrNet+: Sign Language Recognition and Translation via Spatial-Temporal Correlation
Apr 17, 2024



In sign language, the conveyance of human body trajectories predominantly relies upon the coordinated movements of hands and facial expressions across successive frames. Despite the recent advancements of sign language understanding methods, they often solely focus on individual frames, inevitably overlooking the inter-frame correlations that are essential for effectively modeling human body trajectories. To address this limitation, this paper introduces a spatial-temporal correlation network, denoted as CorrNet+, which explicitly identifies body trajectories across multiple frames. In specific, CorrNet+ employs a correlation module and an identification module to build human body trajectories. Afterwards, a temporal attention module is followed to adaptively evaluate the contributions of different frames. The resultant features offer a holistic perspective on human body movements, facilitating a deeper understanding of sign language. As a unified model, CorrNet+ achieves new state-of-the-art performance on two extensive sign language understanding tasks, including continuous sign language recognition (CSLR) and sign language translation (SLT). Especially, CorrNet+ surpasses previous methods equipped with resource-intensive pose-estimation networks or pre-extracted heatmaps for hand and facial feature extraction. Compared with CorrNet, CorrNet+ achieves a significant performance boost across all benchmarks while halving the computational overhead. A comprehensive comparison with previous spatial-temporal reasoning methods verifies the superiority of CorrNet+. Code is available at https://github.com/hulianyuyy/CorrNet_Plus.
Improving Continuous Sign Language Recognition with Adapted Image Models
Apr 12, 2024



The increase of web-scale weakly labelled image-text pairs have greatly facilitated the development of large-scale vision-language models (e.g., CLIP), which have shown impressive generalization performance over a series of downstream tasks. However, the massive model size and scarcity of available data limit their applications to fine-tune the whole model in downstream tasks. Besides, fully fine-tuning the model easily forgets the generic essential knowledge acquired in the pretraining stage and overfits the downstream data. To enable high efficiency when adapting these large vision-language models (e.g., CLIP) to performing continuous sign language recognition (CSLR) while preserving their generalizability, we propose a novel strategy (AdaptSign). Especially, CLIP is adopted as the visual backbone to extract frame-wise features whose parameters are fixed, and a set of learnable modules are introduced to model spatial sign variations or capture temporal sign movements. The introduced additional modules are quite lightweight, only owning 3.2% extra computations with high efficiency. The generic knowledge acquired in the pretraining stage is well-preserved in the frozen CLIP backbone in this process. Extensive experiments show that despite being efficient, AdaptSign is able to demonstrate superior performance across a series of CSLR benchmarks including PHOENIX14, PHOENIX14-T, CSL-Daily and CSL compared to existing methods. Visualizations show that AdaptSign could learn to dynamically pay major attention to the informative spatial regions and cross-frame trajectories in sign videos.
Dynamic Spatial-Temporal Aggregation for Skeleton-Aware Sign Language Recognition
Mar 19, 2024



Skeleton-aware sign language recognition (SLR) has gained popularity due to its ability to remain unaffected by background information and its lower computational requirements. Current methods utilize spatial graph modules and temporal modules to capture spatial and temporal features, respectively. However, their spatial graph modules are typically built on fixed graph structures such as graph convolutional networks or a single learnable graph, which only partially explore joint relationships. Additionally, a simple temporal convolution kernel is used to capture temporal information, which may not fully capture the complex movement patterns of different signers. To overcome these limitations, we propose a new spatial architecture consisting of two concurrent branches, which build input-sensitive joint relationships and incorporates specific domain knowledge for recognition, respectively. These two branches are followed by an aggregation process to distinguishe important joint connections. We then propose a new temporal module to model multi-scale temporal information to capture complex human dynamics. Our method achieves state-of-the-art accuracy compared to previous skeleton-aware methods on four large-scale SLR benchmarks. Moreover, our method demonstrates superior accuracy compared to RGB-based methods in most cases while requiring much fewer computational resources, bringing better accuracy-computation trade-off. Code is available at https://github.com/hulianyuyy/DSTA-SLR.
COMMA: Co-Articulated Multi-Modal Learning
Dec 30, 2023



Pretrained large-scale vision-language models such as CLIP have demonstrated excellent generalizability over a series of downstream tasks. However, they are sensitive to the variation of input text prompts and need a selection of prompt templates to achieve satisfactory performance. Recently, various methods have been proposed to dynamically learn the prompts as the textual inputs to avoid the requirements of laboring hand-crafted prompt engineering in the fine-tuning process. We notice that these methods are suboptimal in two aspects. First, the prompts of the vision and language branches in these methods are usually separated or uni-directionally correlated. Thus, the prompts of both branches are not fully correlated and may not provide enough guidance to align the representations of both branches. Second, it's observed that most previous methods usually achieve better performance on seen classes but cause performance degeneration on unseen classes compared to CLIP. This is because the essential generic knowledge learned in the pretraining stage is partly forgotten in the fine-tuning process. In this paper, we propose Co-Articulated Multi-Modal Learning (COMMA) to handle the above limitations. Especially, our method considers prompts from both branches to generate the prompts to enhance the representation alignment of both branches. Besides, to alleviate forgetting about the essential knowledge, we minimize the feature discrepancy between the learned prompts and the embeddings of hand-crafted prompts in the pre-trained CLIP in the late transformer layers. We evaluate our method across three representative tasks of generalization to novel classes, new target datasets and unseen domain shifts. Experimental results demonstrate the superiority of our method by exhibiting a favorable performance boost upon all tasks with high efficiency.
AdaBrowse: Adaptive Video Browser for Efficient Continuous Sign Language Recognition
Aug 16, 2023

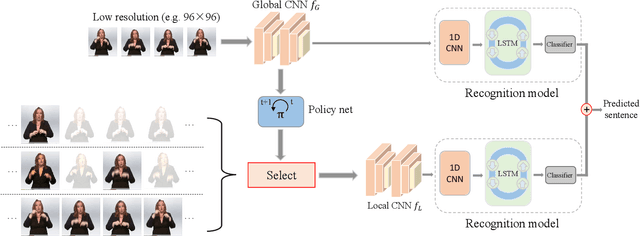

Raw videos have been proven to own considerable feature redundancy where in many cases only a portion of frames can already meet the requirements for accurate recognition. In this paper, we are interested in whether such redundancy can be effectively leveraged to facilitate efficient inference in continuous sign language recognition (CSLR). We propose a novel adaptive model (AdaBrowse) to dynamically select a most informative subsequence from input video sequences by modelling this problem as a sequential decision task. In specific, we first utilize a lightweight network to quickly scan input videos to extract coarse features. Then these features are fed into a policy network to intelligently select a subsequence to process. The corresponding subsequence is finally inferred by a normal CSLR model for sentence prediction. As only a portion of frames are processed in this procedure, the total computations can be considerably saved. Besides temporal redundancy, we are also interested in whether the inherent spatial redundancy can be seamlessly integrated together to achieve further efficiency, i.e., dynamically selecting a lowest input resolution for each sample, whose model is referred to as AdaBrowse+. Extensive experimental results on four large-scale CSLR datasets, i.e., PHOENIX14, PHOENIX14-T, CSL-Daily and CSL, demonstrate the effectiveness of AdaBrowse and AdaBrowse+ by achieving comparable accuracy with state-of-the-art methods with 1.44$\times$ throughput and 2.12$\times$ fewer FLOPs. Comparisons with other commonly-used 2D CNNs and adaptive efficient methods verify the effectiveness of AdaBrowse. Code is available at \url{https://github.com/hulianyuyy/AdaBrowse}.
Continuous Sign Language Recognition with Correlation Network
Mar 18, 2023Human body trajectories are a salient cue to identify actions in the video. Such body trajectories are mainly conveyed by hands and face across consecutive frames in sign language. However, current methods in continuous sign language recognition (CSLR) usually process frames independently, thus failing to capture cross-frame trajectories to effectively identify a sign. To handle this limitation, we propose correlation network (CorrNet) to explicitly capture and leverage body trajectories across frames to identify signs. In specific, a correlation module is first proposed to dynamically compute correlation maps between the current frame and adjacent frames to identify trajectories of all spatial patches. An identification module is then presented to dynamically emphasize the body trajectories within these correlation maps. As a result, the generated features are able to gain an overview of local temporal movements to identify a sign. Thanks to its special attention on body trajectories, CorrNet achieves new state-of-the-art accuracy on four large-scale datasets, i.e., PHOENIX14, PHOENIX14-T, CSL-Daily, and CSL. A comprehensive comparison with previous spatial-temporal reasoning methods verifies the effectiveness of CorrNet. Visualizations demonstrate the effects of CorrNet on emphasizing human body trajectories across adjacent frames.
Temporal Lift Pooling for Continuous Sign Language Recognition
Jul 18, 2022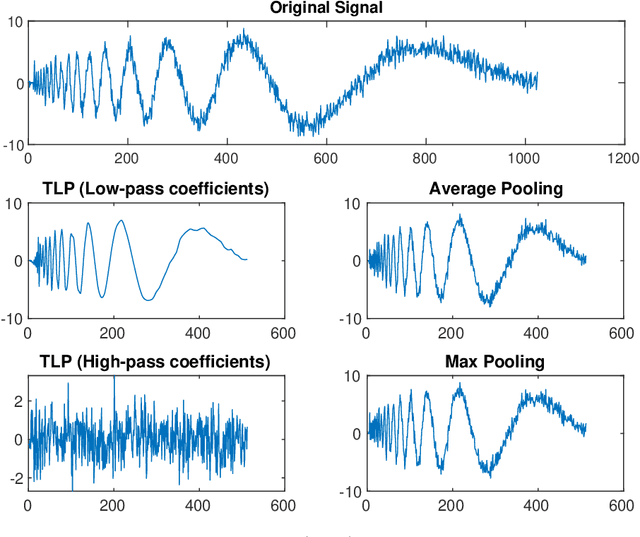
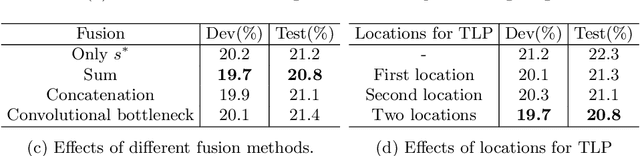

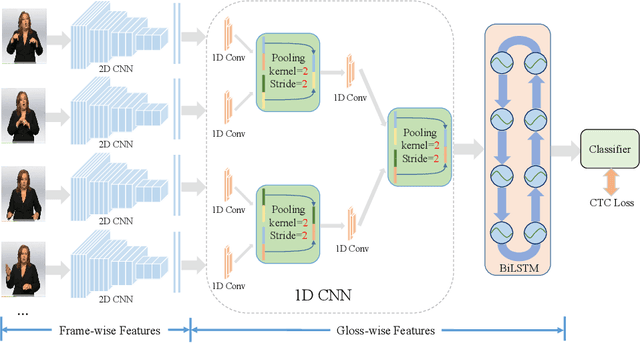
Pooling methods are necessities for modern neural networks for increasing receptive fields and lowering down computational costs. However, commonly used hand-crafted pooling approaches, e.g., max pooling and average pooling, may not well preserve discriminative features. While many researchers have elaborately designed various pooling variants in spatial domain to handle these limitations with much progress, the temporal aspect is rarely visited where directly applying hand-crafted methods or these specialized spatial variants may not be optimal. In this paper, we derive temporal lift pooling (TLP) from the Lifting Scheme in signal processing to intelligently downsample features of different temporal hierarchies. The Lifting Scheme factorizes input signals into various sub-bands with different frequency, which can be viewed as different temporal movement patterns. Our TLP is a three-stage procedure, which performs signal decomposition, component weighting and information fusion to generate a refined downsized feature map. We select a typical temporal task with long sequences, i.e. continuous sign language recognition (CSLR), as our testbed to verify the effectiveness of TLP. Experiments on two large-scale datasets show TLP outperforms hand-crafted methods and specialized spatial variants by a large margin (1.5%) with similar computational overhead. As a robust feature extractor, TLP exhibits great generalizability upon multiple backbones on various datasets and achieves new state-of-the-art results on two large-scale CSLR datasets. Visualizations further demonstrate the mechanism of TLP in correcting gloss borders. Code is released.