 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaBrowse: Adaptive Video Browser for Efficient Continuous Sign Language Recognition
Paper and Code


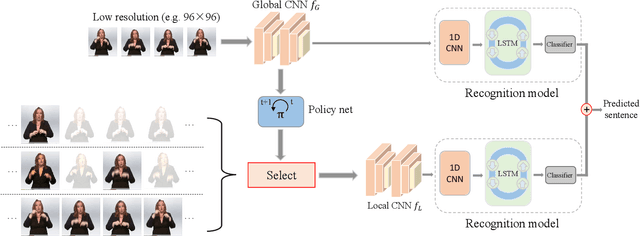

Raw videos have been proven to own considerable feature redundancy where in many cases only a portion of frames can already meet the requirements for accurate recognition. In this paper, we are interested in whether such redundancy can be effectively leveraged to facilitate efficient inference in continuous sign language recognition (CSLR). We propose a novel adaptive model (AdaBrowse) to dynamically select a most informative subsequence from input video sequences by modelling this problem as a sequential decision task. In specific, we first utilize a lightweight network to quickly scan input videos to extract coarse features. Then these features are fed into a policy network to intelligently select a subsequence to process. The corresponding subsequence is finally inferred by a normal CSLR model for sentence prediction. As only a portion of frames are processed in this procedure, the total computations can be considerably saved. Besides temporal redundancy, we are also interested in whether the inherent spatial redundancy can be seamlessly integrated together to achieve further efficiency, i.e., dynamically selecting a lowest input resolution for each sample, whose model is referred to as AdaBrowse+. Extensive experimental results on four large-scale CSLR datasets, i.e., PHOENIX14, PHOENIX14-T, CSL-Daily and CSL, demonstrate the effectiveness of AdaBrowse and AdaBrowse+ by achieving comparable accuracy with state-of-the-art methods with 1.44$\times$ throughput and 2.12$\times$ fewer FLOPs. Comparisons with other commonly-used 2D CNNs and adaptive efficient methods verify the effectiveness of AdaBrowse. Code is available at \url{https://github.com/hulianyuyy/AdaBrowse}.