 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Heterogeneous Multi-Modal Remote Sensing Detection Via Language-Pivoted Pretraining
Mar 02, 2026Heterogeneous multi-modal remote sensing object detection aims to accurately detect objects from diverse sensors (e.g., RGB, SAR, Infrared). Existing approaches largely adopt a late alignment paradigm, in which modality alignment and task-specific optimization are entangled during downstream fine-tuning. This tight coupling complicates optimization and often results in unstable training and suboptimal generalization. To address these limitations, we propose BabelRS, a unified language-pivoted pretraining framework that explicitly decouples modality alignment from downstream task learning. BabelRS comprises two key components: Concept-Shared Instruction Aligning (CSIA) and Layerwise Visual-Semantic Annealing (LVSA). CSIA aligns each sensor modality to a shared set of linguistic concepts, using language as a semantic pivot to bridge heterogeneous visual representations. To further mitigate the granularity mismatch between high-level language representations and dense detection objectives, LVSA progressively aggregates multi-scale visual features to provide fine-grained semantic guidance. Extensive experiments demonstrate that BabelRS stabilizes training and consistently outperforms state-of-the-art methods without bells and whistles. Code: https://github.com/zcablii/SM3Det.
Locomotion Beyond Feet
Jan 07, 2026Most locomotion methods for humanoid robots focus on leg-based gaits, yet natural bipeds frequently rely on hands, knees, and elbows to establish additional contacts for stability and support in complex environments. This paper introduces Locomotion Beyond Feet, a comprehensive system for whole-body humanoid locomotion across extremely challenging terrains, including low-clearance spaces under chairs, knee-high walls, knee-high platforms, and steep ascending and descending stairs. Our approach addresses two key challenges: contact-rich motion planning and generalization across diverse terrains. To this end, we combine physics-grounded keyframe animation with reinforcement learning. Keyframes encode human knowledge of motor skills, are embodiment-specific, and can be readily validated in simulation or on hardware, while reinforcement learning transforms these references into robust, physically accurate motions. We further employ a hierarchical framework consisting of terrain-specific motion-tracking policies, failure recovery mechanisms, and a vision-based skill planner. Real-world experiments demonstrate that Locomotion Beyond Feet achieves robust whole-body locomotion and generalizes across obstacle sizes, obstacle instances, and terrain sequences.
OmniSegmentor: A Flexible Multi-Modal Learning Framework for Semantic Segmentation
Sep 18, 2025Recent research on representation learning has proved the merits of multi-modal clues for robust semantic segmentation. Nevertheless, a flexible pretrain-and-finetune pipeline for multiple visual modalities remains unexplored. In this paper, we propose a novel multi-modal learning framework, termed OmniSegmentor. It has two key innovations: 1) Based on ImageNet, we assemble a large-scale dataset for multi-modal pretraining, called ImageNeXt, which contains five popular visual modalities. 2) We provide an efficient pretraining manner to endow the model with the capacity to encode different modality information in the ImageNeXt. For the first time, we introduce a universal multi-modal pretraining framework that consistently amplifies the model's perceptual capabilities across various scenarios, regardless of the arbitrary combination of the involved modalities. Remarkably, our OmniSegmentor achieves new state-of-the-art records on a wide range of multi-modal semantic segmentation datasets, including NYU Depthv2, EventScape, MFNet, DeLiVER, SUNRGBD, and KITTI-360.
Re-Aligning Language to Visual Objects with an Agentic Workflow
Mar 30, 2025Language-based object detection (LOD) aims to align visual objects with language expressions. A large amount of paired data is utilized to improve LOD model generalizations. During the training process, recent studies leverage vision-language models (VLMs) to automatically generate human-like expressions for visual objects, facilitating training data scaling up. In this process, we observe that VLM hallucinations bring inaccurate object descriptions (e.g., object name, color, and shape) to deteriorate VL alignment quality. To reduce VLM hallucinations, we propose an agentic workflow controlled by an LLM to re-align language to visual objects via adaptively adjusting image and text prompts. We name this workflow Real-LOD, which includes planning, tool use, and reflection steps. Given an image with detected objects and VLM raw language expressions, Real-LOD reasons its state automatically and arranges action based on our neural symbolic designs (i.e., planning). The action will adaptively adjust the image and text prompts and send them to VLMs for object re-description (i.e., tool use). Then, we use another LLM to analyze these refined expressions for feedback (i.e., reflection). These steps are conducted in a cyclic form to gradually improve language descriptions for re-aligning to visual objects. We construct a dataset that contains a tiny amount of 0.18M images with re-aligned language expression and train a prevalent LOD model to surpass existing LOD methods by around 50% on the standard benchmarks. Our Real-LOD workflow, with automatic VL refinement, reveals a potential to preserve data quality along with scaling up data quantity, which further improves LOD performance from a data-alignment perspective.
TeMO: Towards Text-Driven 3D Stylization for Multi-Object Meshes
Dec 07, 2023Recent progress in the text-driven 3D stylization of a single object has been considerably promoted by CLIP-based methods. However, the stylization of multi-object 3D scenes is still impeded in that the image-text pairs used for pre-training CLIP mostly consist of an object. Meanwhile, the local details of multiple objects may be susceptible to omission due to the existing supervision manner primarily relying on coarse-grained contrast of image-text pairs. To overcome these challenges, we present a novel framework, dubbed TeMO, to parse multi-object 3D scenes and edit their styles under the contrast supervision at multiple levels. We first propose a Decoupled Graph Attention (DGA) module to distinguishably reinforce the features of 3D surface points. Particularly, a cross-modal graph is constructed to align the object points accurately and noun phrases decoupled from the 3D mesh and textual description. Then, we develop a Cross-Grained Contrast (CGC) supervision system, where a fine-grained loss between the words in the textual description and the randomly rendered images are constructed to complement the coarse-grained loss. Extensive experiments show that our method can synthesize high-quality stylized content and outperform the existing methods over a wide range of multi-object 3D meshes. Our code and results will be made publicly available
Zone Evaluation: Revealing Spatial Bias in Object Detection
Oct 20, 2023
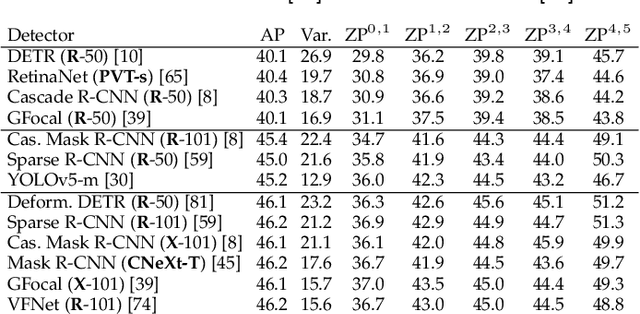
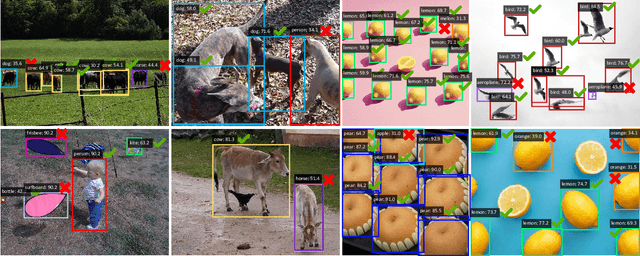
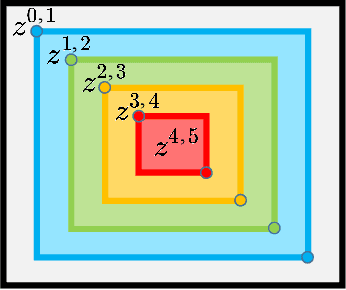
A fundamental limitation of object detectors is that they suffer from "spatial bias", and in particular perform less satisfactorily when detecting objects near image borders. For a long time, there has been a lack of effective ways to measure and identify spatial bias, and little is known about where it comes from and what degree it is. To this end, we present a new zone evaluation protocol, extending from the traditional evaluation to a more generalized one, which measures the detection performance over zones, yielding a series of Zone Precisions (ZPs). For the first time, we provide numerical results, showing that the object detectors perform quite unevenly across the zones. Surprisingly, the detector's performance in the 96\% border zone of the image does not reach the AP value (Average Precision, commonly regarded as the average detection performance in the entire image zone). To better understand spatial bias, a series of heuristic experiments are conducted. Our investigation excludes two intuitive conjectures about spatial bias that the object scale and the absolute positions of objects barely influence the spatial bias. We find that the key lies in the human-imperceptible divergence in data patterns between objects in different zones, thus eventually forming a visible performance gap between the zones. With these findings, we finally discuss a future direction for object detection, namely, spatial disequilibrium problem, aiming at pursuing a balanced detection ability over the entire image zone. By broadly evaluating 10 popular object detectors and 5 detection datasets, we shed light on the spatial bias of object detectors. We hope this work could raise a focus on detection robustness. The source codes, evaluation protocols, and tutorials are publicly available at \url{https://github.com/Zzh-tju/ZoneEval}.
YOLO-MS: Rethinking Multi-Scale Representation Learning for Real-time Object Detection
Aug 10, 2023



We aim at providing the object detection community with an efficient and performant object detector, termed YOLO-MS. The core design is based on a series of investigations on how convolutions with different kernel sizes affect the detection performance of objects at different scales. The outcome is a new strategy that can strongly enhance multi-scale feature representations of real-time object detectors. To verify the effectiveness of our strategy, we build a network architecture, termed YOLO-MS. We train our YOLO-MS on the MS COCO dataset from scratch without relying on any other large-scale datasets, like ImageNet, or pre-trained weights. Without bells and whistles, our YOLO-MS outperforms the recent state-of-the-art real-time object detectors, including YOLO-v7 and RTMDet, when using a comparable number of parameters and FLOPs. Taking the XS version of YOLO-MS as an example, with only 4.5M learnable parameters and 8.7G FLOPs, it can achieve an AP score of 43%+ on MS COCO, which is about 2%+ higher than RTMDet with the same model size. Moreover, our work can also be used as a plug-and-play module for other YOLO models. Typically, our method significantly improves the AP of YOLOv8 from 37%+ to 40%+ with even fewer parameters and FLOPs. Code is available at https://github.com/FishAndWasabi/YOLO-MS.
CrossKD: Cross-Head Knowledge Distillation for Dense Object Detection
Jun 20, 2023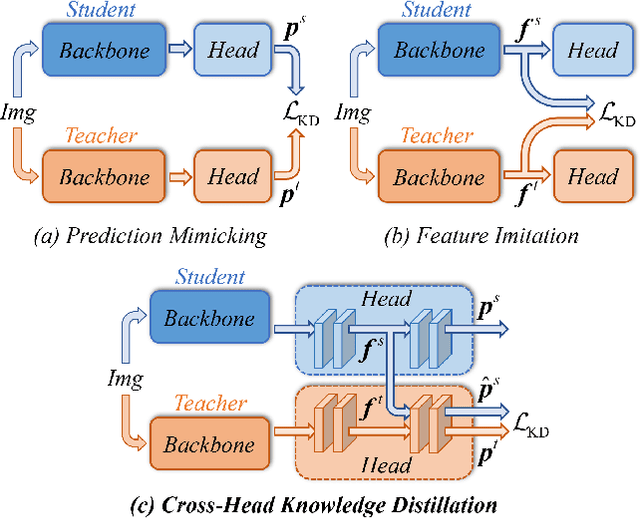
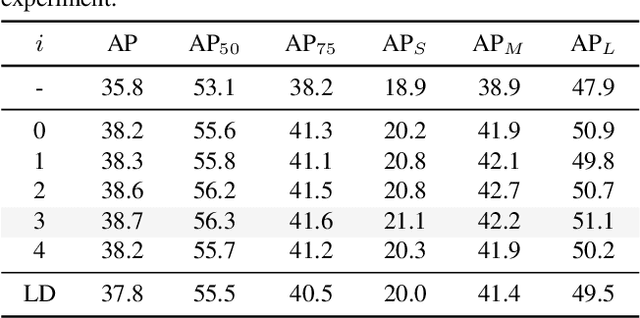


Knowledge Distillation (KD) has been validated as an effective model compression technique for learning compact object detectors. Existing state-of-the-art KD methods for object detection are mostly based on feature imitation, which is generally observed to be better than prediction mimicking. In this paper, we show that the inconsistency of the optimization objectives between the ground-truth signals and distillation targets is the key reason for the inefficiency of prediction mimicking. To alleviate this issue, we present a simple yet effective distillation scheme, termed CrossKD, which delivers the intermediate features of the student's detection head to the teacher's detection head. The resulting cross-head predictions are then forced to mimic the teacher's predictions. Such a distillation manner relieves the student's head from receiving contradictory supervision signals from the ground-truth annotations and the teacher's predictions, greatly improving the student's detection performance. On MS COCO, with only prediction mimicking losses applied, our CrossKD boosts the average precision of GFL ResNet-50 with 1x training schedule from 40.2 to 43.7, outperforming all existing KD methods for object detection. Code is available at https://github.com/jbwang1997/CrossKD.
Reduced-Order Autodifferentiable Ensemble Kalman Filters
Jan 27, 2023This paper introduces a computational framework to reconstruct and forecast a partially observed state that evolves according to an unknown or expensive-to-simulate dynamical system. Our reduced-order autodifferentiable ensemble Kalman filters (ROAD-EnKFs) learn a latent low-dimensional surrogate model for the dynamics and a decoder that maps from the latent space to the state space. The learned dynamics and decoder are then used within an ensemble Kalman filter to reconstruct and forecast the state. Numerical experiments show that if the state dynamics exhibit a hidden low-dimensional structure, ROAD-EnKFs achieve higher accuracy at lower computational cost compared to existing methods. If such structure is not expressed in the latent state dynamics, ROAD-EnKFs achieve similar accuracy at lower cost, making them a promising approach for surrogate state reconstruction and forecasting.
Towards Spatial Equilibrium Object Detection
Jan 14, 2023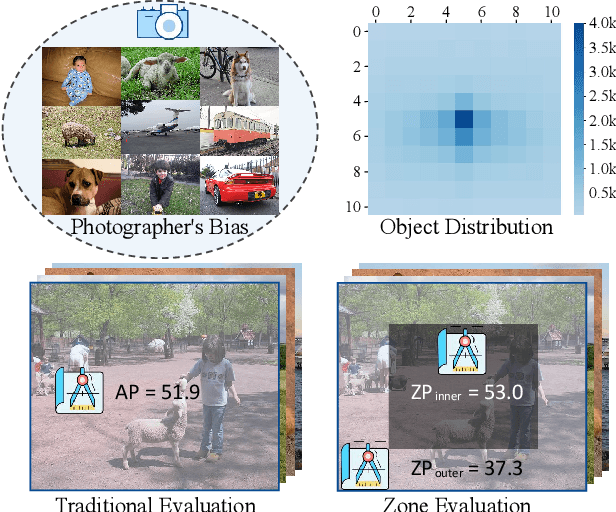



Semantic objects are unevenly distributed over images. In this paper, we study the spatial disequilibrium problem of modern object detectors and propose to quantify this ``spatial bias'' by measuring the detection performance over zones. Our analysis surprisingly shows that the spatial imbalance of objects has a great impact on the detection performance, limiting the robustness of detection applications. This motivates us to design a more generalized measurement, termed Spatial equilibrium Precision (SP), to better characterize the detection performance of object detectors. Furthermore, we also present a spatial equilibrium label assignment (SELA) to alleviate the spatial disequilibrium problem by injecting the prior spatial weight into the optimization process of detectors. Extensive experiments on PASCAL VOC, MS COCO, and 3 application datasets on face mask/fruit/helmet images demonstrate the advantages of our method. Our findings challenge the conventional sense of object detectors and show the indispensability of spatial equilibrium. We hope these discoveries would stimulate the community to rethink how an excellent object detector should be. All the source code, evaluation protocols, and the tutorials are publicly available at https://github.com/Zzh-tju/ZoneEval