 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Multiscale Learning of Linear Operators
Jun 15, 2026We study the statistical and computational limits of learning bounded linear operators between Sobolev spaces from noisy input-output data. In wavelet coordinates, the problem is recast as an infinite-dimensional matrix regression problem with a heterogeneous two-sided multiscale structure. We establish minimax rates under Sobolev operator-norm loss and construct a finite-resolution blockwise least-squares estimator attaining these rates. The analysis reveals a nonuniform local estimation difficulty across scales, which can be exploited algorithmically: by assigning scale-adaptive sample sizes, the estimator achieves the optimal computational cost among dense least-squares implementations.
Continuous Data Assimilation with Learned Surrogate Dynamics
May 30, 2026Continuous data assimilation seeks to estimate the state of a dynamical system from partial observations. In many applications, however, the state dynamics are unknown or prohibitively expensive to simulate at the required resolution, leading to model error. Motivated by this challenge and the increasing adoption of machine learning surrogates in data assimilation, this paper develops a unified finite-dimensional analysis of nudging algorithms that employ learned surrogate models of the dynamics. We first establish general conditions on the dynamics and observations that guarantee accurate tracking for nudging with the true dynamics model, both in the noise-free and noisy settings. We then show that nudging algorithms that employ surrogate models retain exponential convergence up to an explicit error floor that quantifies the effects of surrogate approximation error and observation noise. Finally, we analyze surrogate models obtained by learning either the vector field or the short-time solution map of the system, and quantify the amount of training data needed to ensure accurate nudging in the noise-free setting. Numerical experiments support the theory.
Functional Multi-Target Detection via Bispectrum Inversion
May 29, 2026This paper develops a functional theory for multi-target detection, where a compactly supported signal is recovered from a single noisy observation containing many unknown translations of the signal. Our formulation allows continuous, off-grid translations and correlated stationary Gaussian process noise, extending beyond the discrete, grid-aligned, white-noise models common in prior work. We analyze two uninitialized recovery algorithms based on autocorrelation analysis; in particular, both algorithms first estimate the signal's bispectrum via a debiased third-order empirical autocorrelation. The signal is then recovered from the estimated bispectrum using either a functional frequency marching scheme or a Kotlarski-type deconvolution formula. For both algorithms, we prove non-asymptotic recovery guarantees for compactly supported signals without bandlimiting assumptions. The resulting error bounds depend on the smoothness of the signal and the accuracy of bispectrum estimation, with the latter governed by the noise characteristics and the number of signal occurrences. Numerical experiments validate our theory and demonstrate accurate recovery in low-SNR regimes.
Auto-differentiable data assimilation: Co-learning of states, dynamics, and filtering algorithms
Mar 21, 2026Data assimilation algorithms estimate the state of a dynamical system from partial observations, where the successful performance of these algorithms hinges on costly parameter tuning and on employing an accurate model for the dynamics. This paper introduces a framework for jointly learning the state, dynamics, and parameters of filtering algorithms in data assimilation through a process we refer to as auto-differentiable filtering. The framework leverages a theoretically motivated loss function that enables learning from partial, noisy observations via gradient-based optimization using auto-differentiation. We further demonstrate how several well-known data assimilation methods can be learned or tuned within this framework. To underscore the versatility of auto-differentiable filtering, we perform experiments on dynamical systems spanning multiple scientific domains, such as the Clohessy-Wiltshire equations from aerospace engineering, the Lorenz-96 system from atmospheric science, and the generalized Lotka-Volterra equations from systems biology. Finally, we provide guidelines for practitioners to customize our framework according to their observation model, accuracy requirements, and computational budget.
Convergence Rates for Learning Pseudo-Differential Operators
Jan 08, 2026This paper establishes convergence rates for learning elliptic pseudo-differential operators, a fundamental operator class in partial differential equations and mathematical physics. In a wavelet-Galerkin framework, we formulate learning over this class as a structured infinite-dimensional regression problem with multiscale sparsity. Building on this structure, we propose a sparse, data- and computation-efficient estimator, which leverages a novel matrix compression scheme tailored to the learning task and a nested-support strategy to balance approximation and estimation errors. In addition to obtaining convergence rates for the estimator, we show that the learned operator induces an efficient and stable Galerkin solver whose numerical error matches its statistical accuracy. Our results therefore contribute to bringing together operator learning, data-driven solvers, and wavelet methods in scientific computing.
Bayesian Optimization on Networks
Oct 31, 2025This paper studies optimization on networks modeled as metric graphs. Motivated by applications where the objective function is expensive to evaluate or only available as a black box, we develop Bayesian optimization algorithms that sequentially update a Gaussian process surrogate model of the objective to guide the acquisition of query points. To ensure that the surrogates are tailored to the network's geometry, we adopt Whittle-Mat\'ern Gaussian process prior models defined via stochastic partial differential equations on metric graphs. In addition to establishing regret bounds for optimizing sufficiently smooth objective functions, we analyze the practical case in which the smoothness of the objective is unknown and the Whittle-Mat\'ern prior is represented using finite elements. Numerical results demonstrate the effectiveness of our algorithms for optimizing benchmark objective functions on a synthetic metric graph and for Bayesian inversion via maximum a posteriori estimation on a telecommunication network.
Functional Multi-Reference Alignment via Deconvolution
Jun 13, 2025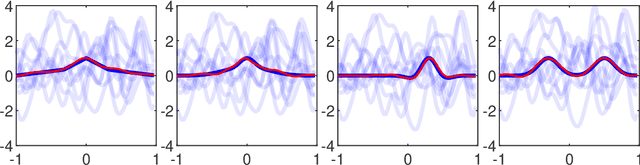

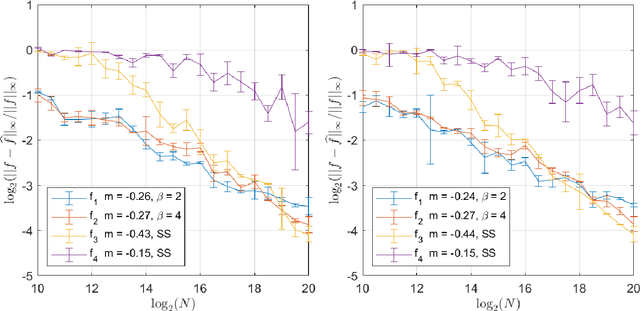
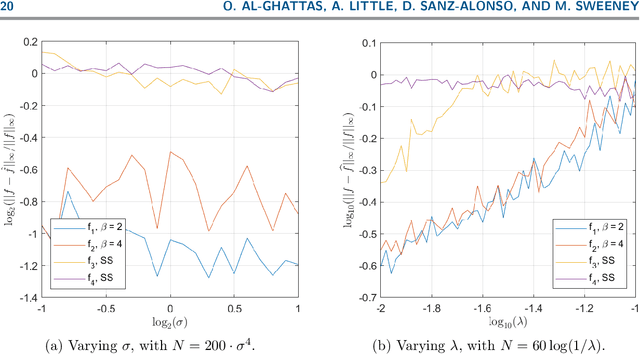
This paper studies the multi-reference alignment (MRA) problem of estimating a signal function from shifted, noisy observations. Our functional formulation reveals a new connection between MRA and deconvolution: the signal can be estimated from second-order statistics via Kotlarski's formula, an important identification result in deconvolution with replicated measurements. To design our MRA algorithms, we extend Kotlarski's formula to general dimension and study the estimation of signals with vanishing Fourier transform, thus also contributing to the deconvolution literature. We validate our deconvolution approach to MRA through both theory and numerical experiments.
Long-time accuracy of ensemble Kalman filters for chaotic and machine-learned dynamical systems
Dec 18, 2024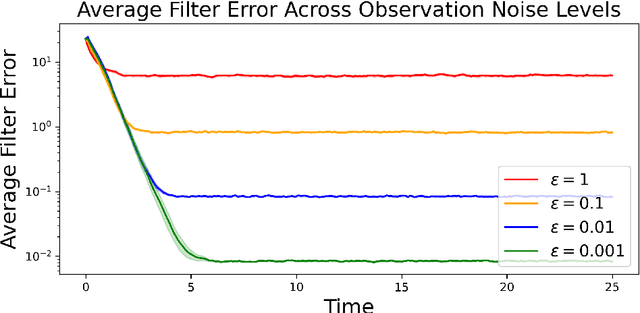


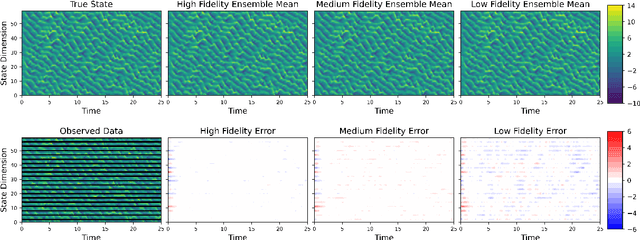
Filtering is concerned with online estimation of the state of a dynamical system from partial and noisy observations. In applications where the state is high dimensional, ensemble Kalman filters are often the method of choice. This paper establishes long-time accuracy of ensemble Kalman filters. We introduce conditions on the dynamics and the observations under which the estimation error remains small in the long-time horizon. Our theory covers a wide class of partially-observed chaotic dynamical systems, which includes the Navier-Stokes equations and Lorenz models. In addition, we prove long-time accuracy of ensemble Kalman filters with surrogate dynamics, thus validating the use of machine-learned forecast models in ensemble data assimilation.
Inverse Problems and Data Assimilation: A Machine Learning Approach
Oct 14, 2024The aim of these notes is to demonstrate the potential for ideas in machine learning to impact on the fields of inverse problems and data assimilation. The perspective is one that is primarily aimed at researchers from inverse problems and/or data assimilation who wish to see a mathematical presentation of machine learning as it pertains to their fields. As a by-product, we include a succinct mathematical treatment of various topics in machine learning.
Data Assimilation with Machine Learning Surrogate Models: A Case Study with FourCastNet
May 21, 2024Modern data-driven surrogate models for weather forecasting provide accurate short-term predictions but inaccurate and nonphysical long-term forecasts. This paper investigates online weather prediction using machine learning surrogates supplemented with partial and noisy observations. We empirically demonstrate and theoretically justify that, despite the long-time instability of the surrogates and the sparsity of the observations, filtering estimates can remain accurate in the long-time horizon. As a case study, we integrate FourCastNet, a state-of-the-art weather surrogate model, within a variational data assimilation framework using partial, noisy ERA5 data. Our results show that filtering estimates remain accurate over a year-long assimilation window and provide effective initial conditions for forecasting tasks, including extreme event prediction.