 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunctional Multi-Target Detection via Bispectrum Inversion
May 29, 2026This paper develops a functional theory for multi-target detection, where a compactly supported signal is recovered from a single noisy observation containing many unknown translations of the signal. Our formulation allows continuous, off-grid translations and correlated stationary Gaussian process noise, extending beyond the discrete, grid-aligned, white-noise models common in prior work. We analyze two uninitialized recovery algorithms based on autocorrelation analysis; in particular, both algorithms first estimate the signal's bispectrum via a debiased third-order empirical autocorrelation. The signal is then recovered from the estimated bispectrum using either a functional frequency marching scheme or a Kotlarski-type deconvolution formula. For both algorithms, we prove non-asymptotic recovery guarantees for compactly supported signals without bandlimiting assumptions. The resulting error bounds depend on the smoothness of the signal and the accuracy of bispectrum estimation, with the latter governed by the noise characteristics and the number of signal occurrences. Numerical experiments validate our theory and demonstrate accurate recovery in low-SNR regimes.
TrajPrism: A Multi-Task Benchmark for Language-Grounded Urban Trajectory Understanding
May 11, 2026Urban mobility is naturally expressed both as trajectories in space and as natural-language descriptions of travel intent, constraints, and preferences. However, prior work rarely evaluates these two modalities together on the same real-world trajectories: trajectory modeling often stays geometry-centric, while language-centric mobility benchmarks frequently target route planning and tool use rather than fine-grained, verifiable alignment between text and the underlying route. We introduce TrajPrism, a multi-task benchmark for language-trajectory alignment that unifies (i) instruction-conditioned trajectory generation, (ii) language-driven semantic trajectory retrieval, and (iii) trajectory captioning, together with an evaluation protocol that measures trajectory fidelity, retrieval quality, and language groundedness. We construct TrajPrism by pairing real urban trajectories with judge-filtered language annotations generated under a four-dimensional travel-intent taxonomy. The benchmark contains 300K selected trajectories across Porto, San Francisco, and Beijing, yielding 2.1M task instances from three instruction variants, three retrieval queries, and one caption per trajectory. We further develop proof-of-concept models for each task: TrajAnchor for instruction-conditioned trajectory generation, TrajFuse for semantic trajectory retrieval, and TrajRap for trajectory captioning. These models instantiate the proposed tasks and show that geometry-only trajectory baselines leave a large gap on our protocol, especially where language is part of the input-output interface. We release TrajPrism with code and a reproducible annotation pipeline that is designed to be portable across cities, given compatible trajectory inputs and map resources.
MAGE: Multi-Agent Self-Evolution with Co-Evolutionary Knowledge Graphs
May 11, 2026Self-evolving language-model agents must decide what to learn next and how to preserve what they have learned across iterations. Existing systems typically carry this cross-iteration knowledge as natural-language feedback, flat episodic memory, or implicit reinforcement signals, none of which cleanly supports a frozen weak backbone at inference time. This paper introduces MAGE (Multi-Agent Graph-guided Evolution), a framework that externalizes self-knowledge into a four-subgraph co-evolutionary knowledge graph. Its experience subgraph stores both teacher-written failure corrections and the learner's own past correct reasoning traces, which are retrieved as task-conditioned guidance for a frozen execution model. During evolution, the graph, a task-level search bandit, and a skill-level routing bandit are updated from the same reward stream, while the learner's backbone remains unchanged. We further provide structural analysis showing how append-only memory growth, bounded curriculum coverage, and task-filtered retrieval together support stable improvement of the retrieval substrate for frozen-learner evolution. Across nine benchmarks spanning mathematical reasoning, multi-hop and open-domain question answering, spatio-temporal analysis, financial numerical reasoning, medical multiple-choice, an open-world survival game, and web navigation, MAGE achieves strong performance against prompt-based frozen-backbone baselines. Ablations show that self-harvested success traces and teacher-written corrections are complementary, with success memories contributing most on reasoning-template-heavy tasks and corrective memories supporting harder composition and interaction settings.
Route by State, Recover from Trace: STAR with Failure-Aware Markov Routing for Multi-Agent Spatiotemporal Reasoning
May 11, 2026Compositional spatiotemporal reasoning often requires a system to invoke multiple heterogeneous specialists, such as geometric, temporal, topological, and trajectory agents. A central question is how such a system should route among specialists when execution does not simply succeed or fail, but fails in qualitatively different ways. Existing tool-augmented and multi-agent LLM systems typically leave this routing decision implicit in language generation, making recovery ad hoc, difficult to interpret, and hard to optimize. This paper presents STAR (Spatio-Temporal Agent Router), a failure-aware routing framework that externalizes inter-agent control as a state-conditioned transition policy over the current agent, task type, and typed execution status. At the center of STARis an agent routing matrix that combines expert-specified nominal routes with recovery transitions learned from execution traces. Because the matrix conditions on distinct failure states, the router can respond differently to malformed outputs, missing dependencies, and tool--query mismatches, rather than collapsing them into a generic retry signal. Specialists execute through a tool-grounded extract--compute--deposit protocol and write intermediate results to a shared blackboard for downstream fusion. Results prove that retaining unsuccessful traces during training enlarges the support of the routing policy on error states, enabling recovery transitions that success-only training cannot represent. Across three spatiotemporal benchmarks and eight backbone LLMs, STAR improves over multiple baselines with the clearest gains on queries whose execution deviates from the nominal routing path. Router-specific ablations and recovery analyses further show that typed failure-aware routing, rather than specialist composition alone, is a key factor for these improvements.
Bayesian Optimization on Networks
Oct 31, 2025This paper studies optimization on networks modeled as metric graphs. Motivated by applications where the objective function is expensive to evaluate or only available as a black box, we develop Bayesian optimization algorithms that sequentially update a Gaussian process surrogate model of the objective to guide the acquisition of query points. To ensure that the surrogates are tailored to the network's geometry, we adopt Whittle-Mat\'ern Gaussian process prior models defined via stochastic partial differential equations on metric graphs. In addition to establishing regret bounds for optimizing sufficiently smooth objective functions, we analyze the practical case in which the smoothness of the objective is unknown and the Whittle-Mat\'ern prior is represented using finite elements. Numerical results demonstrate the effectiveness of our algorithms for optimizing benchmark objective functions on a synthetic metric graph and for Bayesian inversion via maximum a posteriori estimation on a telecommunication network.
Hierarchical Sequence Iteration for Heterogeneous Question Answering
Oct 23, 2025Retrieval-augmented generation (RAG) remains brittle on multi-step questions and heterogeneous evidence sources, trading accuracy against latency and token/tool budgets. This paper introducesHierarchical Sequence (HSEQ) Iteration for Heterogeneous Question Answering, a unified framework that (i) linearize documents, tables, and knowledge graphs into a reversible hierarchical sequence with lightweight structural tags, and (ii) perform structure-aware iteration to collect just-enough evidence before answer synthesis. A Head Agent provides guidance that leads retrieval, while an Iteration Agent selects and expands HSeq via structure-respecting actions (e.g., parent/child hops, table row/column neighbors, KG relations); Finally the head agent composes canonicalized evidence to genearte the final answer, with an optional refinement loop to resolve detected contradictions. Experiments on HotpotQA (text), HybridQA/TAT-QA (table+text), and MetaQA (KG) show consistent EM/F1 gains over strong single-pass, multi-hop, and agentic RAG baselines with high efficiency. Besides, HSEQ exhibits three key advantages: (1) a format-agnostic unification that enables a single policy to operate across text, tables, and KGs without per-dataset specialization; (2) guided, budget-aware iteration that reduces unnecessary hops, tool calls, and tokens while preserving accuracy; and (3) evidence canonicalization for reliable QA, improving answers consistency and auditability.
Divide by Question, Conquer by Agent: SPLIT-RAG with Question-Driven Graph Partitioning
May 20, 2025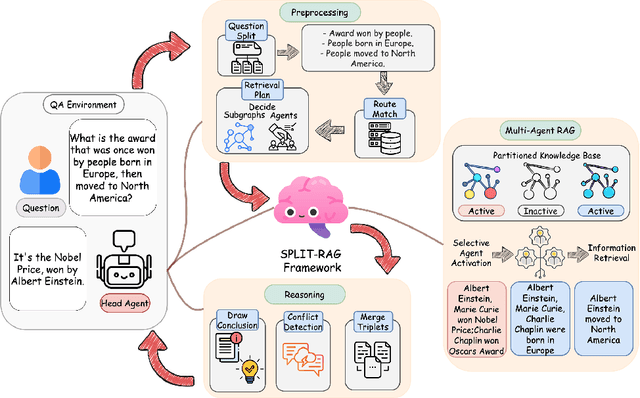
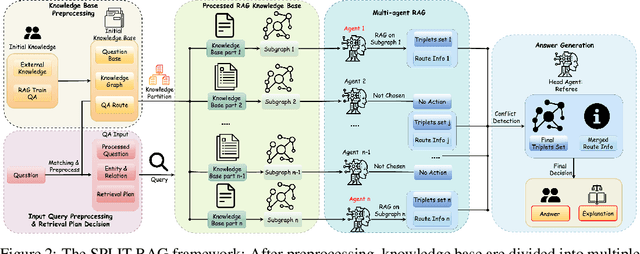
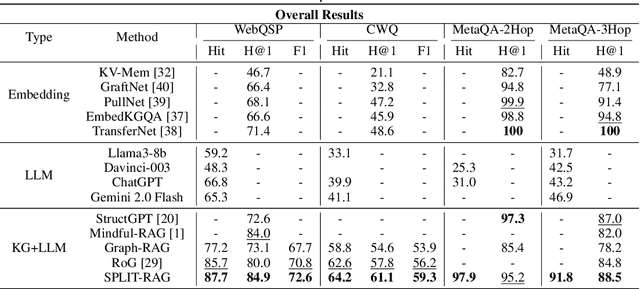
Retrieval-Augmented Generation (RAG) systems empower large language models (LLMs) with external knowledge, yet struggle with efficiency-accuracy trade-offs when scaling to large knowledge graphs. Existing approaches often rely on monolithic graph retrieval, incurring unnecessary latency for simple queries and fragmented reasoning for complex multi-hop questions. To address these challenges, this paper propose SPLIT-RAG, a multi-agent RAG framework that addresses these limitations with question-driven semantic graph partitioning and collaborative subgraph retrieval. The innovative framework first create Semantic Partitioning of Linked Information, then use the Type-Specialized knowledge base to achieve Multi-Agent RAG. The attribute-aware graph segmentation manages to divide knowledge graphs into semantically coherent subgraphs, ensuring subgraphs align with different query types, while lightweight LLM agents are assigned to partitioned subgraphs, and only relevant partitions are activated during retrieval, thus reduce search space while enhancing efficiency. Finally, a hierarchical merging module resolves inconsistencies across subgraph-derived answers through logical verifications. Extensive experimental validation demonstrates considerable improvements compared to existing approaches.
KG-IRAG: A Knowledge Graph-Based Iterative Retrieval-Augmented Generation Framework for Temporal Reasoning
Mar 19, 2025



Graph Retrieval-Augmented Generation (GraphRAG) has proven highly effective in enhancing the performance of Large Language Models (LLMs) on tasks that require external knowledge. By leveraging Knowledge Graphs (KGs), GraphRAG improves information retrieval for complex reasoning tasks, providing more precise and comprehensive retrieval and generating more accurate responses to QAs. However, most RAG methods fall short in addressing multi-step reasoning, particularly when both information extraction and inference are necessary. To address this limitation, this paper presents Knowledge Graph-Based Iterative Retrieval-Augmented Generation (KG-IRAG), a novel framework that integrates KGs with iterative reasoning to improve LLMs' ability to handle queries involving temporal and logical dependencies. Through iterative retrieval steps, KG-IRAG incrementally gathers relevant data from external KGs, enabling step-by-step reasoning. The proposed approach is particularly suited for scenarios where reasoning is required alongside dynamic temporal data extraction, such as determining optimal travel times based on weather conditions or traffic patterns. Experimental results show that KG-IRAG improves accuracy in complex reasoning tasks by effectively integrating external knowledge with iterative, logic-based retrieval. Additionally, three new datasets: weatherQA-Irish, weatherQA-Sydney, and trafficQA-TFNSW, are formed to evaluate KG-IRAG's performance, demonstrating its potential beyond traditional RAG applications.
Model-free Estimation of Latent Structure via Multiscale Nonparametric Maximum Likelihood
Oct 29, 2024



Multivariate distributions often carry latent structures that are difficult to identify and estimate, and which better reflect the data generating mechanism than extrinsic structures exhibited simply by the raw data. In this paper, we propose a model-free approach for estimating such latent structures whenever they are present, without assuming they exist a priori. Given an arbitrary density $p_0$, we construct a multiscale representation of the density and propose data-driven methods for selecting representative models that capture meaningful discrete structure. Our approach uses a nonparametric maximum likelihood estimator to estimate the latent structure at different scales and we further characterize their asymptotic limits. By carrying out such a multiscale analysis, we obtain coarseto-fine structures inherent in the original distribution, which are integrated via a model selection procedure to yield an interpretable discrete representation of it. As an application, we design a clustering algorithm based on the proposed procedure and demonstrate its effectiveness in capturing a wide range of latent structures.
SSTKG: Simple Spatio-Temporal Knowledge Graph for Intepretable and Versatile Dynamic Information Embedding
Feb 19, 2024Knowledge graphs (KGs) have been increasingly employed for link prediction and recommendation using real-world datasets. However, the majority of current methods rely on static data, neglecting the dynamic nature and the hidden spatio-temporal attributes of real-world scenarios. This often results in suboptimal predictions and recommendations. Although there are effective spatio-temporal inference methods, they face challenges such as scalability with large datasets and inadequate semantic understanding, which impede their performance. To address these limitations, this paper introduces a novel framework - Simple Spatio-Temporal Knowledge Graph (SSTKG), for constructing and exploring spatio-temporal KGs. To integrate spatial and temporal data into KGs, our framework exploited through a new 3-step embedding method. Output embeddings can be used for future temporal sequence prediction and spatial information recommendation, providing valuable insights for various applications such as retail sales forecasting and traffic volume prediction. Our framework offers a simple but comprehensive way to understand the underlying patterns and trends in dynamic KG, thereby enhancing the accuracy of predictions and the relevance of recommendations. This work paves the way for more effective utilization of spatio-temporal data in KGs, with potential impacts across a wide range of sectors.