 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Uncertainty-Guided and Top-k Codebook Matching for Real-World Blind Image Super-Resolution
Jun 09, 2025Recent advancements in codebook-based real image super-resolution (SR) have shown promising results in real-world applications. The core idea involves matching high-quality image features from a codebook based on low-resolution (LR) image features. However, existing methods face two major challenges: inaccurate feature matching with the codebook and poor texture detail reconstruction. To address these issues, we propose a novel Uncertainty-Guided and Top-k Codebook Matching SR (UGTSR) framework, which incorporates three key components: (1) an uncertainty learning mechanism that guides the model to focus on texture-rich regions, (2) a Top-k feature matching strategy that enhances feature matching accuracy by fusing multiple candidate features, and (3) an Align-Attention module that enhances the alignment of information between LR and HR features. Experimental results demonstrate significant improvements in texture realism and reconstruction fidelity compared to existing methods. We will release the code upon formal publication.
Zone Evaluation: Revealing Spatial Bias in Object Detection
Oct 20, 2023
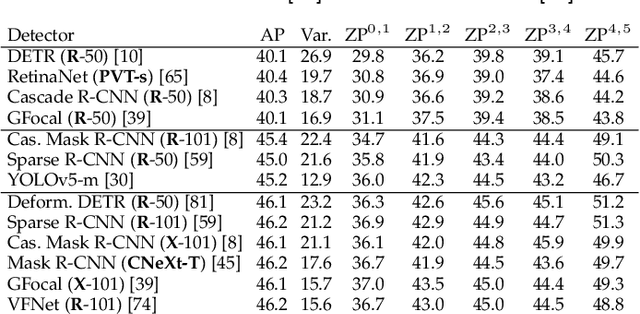
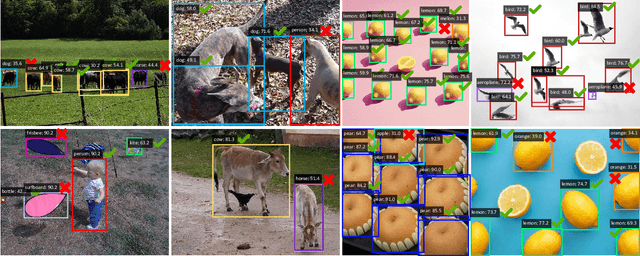
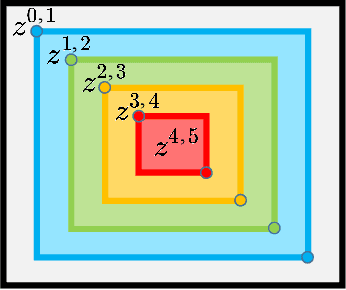
A fundamental limitation of object detectors is that they suffer from "spatial bias", and in particular perform less satisfactorily when detecting objects near image borders. For a long time, there has been a lack of effective ways to measure and identify spatial bias, and little is known about where it comes from and what degree it is. To this end, we present a new zone evaluation protocol, extending from the traditional evaluation to a more generalized one, which measures the detection performance over zones, yielding a series of Zone Precisions (ZPs). For the first time, we provide numerical results, showing that the object detectors perform quite unevenly across the zones. Surprisingly, the detector's performance in the 96\% border zone of the image does not reach the AP value (Average Precision, commonly regarded as the average detection performance in the entire image zone). To better understand spatial bias, a series of heuristic experiments are conducted. Our investigation excludes two intuitive conjectures about spatial bias that the object scale and the absolute positions of objects barely influence the spatial bias. We find that the key lies in the human-imperceptible divergence in data patterns between objects in different zones, thus eventually forming a visible performance gap between the zones. With these findings, we finally discuss a future direction for object detection, namely, spatial disequilibrium problem, aiming at pursuing a balanced detection ability over the entire image zone. By broadly evaluating 10 popular object detectors and 5 detection datasets, we shed light on the spatial bias of object detectors. We hope this work could raise a focus on detection robustness. The source codes, evaluation protocols, and tutorials are publicly available at \url{https://github.com/Zzh-tju/ZoneEval}.
CrossKD: Cross-Head Knowledge Distillation for Dense Object Detection
Jun 20, 2023Knowledge Distillation (KD) has been validated as an effective model compression technique for learning compact object detectors. Existing state-of-the-art KD methods for object detection are mostly based on feature imitation, which is generally observed to be better than prediction mimicking. In this paper, we show that the inconsistency of the optimization objectives between the ground-truth signals and distillation targets is the key reason for the inefficiency of prediction mimicking. To alleviate this issue, we present a simple yet effective distillation scheme, termed CrossKD, which delivers the intermediate features of the student's detection head to the teacher's detection head. The resulting cross-head predictions are then forced to mimic the teacher's predictions. Such a distillation manner relieves the student's head from receiving contradictory supervision signals from the ground-truth annotations and the teacher's predictions, greatly improving the student's detection performance. On MS COCO, with only prediction mimicking losses applied, our CrossKD boosts the average precision of GFL ResNet-50 with 1x training schedule from 40.2 to 43.7, outperforming all existing KD methods for object detection. Code is available at https://github.com/jbwang1997/CrossKD.
Large Selective Kernel Network for Remote Sensing Object Detection
Mar 20, 2023



Recent research on remote sensing object detection has largely focused on improving the representation of oriented bounding boxes but has overlooked the unique prior knowledge presented in remote sensing scenarios. Such prior knowledge can be useful because tiny remote sensing objects may be mistakenly detected without referencing a sufficiently long-range context, and the long-range context required by different types of objects can vary. In this paper, we take these priors into account and propose the Large Selective Kernel Network (LSKNet). LSKNet can dynamically adjust its large spatial receptive field to better model the ranging context of various objects in remote sensing scenarios. To the best of our knowledge, this is the first time that large and selective kernel mechanisms have been explored in the field of remote sensing object detection. Without bells and whistles, LSKNet sets new state-of-the-art scores on standard benchmarks, i.e., HRSC2016 (98.46\% mAP), DOTA-v1.0 (81.85\% mAP) and FAIR1M-v1.0 (47.87\% mAP). Based on a similar technique, we rank 2nd place in 2022 the Greater Bay Area International Algorithm Competition. Code is available at https://github.com/zcablii/Large-Selective-Kernel-Network.
Towards Spatial Equilibrium Object Detection
Jan 14, 2023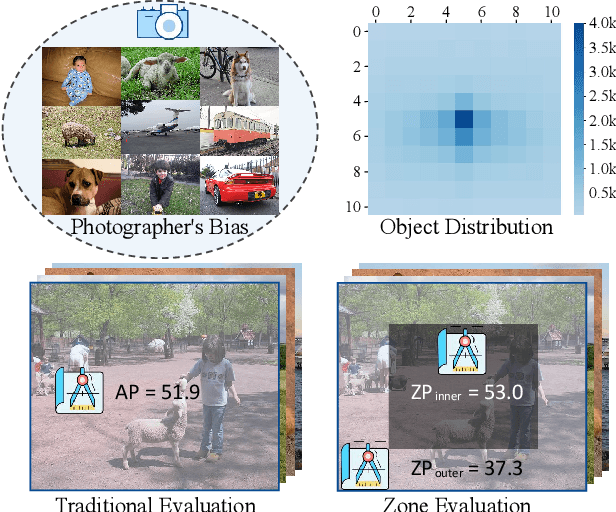



Semantic objects are unevenly distributed over images. In this paper, we study the spatial disequilibrium problem of modern object detectors and propose to quantify this ``spatial bias'' by measuring the detection performance over zones. Our analysis surprisingly shows that the spatial imbalance of objects has a great impact on the detection performance, limiting the robustness of detection applications. This motivates us to design a more generalized measurement, termed Spatial equilibrium Precision (SP), to better characterize the detection performance of object detectors. Furthermore, we also present a spatial equilibrium label assignment (SELA) to alleviate the spatial disequilibrium problem by injecting the prior spatial weight into the optimization process of detectors. Extensive experiments on PASCAL VOC, MS COCO, and 3 application datasets on face mask/fruit/helmet images demonstrate the advantages of our method. Our findings challenge the conventional sense of object detectors and show the indispensability of spatial equilibrium. We hope these discoveries would stimulate the community to rethink how an excellent object detector should be. All the source code, evaluation protocols, and the tutorials are publicly available at https://github.com/Zzh-tju/ZoneEval
Localization Distillation for Object Detection
Apr 12, 2022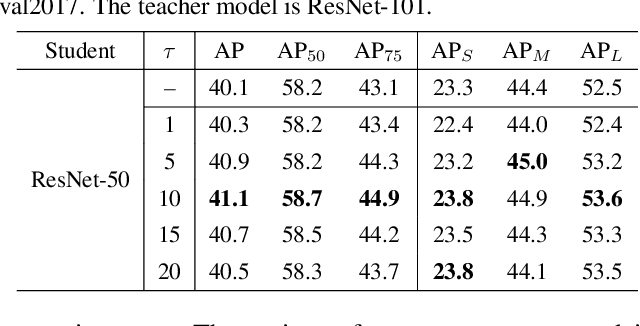
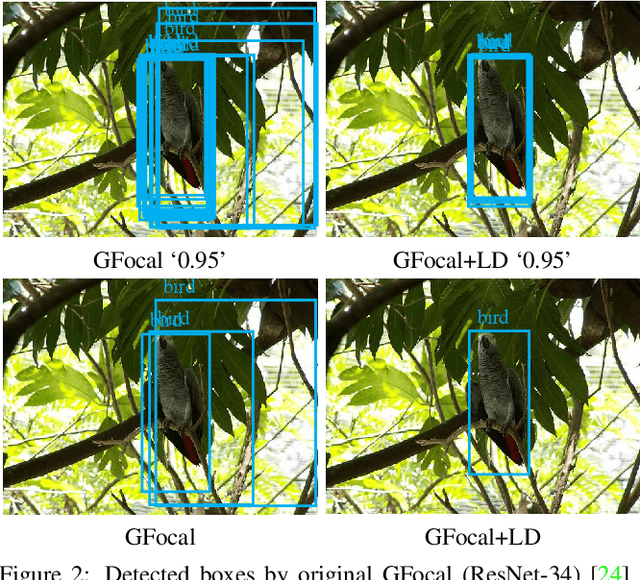
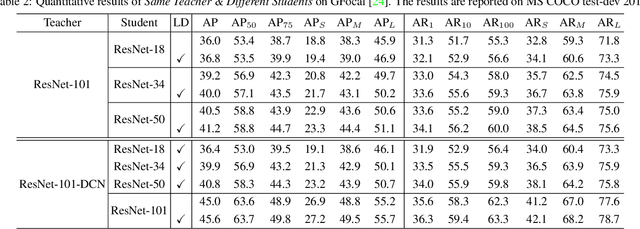
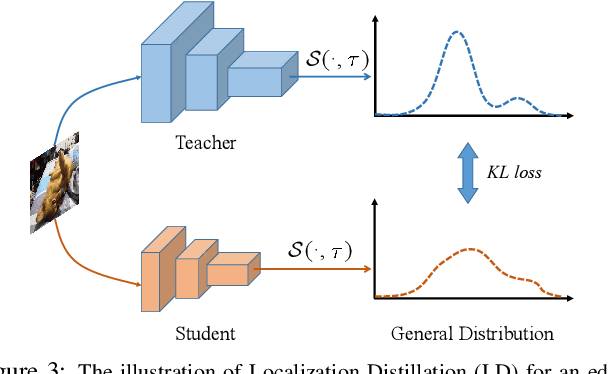
Previous knowledge distillation (KD) methods for object detection mostly focus on feature imitation instead of mimicking the classification logits due to its inefficiency in distilling the localization information. In this paper, we investigate whether logit mimicking always lags behind feature imitation. Towards this goal, we first present a novel localization distillation (LD) method which can efficiently transfer the localization knowledge from the teacher to the student. Second, we introduce the concept of valuable localization region that can aid to selectively distill the classification and localization knowledge for a certain region. Combining these two new components, for the first time, we show that logit mimicking can outperform feature imitation and the absence of localization distillation is a critical reason for why logit mimicking underperforms for years. The thorough studies exhibit the great potential of logit mimicking that can significantly alleviate the localization ambiguity, learn robust feature representation, and ease the training difficulty in the early stage. We also provide the theoretical connection between the proposed LD and the classification KD, that they share the equivalent optimization effect. Our distillation scheme is simple as well as effective and can be easily applied to both dense horizontal object detectors and rotated object detectors. Extensive experiments on the MS COCO, PASCAL VOC, and DOTA benchmarks demonstrate that our method can achieve considerable AP improvement without any sacrifice on the inference speed. Our source code and pretrained models are publicly available at https://github.com/HikariTJU/LD.
Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation
May 08, 2020

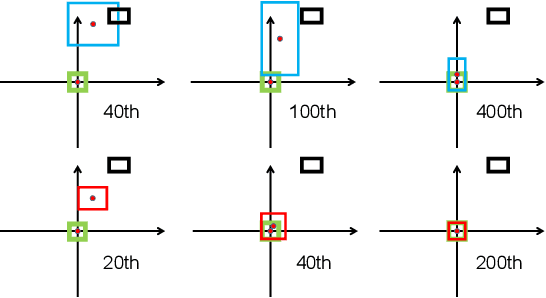

Deep learning-based object detection and instance segmentation have achieved unprecedented progress. In this paper, we propose Complete-IoU (CIoU) loss and Cluster-NMS for enhancing geometric factors in both bounding box regression and Non-Maximum Suppression (NMS), leading to notable gains of average precision (AP) and average recall (AR), without the sacrifice of inference efficiency. In particular, we consider three geometric factors, i.e., overlap area, normalized central point distance and aspect ratio, which are crucial for measuring bounding box regression in object detection and instance segmentation. The three geometric factors are then incorporated into CIoU loss for better distinguishing difficult regression cases. The training of deep models using CIoU loss results in consistent AP and AR improvements in comparison to widely adopted $\ell_n$-norm loss and IoU-based loss. Furthermore, we propose Cluster-NMS, where NMS during inference is done by implicitly clustering detected boxes and usually requires less iterations. Cluster-NMS is very efficient due to its pure GPU implementation, and geometric factors can be incorporated to improve both AP and AR. In the experiments, CIoU loss and Cluster-NMS have been applied to state-of-the-art instance segmentation (e.g., YOLACT), and object detection (e.g., YOLO v3, SSD and Faster R-CNN) models. Taking YOLACT on MS COCO as an example, our method achieves performance gains as +1.7 AP and +6.2 AR$_{100}$ for object detection, and +0.9 AP and +3.5 AR$_{100}$ for instance segmentation, with 27.1 FPS on one NVIDIA GTX 1080Ti GPU. All the source code and trained models are available at https://github.com/Zzh-tju/CIoU
Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression
Nov 19, 2019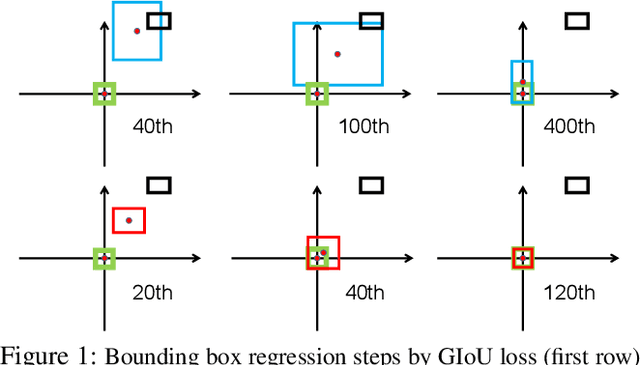
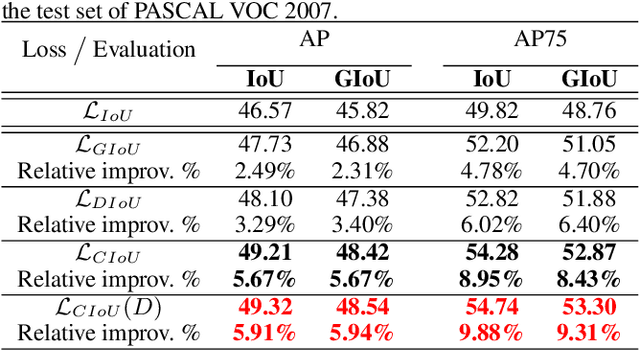
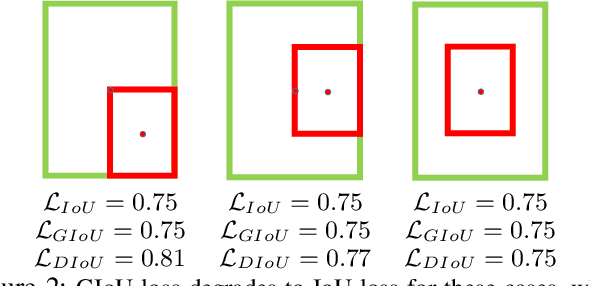
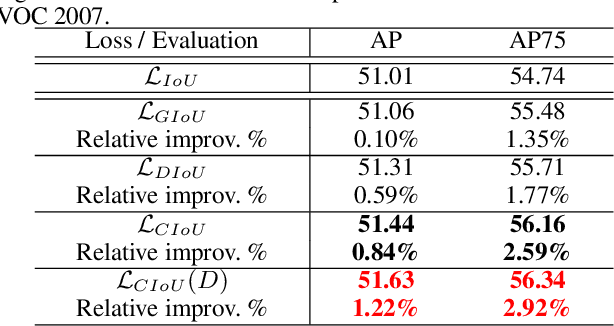
Bounding box regression is the crucial step in object detection. In existing methods, while $\ell_n$-norm loss is widely adopted for bounding box regression, it is not tailored to the evaluation metric, i.e., Intersection over Union (IoU). Recently, IoU loss and generalized IoU (GIoU) loss have been proposed to benefit the IoU metric, but still suffer from the problems of slow convergence and inaccurate regression. In this paper, we propose a Distance-IoU (DIoU) loss by incorporating the normalized distance between the predicted box and the target box, which converges much faster in training than IoU and GIoU losses. Furthermore, this paper summarizes three geometric factors in bounding box regression, \ie, overlap area, central point distance and aspect ratio, based on which a Complete IoU (CIoU) loss is proposed, thereby leading to faster convergence and better performance. By incorporating DIoU and CIoU losses into state-of-the-art object detection algorithms, e.g., YOLO v3, SSD and Faster RCNN, we achieve notable performance gains in terms of not only IoU metric but also GIoU metric. Moreover, DIoU can be easily adopted into non-maximum suppression (NMS) to act as the criterion, further boosting performance improvement. The source code and trained models are available at https://github.com/Zzh-tju/DIoU.
Refining Recency Search Results with User Click Feedback
Mar 19, 2011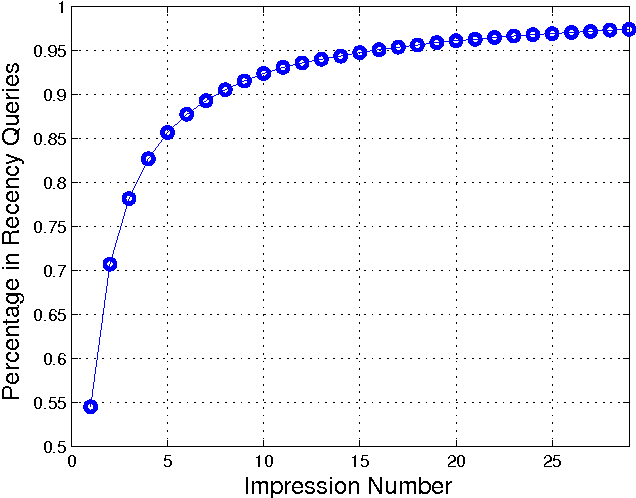

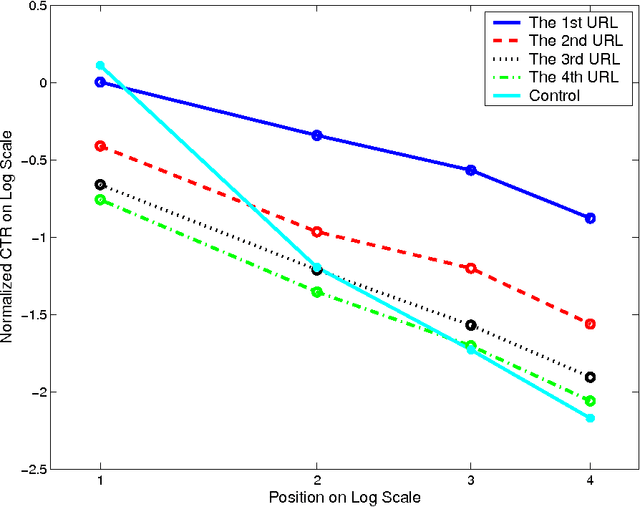

Traditional machine-learned ranking systems for web search are often trained to capture stationary relevance of documents to queries, which has limited ability to track non-stationary user intention in a timely manner. In recency search, for instance, the relevance of documents to a query on breaking news often changes significantly over time, requiring effective adaptation to user intention. In this paper, we focus on recency search and study a number of algorithms to improve ranking results by leveraging user click feedback. Our contributions are three-fold. First, we use real search sessions collected in a random exploration bucket for \emph{reliable} offline evaluation of these algorithms, which provides an unbiased comparison across algorithms without online bucket tests. Second, we propose a re-ranking approach to improve search results for recency queries using user clicks. Third, our empirical comparison of a dozen algorithms on real-life search data suggests importance of a few algorithmic choices in these applications, including generalization across different query-document pairs, specialization to popular queries, and real-time adaptation of user clicks.