 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalization Distillation for Object Detection
Paper and Code
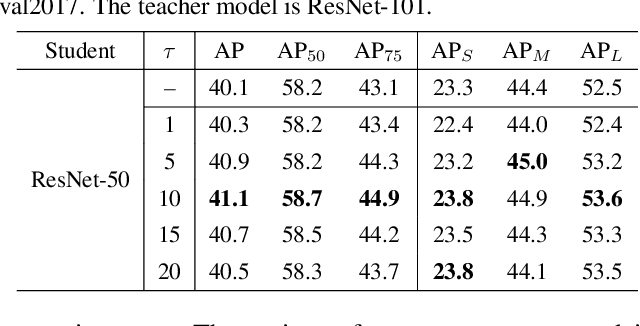
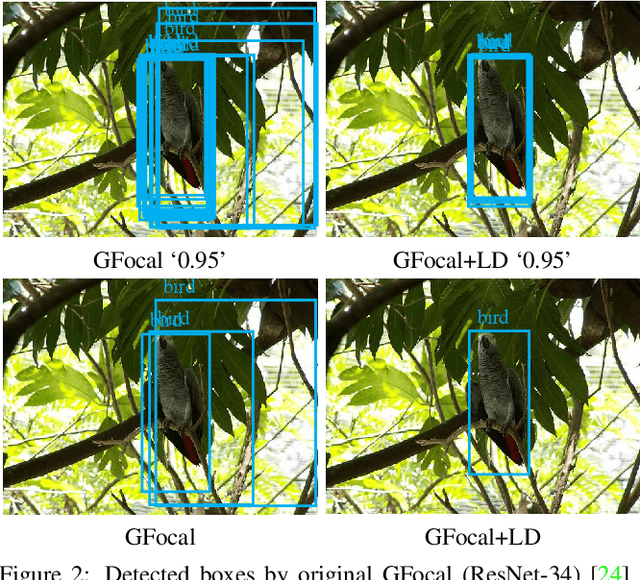
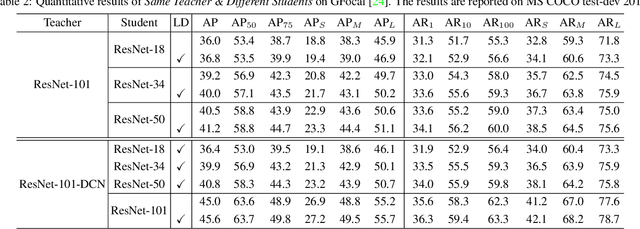
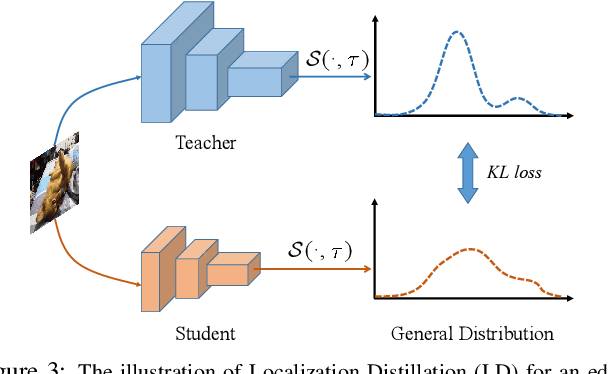
Previous knowledge distillation (KD) methods for object detection mostly focus on feature imitation instead of mimicking the classification logits due to its inefficiency in distilling the localization information. In this paper, we investigate whether logit mimicking always lags behind feature imitation. Towards this goal, we first present a novel localization distillation (LD) method which can efficiently transfer the localization knowledge from the teacher to the student. Second, we introduce the concept of valuable localization region that can aid to selectively distill the classification and localization knowledge for a certain region. Combining these two new components, for the first time, we show that logit mimicking can outperform feature imitation and the absence of localization distillation is a critical reason for why logit mimicking underperforms for years. The thorough studies exhibit the great potential of logit mimicking that can significantly alleviate the localization ambiguity, learn robust feature representation, and ease the training difficulty in the early stage. We also provide the theoretical connection between the proposed LD and the classification KD, that they share the equivalent optimization effect. Our distillation scheme is simple as well as effective and can be easily applied to both dense horizontal object detectors and rotated object detectors. Extensive experiments on the MS COCO, PASCAL VOC, and DOTA benchmarks demonstrate that our method can achieve considerable AP improvement without any sacrifice on the inference speed. Our source code and pretrained models are publicly available at https://github.com/HikariTJU/LD.