 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniSegmentor: A Flexible Multi-Modal Learning Framework for Semantic Segmentation
Sep 18, 2025Recent research on representation learning has proved the merits of multi-modal clues for robust semantic segmentation. Nevertheless, a flexible pretrain-and-finetune pipeline for multiple visual modalities remains unexplored. In this paper, we propose a novel multi-modal learning framework, termed OmniSegmentor. It has two key innovations: 1) Based on ImageNet, we assemble a large-scale dataset for multi-modal pretraining, called ImageNeXt, which contains five popular visual modalities. 2) We provide an efficient pretraining manner to endow the model with the capacity to encode different modality information in the ImageNeXt. For the first time, we introduce a universal multi-modal pretraining framework that consistently amplifies the model's perceptual capabilities across various scenarios, regardless of the arbitrary combination of the involved modalities. Remarkably, our OmniSegmentor achieves new state-of-the-art records on a wide range of multi-modal semantic segmentation datasets, including NYU Depthv2, EventScape, MFNet, DeLiVER, SUNRGBD, and KITTI-360.
DFormerv2: Geometry Self-Attention for RGBD Semantic Segmentation
Apr 07, 2025Recent advances in scene understanding benefit a lot from depth maps because of the 3D geometry information, especially in complex conditions (e.g., low light and overexposed). Existing approaches encode depth maps along with RGB images and perform feature fusion between them to enable more robust predictions. Taking into account that depth can be regarded as a geometry supplement for RGB images, a straightforward question arises: Do we really need to explicitly encode depth information with neural networks as done for RGB images? Based on this insight, in this paper, we investigate a new way to learn RGBD feature representations and present DFormerv2, a strong RGBD encoder that explicitly uses depth maps as geometry priors rather than encoding depth information with neural networks. Our goal is to extract the geometry clues from the depth and spatial distances among all the image patch tokens, which will then be used as geometry priors to allocate attention weights in self-attention. Extensive experiments demonstrate that DFormerv2 exhibits exceptional performance in various RGBD semantic segmentation benchmarks. Code is available at: https://github.com/VCIP-RGBD/DFormer.
Multi-Token Enhancing for Vision Representation Learning
Nov 24, 2024Vision representation learning, especially self-supervised learning, is pivotal for various vision applications. Ensemble learning has also succeeded in enhancing the performance and robustness of the vision models. However, traditional ensemble strategies are impractical for representation learning, especially self-supervised representation learning that requires large-scale datasets and long schedules. This is because they require k times more training and inference computation costs for an ensemble of k models. Differently, we introduce Multi-Token Enhancing (MTE) that extracts multiple auxiliary tokens simultaneously from a single model to enhance representation learning, while incurring minimal additional training costs and no additional inference costs. These auxiliary tokens, including auxiliary CLS tokens and adaptively pooled tokens, capture complementary information due to their differences. Meanwhile, to address the increase in inference costs, we distill the knowledge acquired by the auxiliary tokens into a global token during pre-training. Consequently, we can discard the auxiliary tokens during inference without incurring additional costs. Our MTE is compatible with various self-supervised loss functions and architectures, consistently improving performances across different downstream tasks. Our source code will be made publicly available.
TeMO: Towards Text-Driven 3D Stylization for Multi-Object Meshes
Dec 07, 2023Recent progress in the text-driven 3D stylization of a single object has been considerably promoted by CLIP-based methods. However, the stylization of multi-object 3D scenes is still impeded in that the image-text pairs used for pre-training CLIP mostly consist of an object. Meanwhile, the local details of multiple objects may be susceptible to omission due to the existing supervision manner primarily relying on coarse-grained contrast of image-text pairs. To overcome these challenges, we present a novel framework, dubbed TeMO, to parse multi-object 3D scenes and edit their styles under the contrast supervision at multiple levels. We first propose a Decoupled Graph Attention (DGA) module to distinguishably reinforce the features of 3D surface points. Particularly, a cross-modal graph is constructed to align the object points accurately and noun phrases decoupled from the 3D mesh and textual description. Then, we develop a Cross-Grained Contrast (CGC) supervision system, where a fine-grained loss between the words in the textual description and the randomly rendered images are constructed to complement the coarse-grained loss. Extensive experiments show that our method can synthesize high-quality stylized content and outperform the existing methods over a wide range of multi-object 3D meshes. Our code and results will be made publicly available
Enhancing Representations through Heterogeneous Self-Supervised Learning
Oct 08, 2023

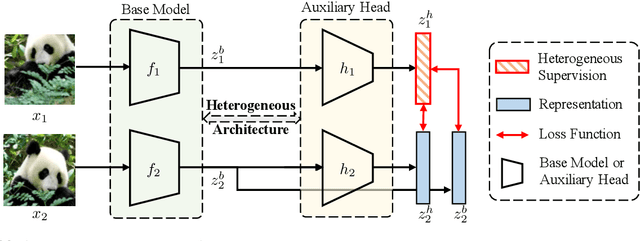

Incorporating heterogeneous representations from different architectures has facilitated various vision tasks, e.g., some hybrid networks combine transformers and convolutions. However, complementarity between such heterogeneous architectures has not been well exploited in self-supervised learning. Thus, we propose Heterogeneous Self-Supervised Learning (HSSL), which enforces a base model to learn from an auxiliary head whose architecture is heterogeneous from the base model. In this process, HSSL endows the base model with new characteristics in a representation learning way without structural changes. To comprehensively understand the HSSL, we conduct experiments on various heterogeneous pairs containing a base model and an auxiliary head. We discover that the representation quality of the base model moves up as their architecture discrepancy grows. This observation motivates us to propose a search strategy that quickly determines the most suitable auxiliary head for a specific base model to learn and several simple but effective methods to enlarge the model discrepancy. The HSSL is compatible with various self-supervised methods, achieving superior performances on various downstream tasks, including image classification, semantic segmentation, instance segmentation, and object detection. Our source code will be made publicly available.