 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Token Enhancing for Vision Representation Learning
Nov 24, 2024Vision representation learning, especially self-supervised learning, is pivotal for various vision applications. Ensemble learning has also succeeded in enhancing the performance and robustness of the vision models. However, traditional ensemble strategies are impractical for representation learning, especially self-supervised representation learning that requires large-scale datasets and long schedules. This is because they require k times more training and inference computation costs for an ensemble of k models. Differently, we introduce Multi-Token Enhancing (MTE) that extracts multiple auxiliary tokens simultaneously from a single model to enhance representation learning, while incurring minimal additional training costs and no additional inference costs. These auxiliary tokens, including auxiliary CLS tokens and adaptively pooled tokens, capture complementary information due to their differences. Meanwhile, to address the increase in inference costs, we distill the knowledge acquired by the auxiliary tokens into a global token during pre-training. Consequently, we can discard the auxiliary tokens during inference without incurring additional costs. Our MTE is compatible with various self-supervised loss functions and architectures, consistently improving performances across different downstream tasks. Our source code will be made publicly available.
Long-Tailed Class Incremental Learning
Oct 01, 2022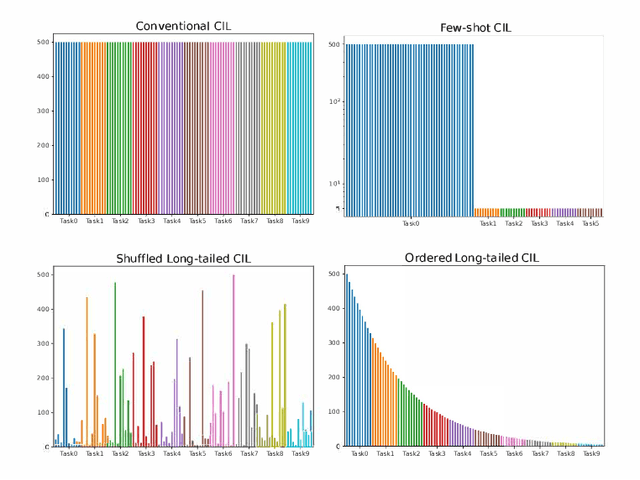
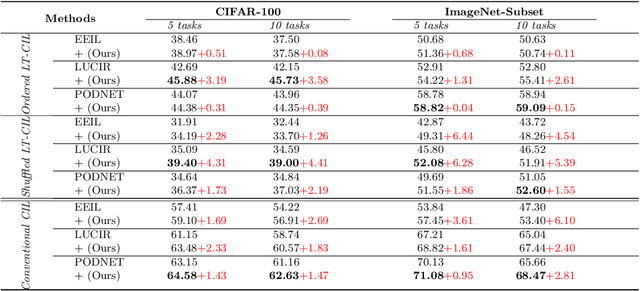
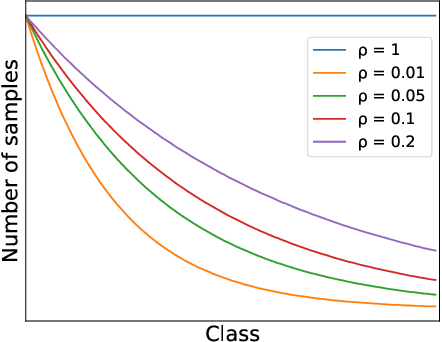
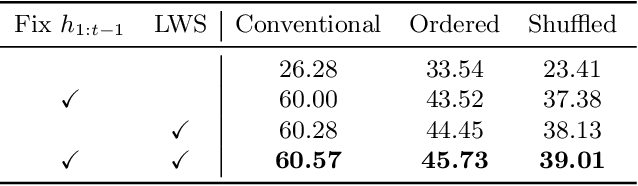
In class incremental learning (CIL) a model must learn new classes in a sequential manner without forgetting old ones. However, conventional CIL methods consider a balanced distribution for each new task, which ignores the prevalence of long-tailed distributions in the real world. In this work we propose two long-tailed CIL scenarios, which we term ordered and shuffled LT-CIL. Ordered LT-CIL considers the scenario where we learn from head classes collected with more samples than tail classes which have few. Shuffled LT-CIL, on the other hand, assumes a completely random long-tailed distribution for each task. We systematically evaluate existing methods in both LT-CIL scenarios and demonstrate very different behaviors compared to conventional CIL scenarios. Additionally, we propose a two-stage learning baseline with a learnable weight scaling layer for reducing the bias caused by long-tailed distribution in LT-CIL and which in turn also improves the performance of conventional CIL due to the limited exemplars. Our results demonstrate the superior performance (up to 6.44 points in average incremental accuracy) of our approach on CIFAR-100 and ImageNet-Subset. The code is available at https://github.com/xialeiliu/Long-Tailed-CIL