 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Tailed Class Incremental Learning
Oct 01, 2022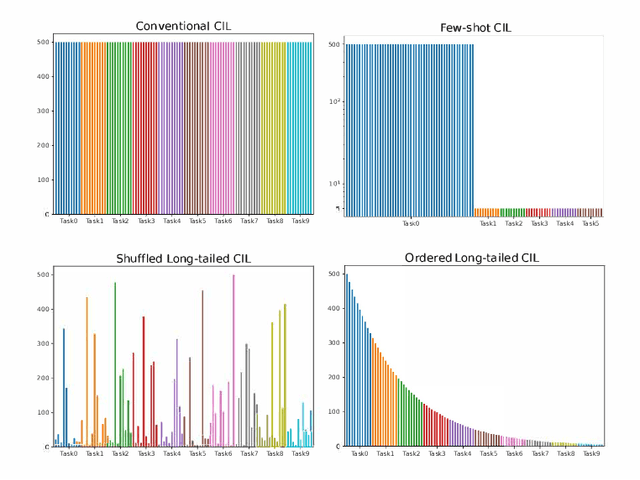
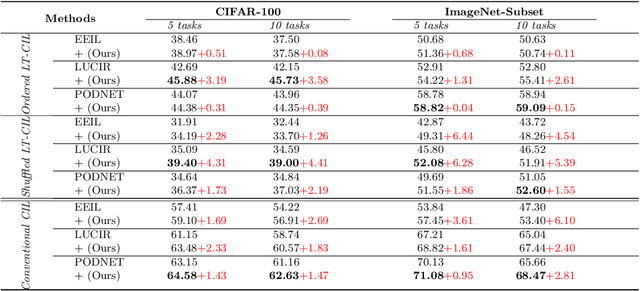
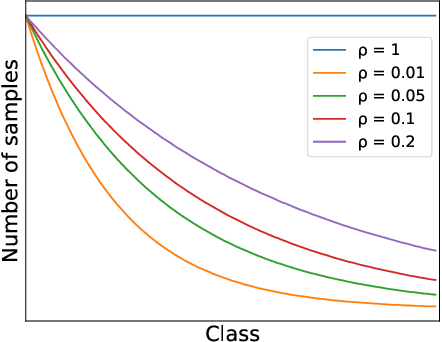
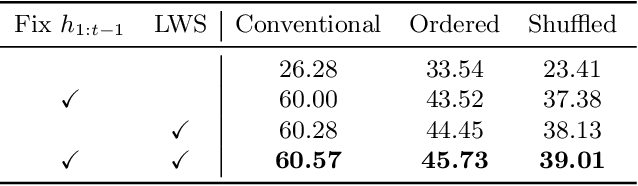
In class incremental learning (CIL) a model must learn new classes in a sequential manner without forgetting old ones. However, conventional CIL methods consider a balanced distribution for each new task, which ignores the prevalence of long-tailed distributions in the real world. In this work we propose two long-tailed CIL scenarios, which we term ordered and shuffled LT-CIL. Ordered LT-CIL considers the scenario where we learn from head classes collected with more samples than tail classes which have few. Shuffled LT-CIL, on the other hand, assumes a completely random long-tailed distribution for each task. We systematically evaluate existing methods in both LT-CIL scenarios and demonstrate very different behaviors compared to conventional CIL scenarios. Additionally, we propose a two-stage learning baseline with a learnable weight scaling layer for reducing the bias caused by long-tailed distribution in LT-CIL and which in turn also improves the performance of conventional CIL due to the limited exemplars. Our results demonstrate the superior performance (up to 6.44 points in average incremental accuracy) of our approach on CIFAR-100 and ImageNet-Subset. The code is available at https://github.com/xialeiliu/Long-Tailed-CIL