 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Data Gap: Bridging LLMs to Enterprise Data Integration
Dec 29, 2024Leading large language models (LLMs) are trained on public data. However, most of the world's data is dark data that is not publicly accessible, mainly in the form of private organizational or enterprise data. We show that the performance of methods based on LLMs seriously degrades when tested on real-world enterprise datasets. Current benchmarks, based on public data, overestimate the performance of LLMs. We release a new benchmark dataset, the GOBY Benchmark, to advance discovery in enterprise data integration. Based on our experience with this enterprise benchmark, we propose techniques to uplift the performance of LLMs on enterprise data, including (1) hierarchical annotation, (2) runtime class-learning, and (3) ontology synthesis. We show that, once these techniques are deployed, the performance on enterprise data becomes on par with that of public data. The Goby benchmark can be obtained at https://goby-benchmark.github.io/.
BEAVER: An Enterprise Benchmark for Text-to-SQL
Sep 03, 2024Existing text-to-SQL benchmarks have largely been constructed using publicly available tables from the web with human-generated tests containing question and SQL statement pairs. They typically show very good results and lead people to think that LLMs are effective at text-to-SQL tasks. In this paper, we apply off-the-shelf LLMs to a benchmark containing enterprise data warehouse data. In this environment, LLMs perform poorly, even when standard prompt engineering and RAG techniques are utilized. As we will show, the reasons for poor performance are largely due to three characteristics: (1) public LLMs cannot train on enterprise data warehouses because they are largely in the "dark web", (2) schemas of enterprise tables are more complex than the schemas in public data, which leads the SQL-generation task innately harder, and (3) business-oriented questions are often more complex, requiring joins over multiple tables and aggregations. As a result, we propose a new dataset BEAVER, sourced from real enterprise data warehouses together with natural language queries and their correct SQL statements which we collected from actual user history. We evaluated this dataset using recent LLMs and demonstrated their poor performance on this task. We hope this dataset will facilitate future researchers building more sophisticated text-to-SQL systems which can do better on this important class of data.
Making LLMs Work for Enterprise Data Tasks
Jul 22, 2024Large language models (LLMs) know little about enterprise database tables in the private data ecosystem, which substantially differ from web text in structure and content. As LLMs' performance is tied to their training data, a crucial question is how useful they can be in improving enterprise database management and analysis tasks. To address this, we contribute experimental results on LLMs' performance for text-to-SQL and semantic column-type detection tasks on enterprise datasets. The performance of LLMs on enterprise data is significantly lower than on benchmark datasets commonly used. Informed by our findings and feedback from industry practitioners, we identify three fundamental challenges -- latency, cost, and quality -- and propose potential solutions to use LLMs in enterprise data workflows effectively.
CascadeServe: Unlocking Model Cascades for Inference Serving
Jun 20, 2024Machine learning (ML) models are increasingly deployed to production, calling for efficient inference serving systems. Efficient inference serving is complicated by two challenges: (i) ML models incur high computational costs, and (ii) the request arrival rates of practical applications have frequent, high, and sudden variations which make it hard to correctly provision hardware. Model cascades are positioned to tackle both of these challenges, as they (i) save work while maintaining accuracy, and (ii) expose a high-resolution trade-off between work and accuracy, allowing for fine-grained adjustments to request arrival rates. Despite their potential, model cascades haven't been used inside an online serving system. This comes with its own set of challenges, including workload adaption, model replication onto hardware, inference scheduling, request batching, and more. In this work, we propose CascadeServe, which automates and optimizes end-to-end inference serving with cascades. CascadeServe operates in an offline and online phase. In the offline phase, the system pre-computes a gear plan that specifies how to serve inferences online. In the online phase, the gear plan allows the system to serve inferences while making near-optimal adaptations to the query load at negligible decision overheads. We find that CascadeServe saves 2-3x in cost across a wide spectrum of the latency-accuracy space when compared to state-of-the-art baselines on different workloads.
Extract-Transform-Load for Video Streams
Oct 07, 2023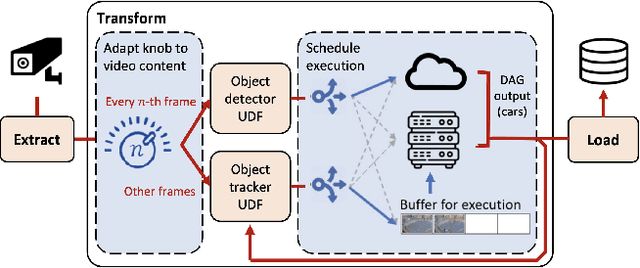
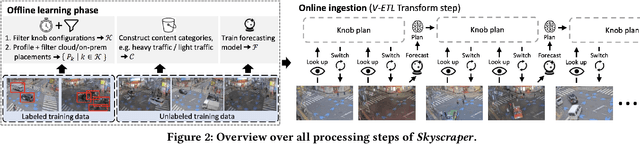
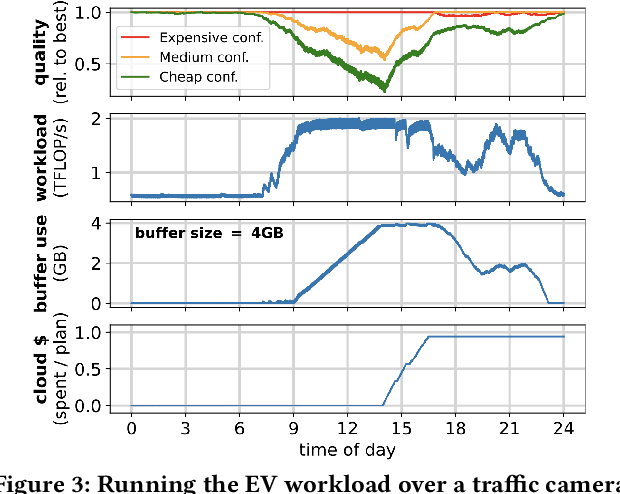
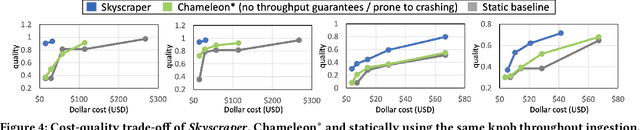
Social media, self-driving cars, and traffic cameras produce video streams at large scales and cheap cost. However, storing and querying video at such scales is prohibitively expensive. We propose to treat large-scale video analytics as a data warehousing problem: Video is a format that is easy to produce but needs to be transformed into an application-specific format that is easy to query. Analogously, we define the problem of Video Extract-Transform-Load (V-ETL). V-ETL systems need to reduce the cost of running a user-defined V-ETL job while also giving throughput guarantees to keep up with the rate at which data is produced. We find that no current system sufficiently fulfills both needs and therefore propose Skyscraper, a system tailored to V-ETL. Skyscraper can execute arbitrary video ingestion pipelines and adaptively tunes them to reduce cost at minimal or no quality degradation, e.g., by adjusting sampling rates and resolutions to the ingested content. Skyscraper can hereby be provisioned with cheap on-premises compute and uses a combination of buffering and cloud bursting to deal with peaks in workload caused by expensive processing configurations. In our experiments, we find that Skyscraper significantly reduces the cost of V-ETL ingestion compared to adaptions of current SOTA systems, while at the same time giving robustness guarantees that these systems are lacking.
* 26 pages, 23 figures
Class-Weighted Evaluation Metrics for Imbalanced Data Classification
Oct 12, 2020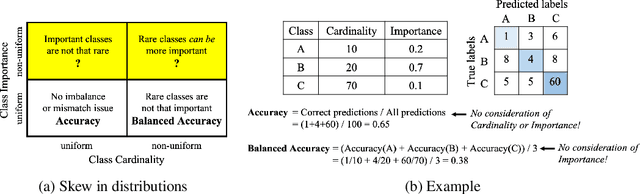
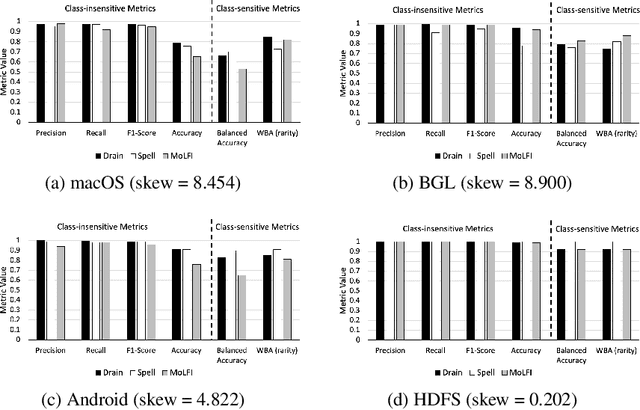
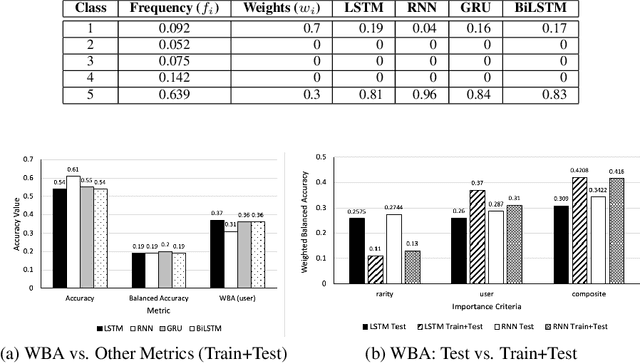
Class distribution skews in imbalanced datasets may lead to models with prediction bias towards majority classes, making fair assessment of classifiers a challenging task. Balanced Accuracy is a popular metric used to evaluate a classifier's prediction performance under such scenarios. However, this metric falls short when classes vary in importance, especially when class importance is skewed differently from class cardinality distributions. In this paper, we propose a simple and general-purpose evaluation framework for imbalanced data classification that is sensitive to arbitrary skews in class cardinalities and importances. Experiments with several state-of-the-art classifiers tested on real-world datasets and benchmarks from two different domains show that our new framework is more effective than Balanced Accuracy -- not only in evaluating and ranking model predictions, but also in training the models themselves.
AnomalyBench: An Open Benchmark for Explainable Anomaly Detection
Oct 10, 2020
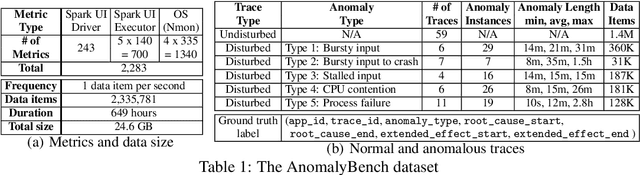
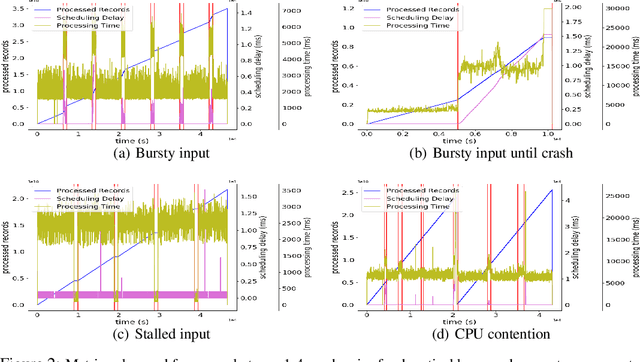

Access to high-quality data repositories and benchmarks have been instrumental in advancing the state of the art in many domains, as they provide the research community a common ground for training, testing, evaluating, comparing, and experimenting with novel machine learning models. Lack of such community resources for anomaly detection (AD) severely limits progress. In this report, we present AnomalyBench, the first comprehensive benchmark for explainable AD over high-dimensional (2000+) time series data. AnomalyBench has been systematically constructed based on real data traces from ~100 repeated executions of 10 large-scale stream processing jobs on a Spark cluster. 30+ of these executions were disturbed by introducing ~100 instances of different types of anomalous events (e.g., misbehaving inputs, resource contention, process failures). For each of these anomaly instances, ground truth labels for the root-cause interval as well as those for the effect interval are available, providing a means for supporting both AD tasks and explanation discovery (ED) tasks via root-cause analysis. We demonstrate the key design features and practical utility of AnomalyBench through an experimental study with three state-of-the-art semi-supervised AD techniques.
MISIM: An End-to-End Neural Code Similarity System
Jun 15, 2020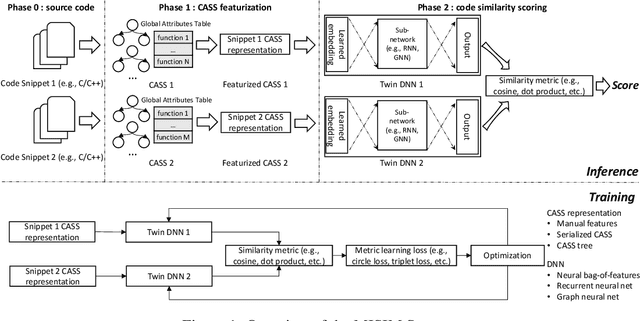
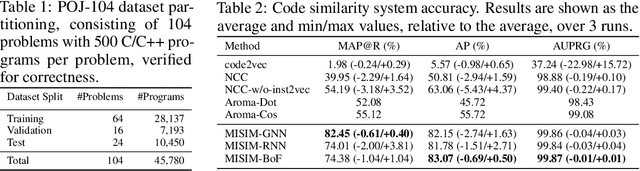
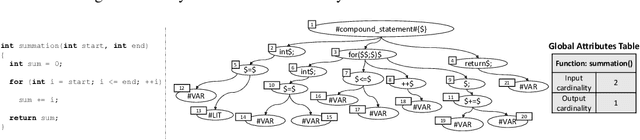
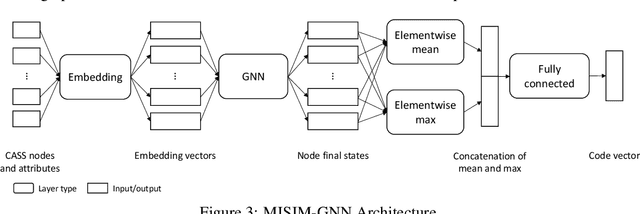
Code similarity systems are integral to a range of applications from code recommendation to automated construction of software tests and defect mitigation. In this paper, we present Machine Inferred Code Similarity (MISIM), a novel end-to-end code similarity system that consists of two core components. First, MISIM uses a novel context-aware similarity structure, which is designed to aid in lifting semantic meaning from code syntax. Second, MISIM provides a neural-based code similarity scoring system, which can be implemented with various neural network algorithms and topologies with learned parameters. We compare MISIM to three other state-of-the-art code similarity systems: (i) code2vec, (ii) Neural Code Comprehension, and (iii) Aroma. In our experimental evaluation across 45,780 programs, MISIM consistently outperformed all three systems, often by a large factor (upwards of 40.6x).
LISA: Towards Learned DNA Sequence Search
Oct 10, 2019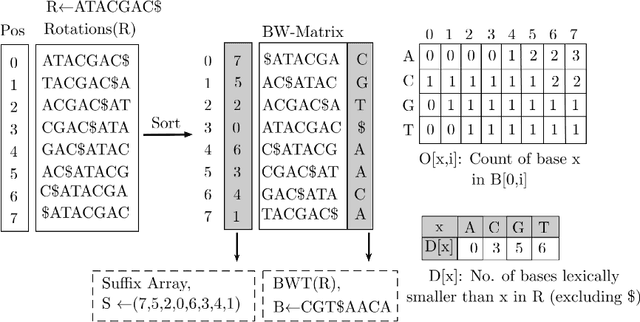

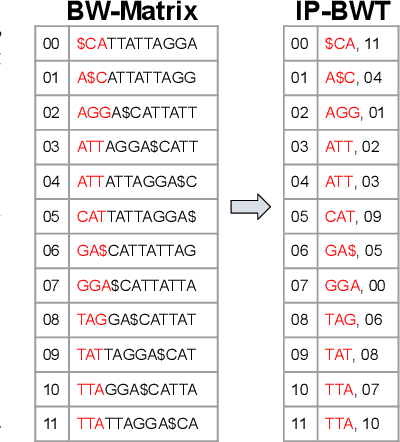
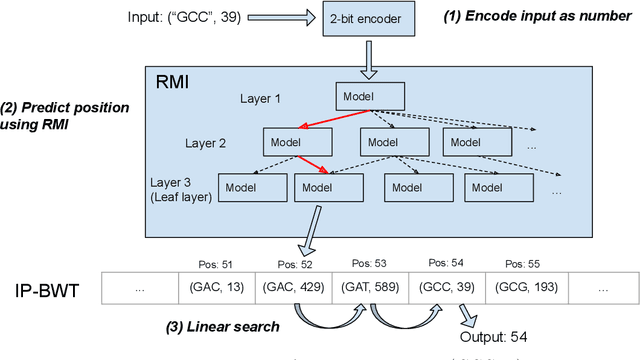
Next-generation sequencing (NGS) technologies have enabled affordable sequencing of billions of short DNA fragments at high throughput, paving the way for population-scale genomics. Genomics data analytics at this scale requires overcoming performance bottlenecks, such as searching for short DNA sequences over long reference sequences. In this paper, we introduce LISA (Learned Indexes for Sequence Analysis), a novel learning-based approach to DNA sequence search. As a first proof of concept, we focus on accelerating one of the most essential flavors of the problem, called exact search. LISA builds on and extends FM-index, which is the state-of-the-art technique widely deployed in genomics tool-chains. Initial experiments with human genome datasets indicate that LISA achieves up to a factor of 4X performance speedup against its traditional counterpart.
Precision and Recall for Time Series
Oct 28, 2018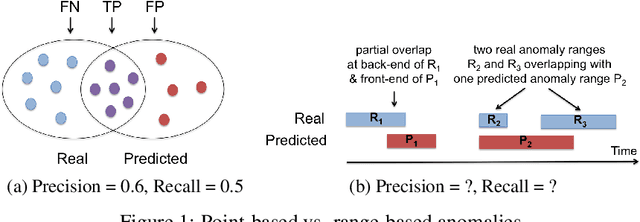


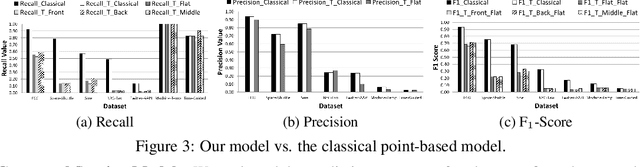
Classical anomaly detection is principally concerned with point-based anomalies, those anomalies that occur at a single point in time. Yet, many real-world anomalies are range-based, meaning they occur over a period of time. Motivated by this observation, we present a new mathematical model to evaluate the accuracy of time series classification algorithms. Our model expands the well-known Precision and Recall metrics to measure ranges, while simultaneously enabling customization support for domain-specific preferences.