 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEAVER: An Enterprise Benchmark for Text-to-SQL
Sep 03, 2024Existing text-to-SQL benchmarks have largely been constructed using publicly available tables from the web with human-generated tests containing question and SQL statement pairs. They typically show very good results and lead people to think that LLMs are effective at text-to-SQL tasks. In this paper, we apply off-the-shelf LLMs to a benchmark containing enterprise data warehouse data. In this environment, LLMs perform poorly, even when standard prompt engineering and RAG techniques are utilized. As we will show, the reasons for poor performance are largely due to three characteristics: (1) public LLMs cannot train on enterprise data warehouses because they are largely in the "dark web", (2) schemas of enterprise tables are more complex than the schemas in public data, which leads the SQL-generation task innately harder, and (3) business-oriented questions are often more complex, requiring joins over multiple tables and aggregations. As a result, we propose a new dataset BEAVER, sourced from real enterprise data warehouses together with natural language queries and their correct SQL statements which we collected from actual user history. We evaluated this dataset using recent LLMs and demonstrated their poor performance on this task. We hope this dataset will facilitate future researchers building more sophisticated text-to-SQL systems which can do better on this important class of data.
Making LLMs Work for Enterprise Data Tasks
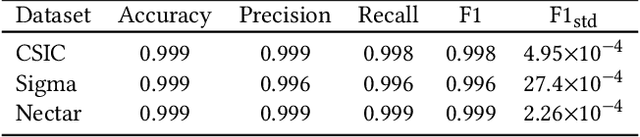
Jul 22, 2024Large language models (LLMs) know little about enterprise database tables in the private data ecosystem, which substantially differ from web text in structure and content. As LLMs' performance is tied to their training data, a crucial question is how useful they can be in improving enterprise database management and analysis tasks. To address this, we contribute experimental results on LLMs' performance for text-to-SQL and semantic column-type detection tasks on enterprise datasets. The performance of LLMs on enterprise data is significantly lower than on benchmark datasets commonly used. Informed by our findings and feedback from industry practitioners, we identify three fundamental challenges -- latency, cost, and quality -- and propose potential solutions to use LLMs in enterprise data workflows effectively.
Machine Learning with DBOS
Aug 10, 2022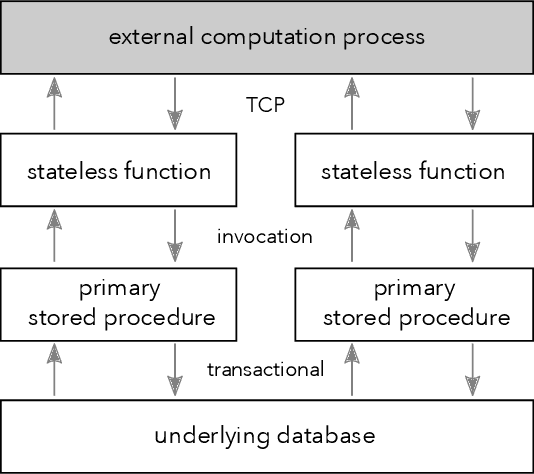
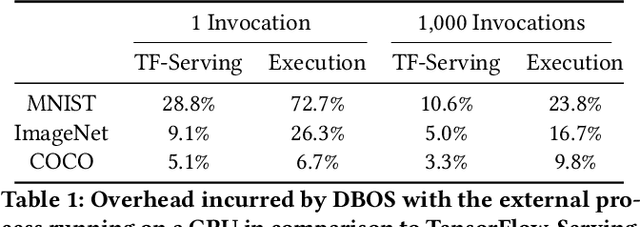

We recently proposed a new cluster operating system stack, DBOS, centered on a DBMS. DBOS enables unique support for ML applications by encapsulating ML code within stored procedures, centralizing ancillary ML data, providing security built into the underlying DBMS, co-locating ML code and data, and tracking data and workflow provenance. Here we demonstrate a subset of these benefits around two ML applications. We first show that image classification and object detection models using GPUs can be served as DBOS stored procedures with performance competitive to existing systems. We then present a 1D CNN trained to detect anomalies in HTTP requests on DBOS-backed web services, achieving SOTA results. We use this model to develop an interactive anomaly detection system and evaluate it through qualitative user feedback, demonstrating its usefulness as a proof of concept for future work to develop learned real-time security services on top of DBOS.