 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistGNN: Scalable Distributed Training for Large-Scale Graph Neural Networks
Apr 16, 2021
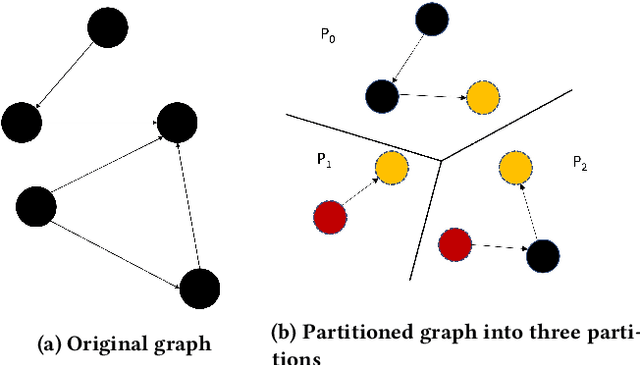
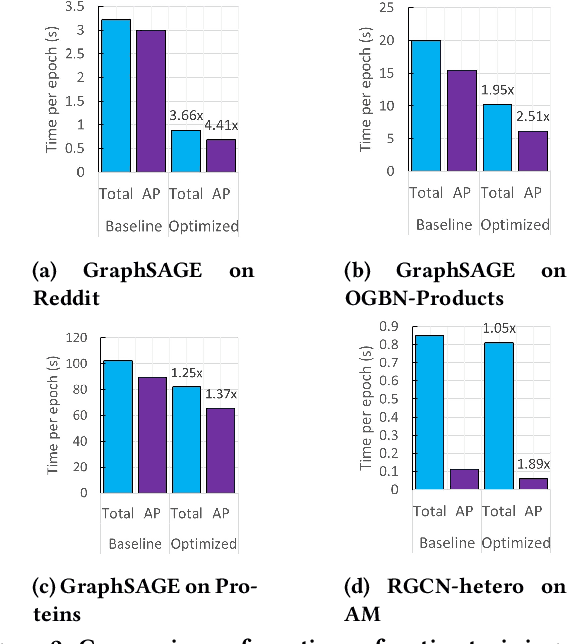
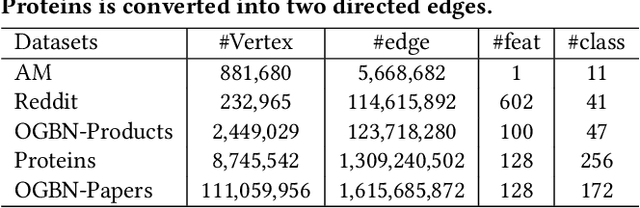
Full-batch training on Graph Neural Networks (GNN) to learn the structure of large graphs is a critical problem that needs to scale to hundreds of compute nodes to be feasible. It is challenging due to large memory capacity and bandwidth requirements on a single compute node and high communication volumes across multiple nodes. In this paper, we present DistGNN that optimizes the well-known Deep Graph Library (DGL) for full-batch training on CPU clusters via an efficient shared memory implementation, communication reduction using a minimum vertex-cut graph partitioning algorithm and communication avoidance using a family of delayed-update algorithms. Our results on four common GNN benchmark datasets: Reddit, OGB-Products, OGB-Papers and Proteins, show up to 3.7x speed-up using a single CPU socket and up to 97x speed-up using 128 CPU sockets, respectively, over baseline DGL implementations running on a single CPU socket
Tensor Processing Primitives: A Programming Abstraction for Efficiency and Portability in Deep Learning Workloads
Apr 14, 2021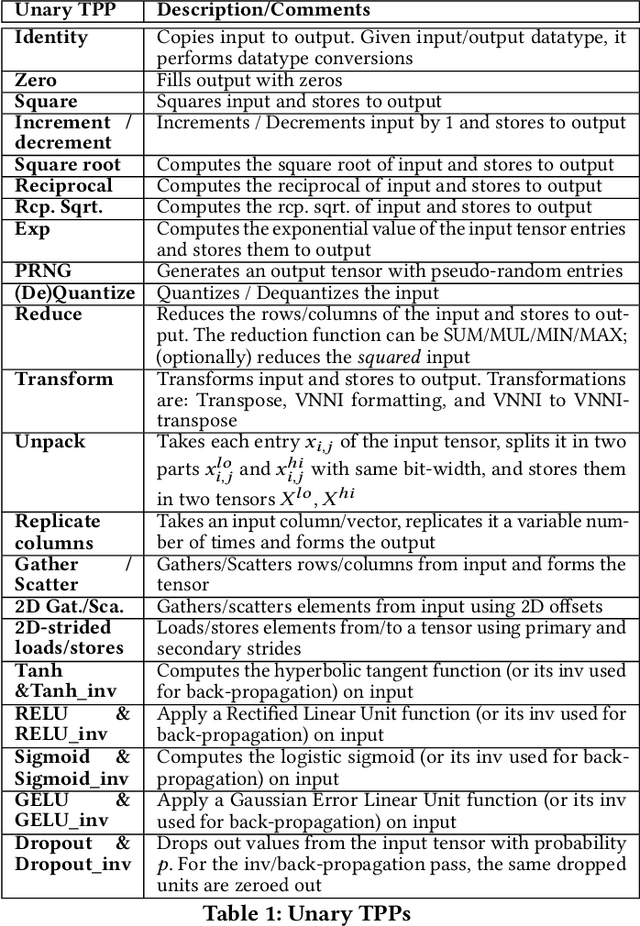
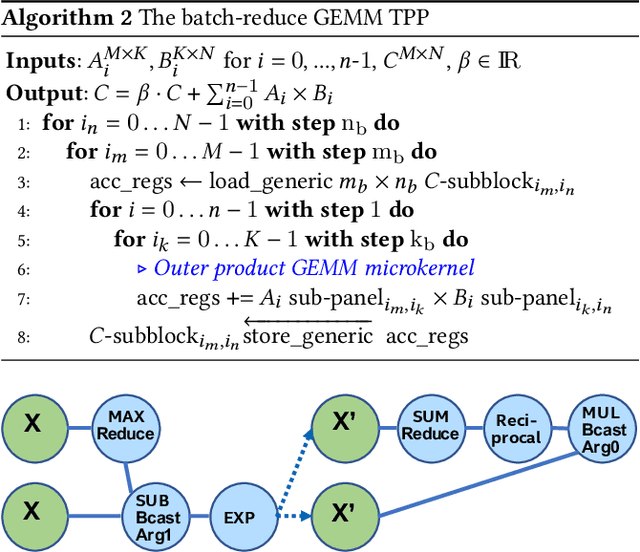
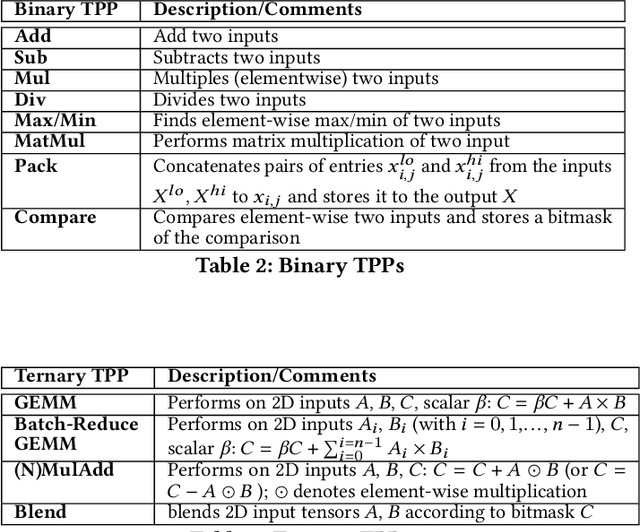
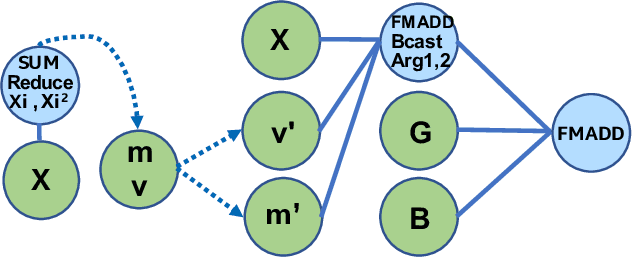
During the past decade, novel Deep Learning (DL) algorithms/workloads and hardware have been developed to tackle a wide range of problems. Despite the advances in workload/hardware ecosystems, the programming methodology of DL-systems is stagnant. DL-workloads leverage either highly-optimized, yet platform-specific and inflexible kernels from DL-libraries, or in the case of novel operators, reference implementations are built via DL-framework primitives with underwhelming performance. This work introduces the Tensor Processing Primitives (TPP), a programming abstraction striving for efficient, portable implementation of DL-workloads with high-productivity. TPPs define a compact, yet versatile set of 2D-tensor operators (or a virtual Tensor ISA), which subsequently can be utilized as building-blocks to construct complex operators on high-dimensional tensors. The TPP specification is platform-agnostic, thus code expressed via TPPs is portable, whereas the TPP implementation is highly-optimized and platform-specific. We demonstrate the efficacy of our approach using standalone kernels and end-to-end DL-workloads expressed entirely via TPPs that outperform state-of-the-art implementations on multiple platforms.
Deep Graph Library Optimizations for Intel(R) x86 Architecture
Jul 13, 2020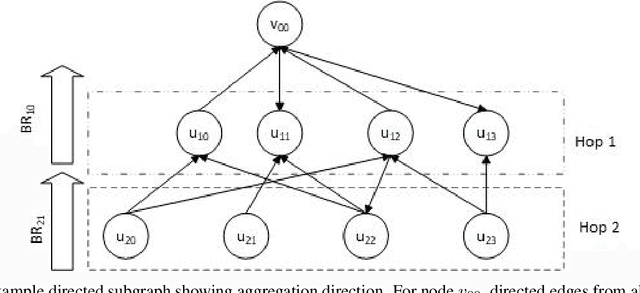
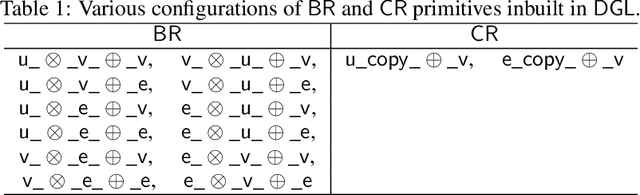
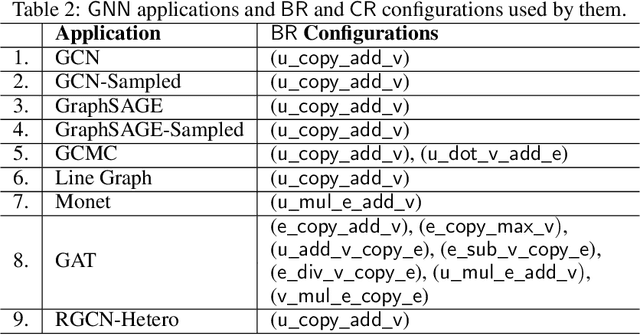
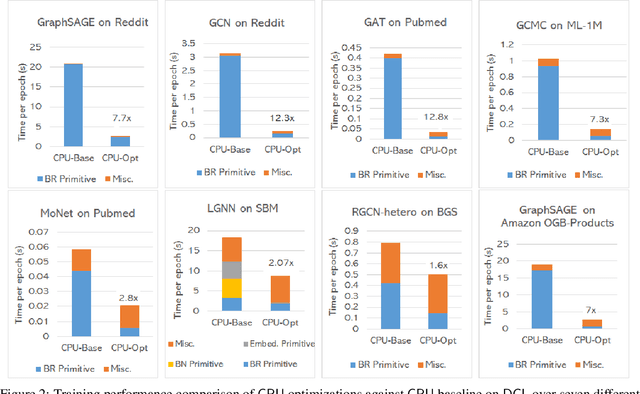
The Deep Graph Library (DGL) was designed as a tool to enable structure learning from graphs, by supporting a core abstraction for graphs, including the popular Graph Neural Networks (GNN). DGL contains implementations of all core graph operations for both the CPU and GPU. In this paper, we focus specifically on CPU implementations and present performance analysis, optimizations and results across a set of GNN applications using the latest version of DGL(0.4.3). Across 7 applications, we achieve speed-ups ranging from1 1.5x-13x over the baseline CPU implementations.
LISA: Towards Learned DNA Sequence Search
Oct 10, 2019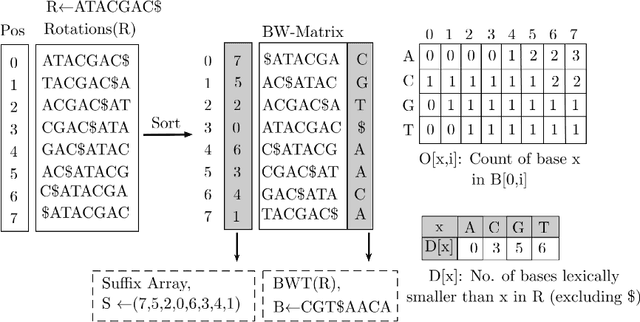

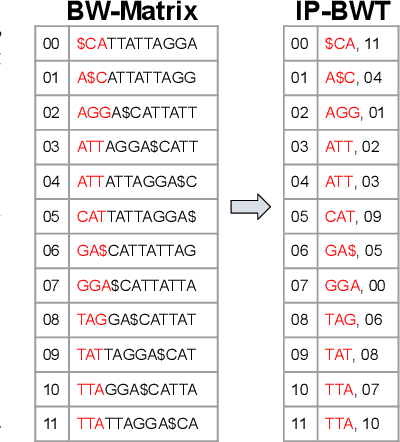
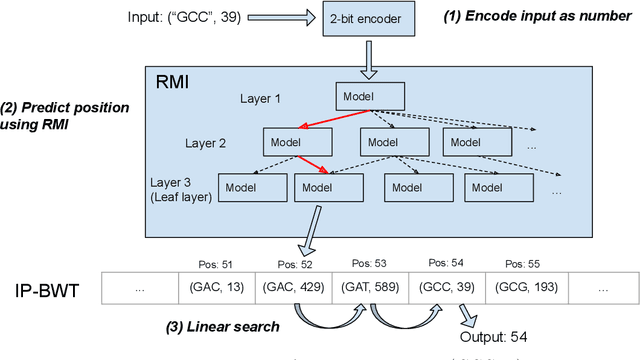
Next-generation sequencing (NGS) technologies have enabled affordable sequencing of billions of short DNA fragments at high throughput, paving the way for population-scale genomics. Genomics data analytics at this scale requires overcoming performance bottlenecks, such as searching for short DNA sequences over long reference sequences. In this paper, we introduce LISA (Learned Indexes for Sequence Analysis), a novel learning-based approach to DNA sequence search. As a first proof of concept, we focus on accelerating one of the most essential flavors of the problem, called exact search. LISA builds on and extends FM-index, which is the state-of-the-art technique widely deployed in genomics tool-chains. Initial experiments with human genome datasets indicate that LISA achieves up to a factor of 4X performance speedup against its traditional counterpart.