 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistGNN-MB: Distributed Large-Scale Graph Neural Network Training on x86 via Minibatch Sampling
Nov 11, 2022

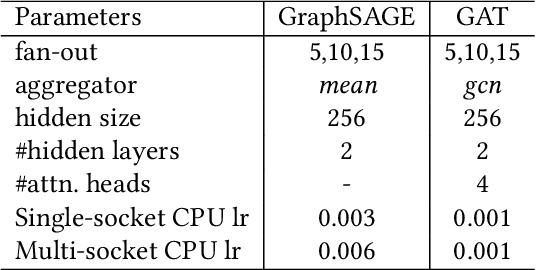
Training Graph Neural Networks, on graphs containing billions of vertices and edges, at scale using minibatch sampling poses a key challenge: strong-scaling graphs and training examples results in lower compute and higher communication volume and potential performance loss. DistGNN-MB employs a novel Historical Embedding Cache combined with compute-communication overlap to address this challenge. On a 32-node (64-socket) cluster of $3^{rd}$ generation Intel Xeon Scalable Processors with 36 cores per socket, DistGNN-MB trains 3-layer GraphSAGE and GAT models on OGBN-Papers100M to convergence with epoch times of 2 seconds and 4.9 seconds, respectively, on 32 compute nodes. At this scale, DistGNN-MB trains GraphSAGE 5.2x faster than the widely-used DistDGL. DistGNN-MB trains GraphSAGE and GAT 10x and 17.2x faster, respectively, as compute nodes scale from 2 to 32.
DistGNN: Scalable Distributed Training for Large-Scale Graph Neural Networks
Apr 16, 2021
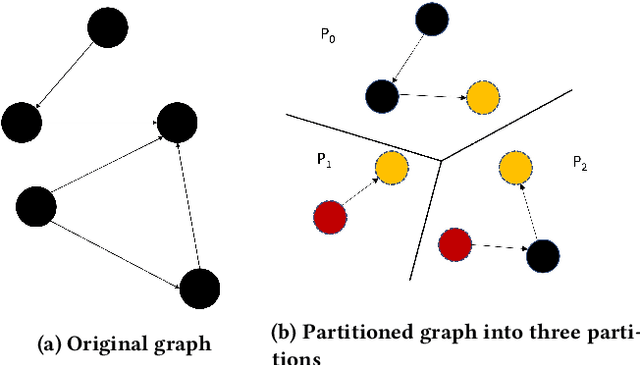
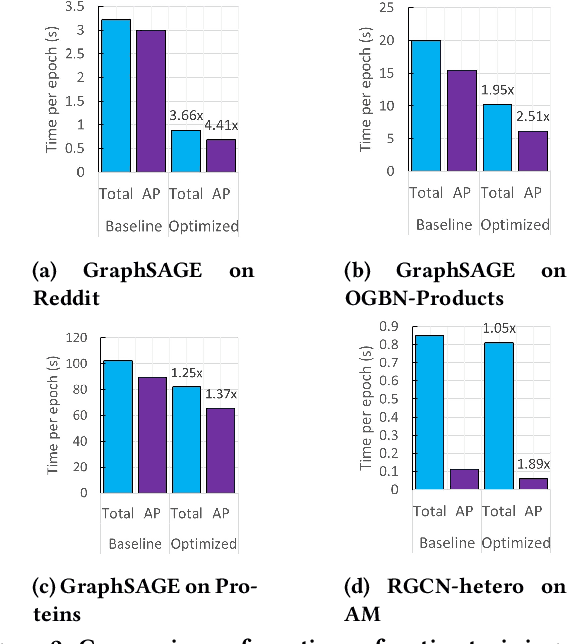
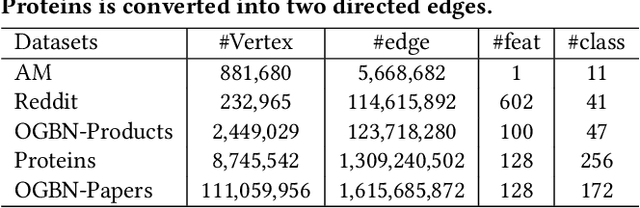
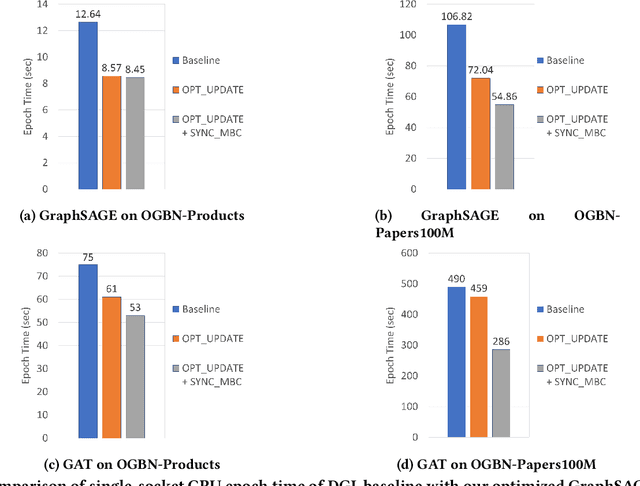
Full-batch training on Graph Neural Networks (GNN) to learn the structure of large graphs is a critical problem that needs to scale to hundreds of compute nodes to be feasible. It is challenging due to large memory capacity and bandwidth requirements on a single compute node and high communication volumes across multiple nodes. In this paper, we present DistGNN that optimizes the well-known Deep Graph Library (DGL) for full-batch training on CPU clusters via an efficient shared memory implementation, communication reduction using a minimum vertex-cut graph partitioning algorithm and communication avoidance using a family of delayed-update algorithms. Our results on four common GNN benchmark datasets: Reddit, OGB-Products, OGB-Papers and Proteins, show up to 3.7x speed-up using a single CPU socket and up to 97x speed-up using 128 CPU sockets, respectively, over baseline DGL implementations running on a single CPU socket
Tensor Processing Primitives: A Programming Abstraction for Efficiency and Portability in Deep Learning Workloads
Apr 14, 2021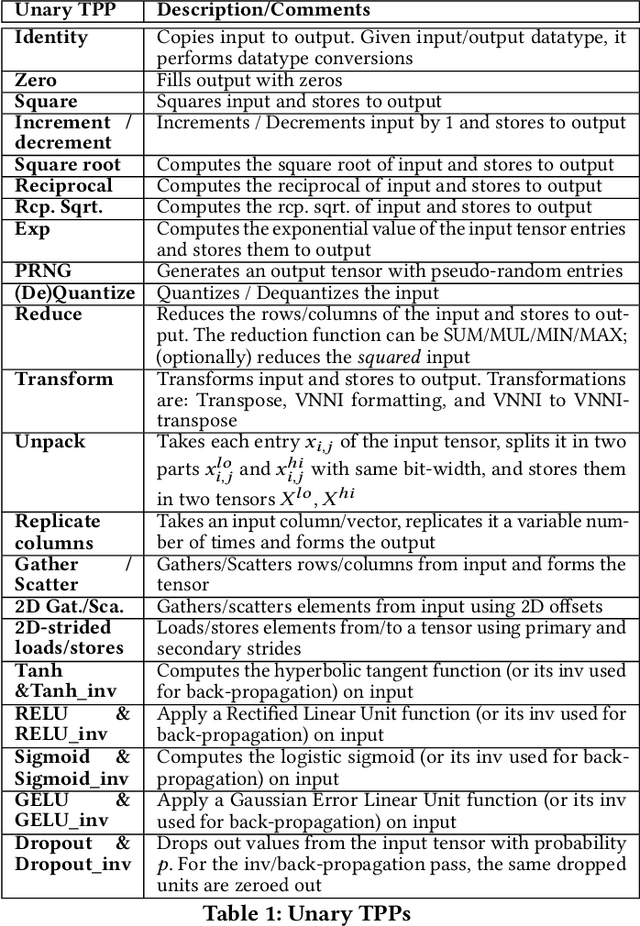
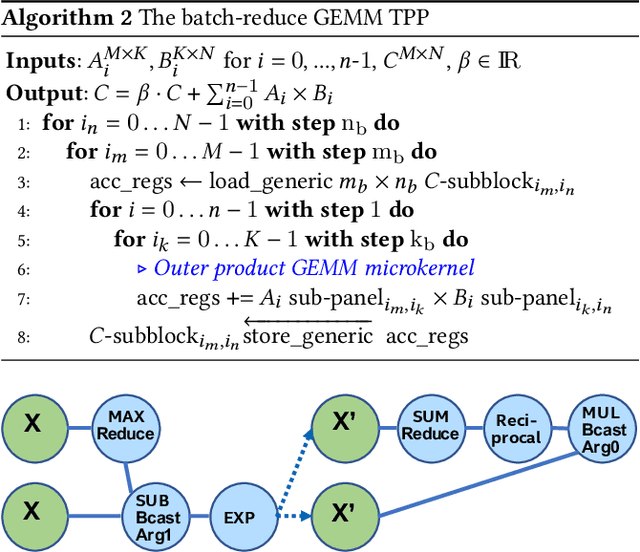
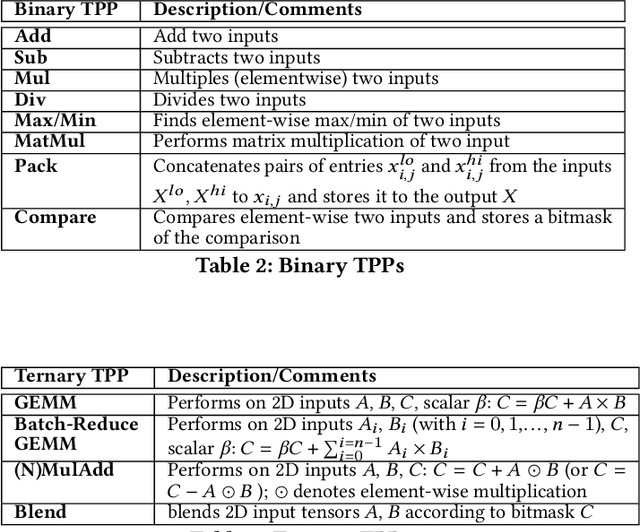
During the past decade, novel Deep Learning (DL) algorithms/workloads and hardware have been developed to tackle a wide range of problems. Despite the advances in workload/hardware ecosystems, the programming methodology of DL-systems is stagnant. DL-workloads leverage either highly-optimized, yet platform-specific and inflexible kernels from DL-libraries, or in the case of novel operators, reference implementations are built via DL-framework primitives with underwhelming performance. This work introduces the Tensor Processing Primitives (TPP), a programming abstraction striving for efficient, portable implementation of DL-workloads with high-productivity. TPPs define a compact, yet versatile set of 2D-tensor operators (or a virtual Tensor ISA), which subsequently can be utilized as building-blocks to construct complex operators on high-dimensional tensors. The TPP specification is platform-agnostic, thus code expressed via TPPs is portable, whereas the TPP implementation is highly-optimized and platform-specific. We demonstrate the efficacy of our approach using standalone kernels and end-to-end DL-workloads expressed entirely via TPPs that outperform state-of-the-art implementations on multiple platforms.
Deep Graph Library Optimizations for Intel(R) x86 Architecture
Jul 13, 2020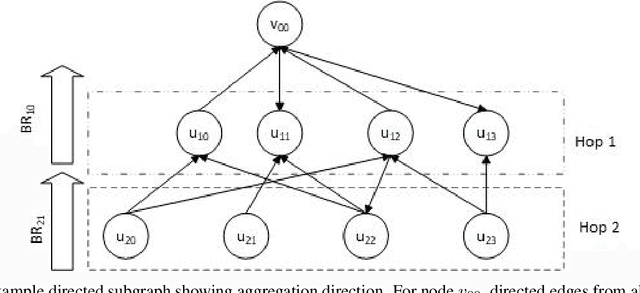
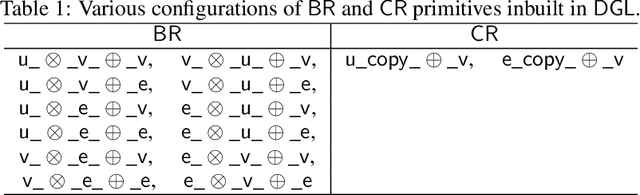
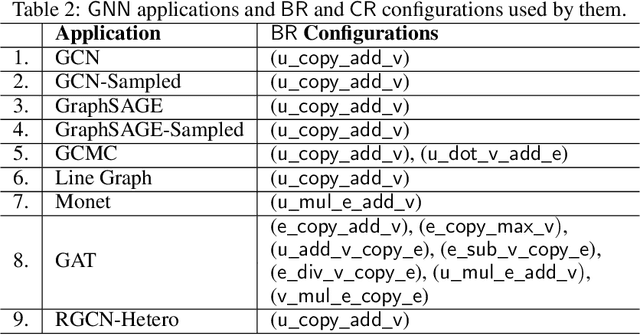
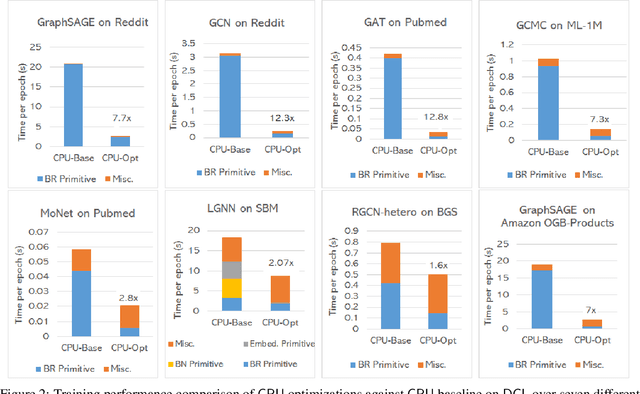
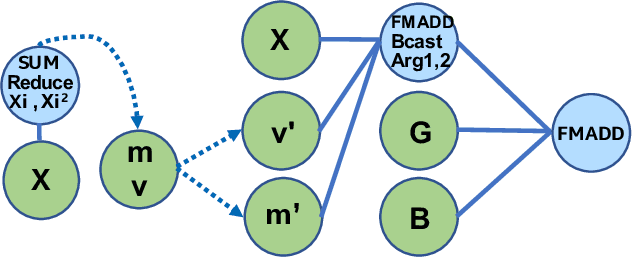
The Deep Graph Library (DGL) was designed as a tool to enable structure learning from graphs, by supporting a core abstraction for graphs, including the popular Graph Neural Networks (GNN). DGL contains implementations of all core graph operations for both the CPU and GPU. In this paper, we focus specifically on CPU implementations and present performance analysis, optimizations and results across a set of GNN applications using the latest version of DGL(0.4.3). Across 7 applications, we achieve speed-ups ranging from1 1.5x-13x over the baseline CPU implementations.
Spatial-Spectral Regularized Local Scaling Cut for Dimensionality Reduction in Hyperspectral Image Classification
Dec 07, 2018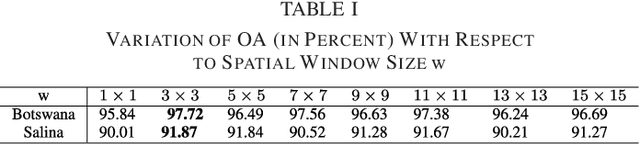
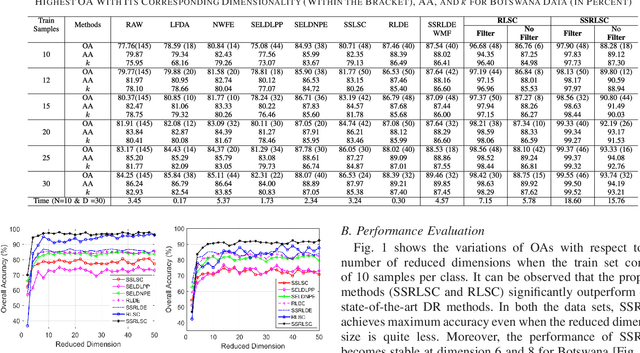
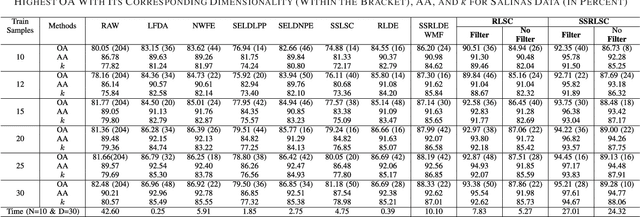
Dimensionality reduction (DR) methods have attracted extensive attention to provide discriminative information and reduce the computational burden of the hyperspectral image (HSI) classification. However, the DR methods face many challenges due to limited training samples with high dimensional spectra. To address this issue, a graph-based spatial and spectral regularized local scaling cut (SSRLSC) for DR of HSI data is proposed. The underlying idea of the proposed method is to utilize the information from both the spectral and spatial domains to achieve better classification accuracy than its spectral domain counterpart. In SSRLSC, a guided filter is initially used to smoothen and homogenize the pixels of the HSI data in order to preserve the pixel consistency. This is followed by generation of between-class and within-class dissimilarity matrices in both spectral and spatial domains by regularized local scaling cut (RLSC) and neighboring pixel local scaling cut (NPLSC) respectively. Finally, we obtain the projection matrix by optimizing the updated spatial-spectral between-class and total-class dissimilarity. The effectiveness of the proposed DR algorithm is illustrated with two popular real-world HSI datasets.
* arXiv admin note: text overlap with arXiv:1811.08223
A Semi-supervised Spatial Spectral Regularized Manifold Local Scaling Cut With HGF for Dimensionality Reduction of Hyperspectral Images
Nov 20, 2018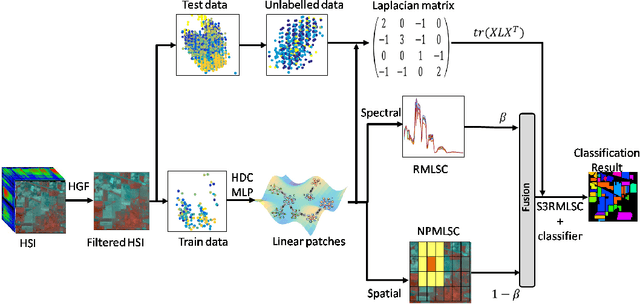
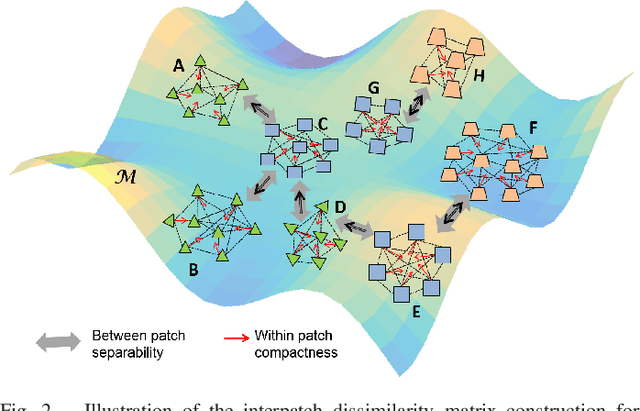
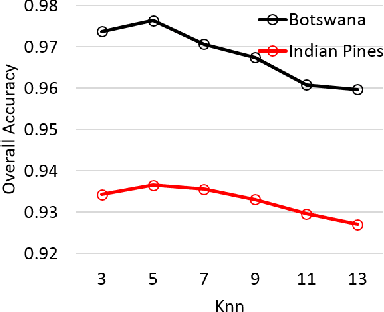
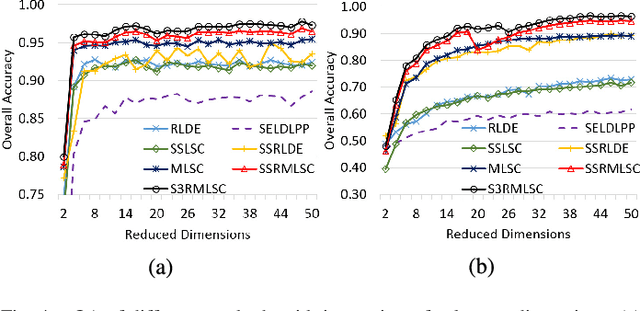
Hyperspectral images (HSI) contain a wealth of information over hundreds of contiguous spectral bands, making it possible to classify materials through subtle spectral discrepancies. However, the classification of this rich spectral information is accompanied by the challenges like high dimensionality, singularity, limited training samples, lack of labeled data samples, heteroscedasticity and nonlinearity. To address these challenges, we propose a semi-supervised graph based dimensionality reduction method named `semi-supervised spatial spectral regularized manifold local scaling cut' (S3RMLSC). The underlying idea of the proposed method is to exploit the limited labeled information from both the spectral and spatial domains along with the abundant unlabeled samples to facilitate the classification task by retaining the original distribution of the data. In S3RMLSC, a hierarchical guided filter (HGF) is initially used to smoothen the pixels of the HSI data to preserve the spatial pixel consistency. This step is followed by the construction of linear patches from the nonlinear manifold by using the maximal linear patch (MLP) criterion. Then the inter-patch and intra-patch dissimilarity matrices are constructed in both spectral and spatial domains by regularized manifold local scaling cut (RMLSC) and neighboring pixel manifold local scaling cut (NPMLSC) respectively. Finally, we obtain the projection matrix by optimizing the updated semi-supervised spatial-spectral between-patch and total-patch dissimilarity. The effectiveness of the proposed DR algorithm is illustrated with publicly available real-world HSI datasets.
A Trace Lasso Regularized L1-norm Graph Cut for Highly Correlated Noisy Hyperspectral Image
Jul 22, 2018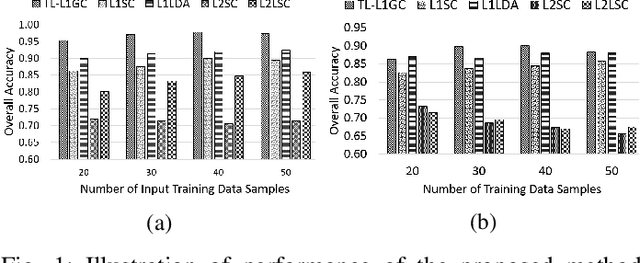
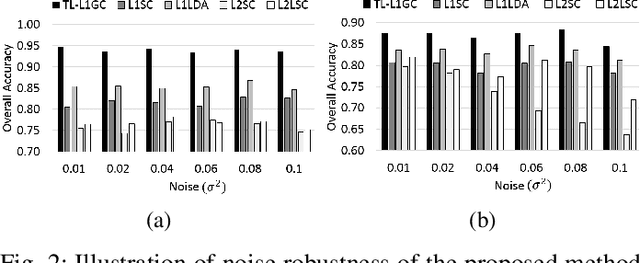

This work proposes an adaptive trace lasso regularized L1-norm based graph cut method for dimensionality reduction of Hyperspectral images, called as `Trace Lasso-L1 Graph Cut' (TL-L1GC). The underlying idea of this method is to generate the optimal projection matrix by considering both the sparsity as well as the correlation of the data samples. The conventional L2-norm used in the objective function is sensitive to noise and outliers. Therefore, in this work L1-norm is utilized as a robust alternative to L2-norm. Besides, for further improvement of the results, we use a penalty function of trace lasso with the L1GC method. It adaptively balances the L2-norm and L1-norm simultaneously by considering the data correlation along with the sparsity. We obtain the optimal projection matrix by maximizing the ratio of between-class dispersion to within-class dispersion using L1-norm with trace lasso as the penalty. Furthermore, an iterative procedure for this TL-L1GC method is proposed to solve the optimization function. The effectiveness of this proposed method is evaluated on two benchmark HSI datasets.
A Supervised Geometry-Aware Mapping Approach for Classification of Hyperspectral Images
Jul 07, 2018
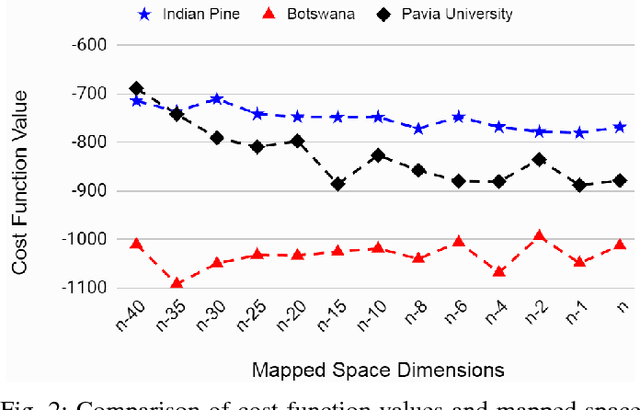

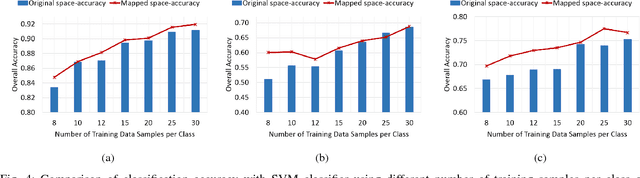
The lack of proper class discrimination among the Hyperspectral (HS) data points poses a potential challenge in HS classification. To address this issue, this paper proposes an optimal geometry-aware transformation for enhancing the classification accuracy. The underlying idea of this method is to obtain a linear projection matrix by solving a nonlinear objective function based on the intrinsic geometrical structure of the data. The objective function is constructed to quantify the discrimination between the points from dissimilar classes on the projected data space. Then the obtained projection matrix is used to linearly map the data to more discriminative space. The effectiveness of the proposed transformation is illustrated with three benchmark real-world HS data sets. The experiments reveal that the classification and dimensionality reduction methods on the projected discriminative space outperform their counterpart in the original space.
Graph Scaling Cut with L1-Norm for Classification of Hyperspectral Images
Sep 09, 2017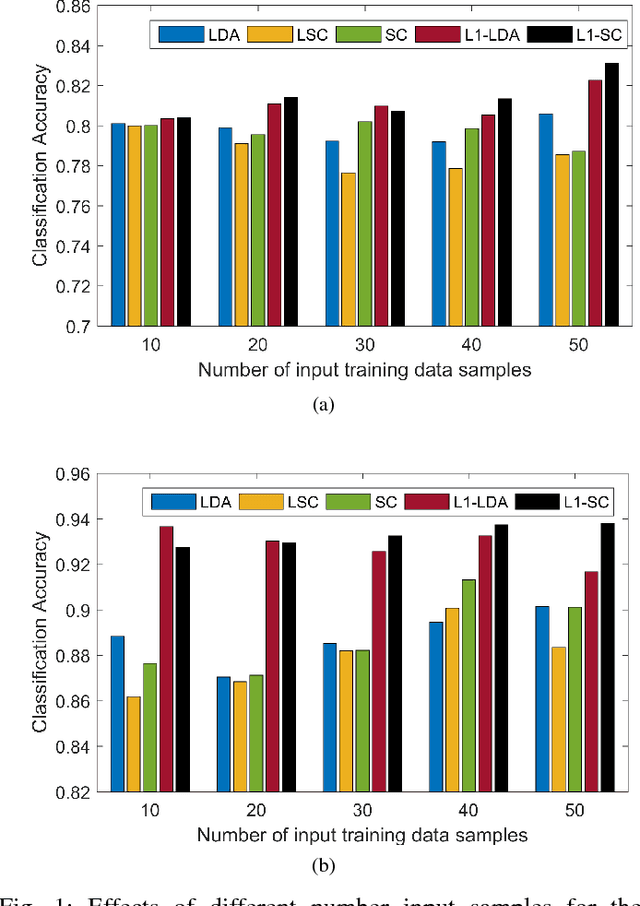


In this paper, we propose an L1 normalized graph based dimensionality reduction method for Hyperspectral images, called as L1-Scaling Cut (L1-SC). The underlying idea of this method is to generate the optimal projection matrix by retaining the original distribution of the data. Though L2-norm is generally preferred for computation, it is sensitive to noise and outliers. However, L1-norm is robust to them. Therefore, we obtain the optimal projection matrix by maximizing the ratio of between-class dispersion to within-class dispersion using L1-norm. Furthermore, an iterative algorithm is described to solve the optimization problem. The experimental results of the HSI classification confirm the effectiveness of the proposed L1-SC method on both noisy and noiseless data.
An Effective Feature Selection Method Based on Pair-Wise Feature Proximity for High Dimensional Low Sample Size Data
Aug 08, 2017


Feature selection has been studied widely in the literature. However, the efficacy of the selection criteria for low sample size applications is neglected in most cases. Most of the existing feature selection criteria are based on the sample similarity. However, the distance measures become insignificant for high dimensional low sample size (HDLSS) data. Moreover, the variance of a feature with a few samples is pointless unless it represents the data distribution efficiently. Instead of looking at the samples in groups, we evaluate their efficiency based on pairwise fashion. In our investigation, we noticed that considering a pair of samples at a time and selecting the features that bring them closer or put them far away is a better choice for feature selection. Experimental results on benchmark data sets demonstrate the effectiveness of the proposed method with low sample size, which outperforms many other state-of-the-art feature selection methods.