 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensor Processing Primitives: A Programming Abstraction for Efficiency and Portability in Deep Learning Workloads
Apr 14, 2021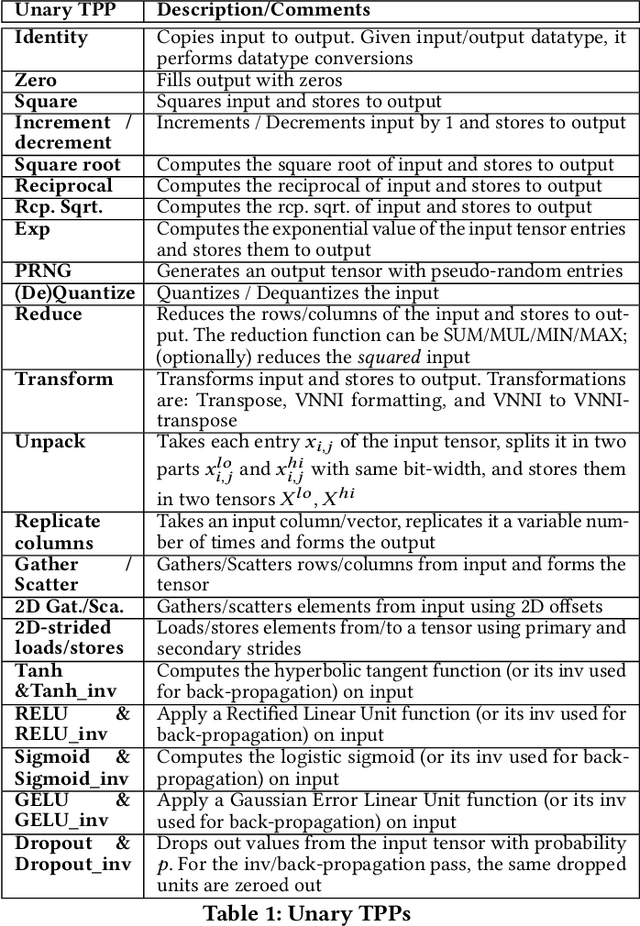
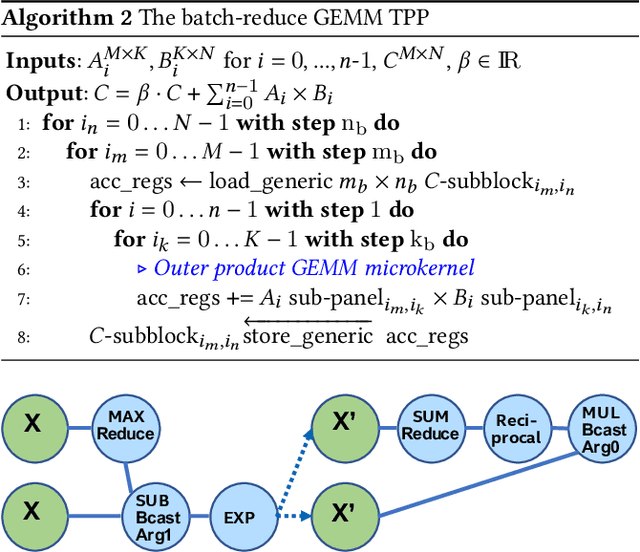
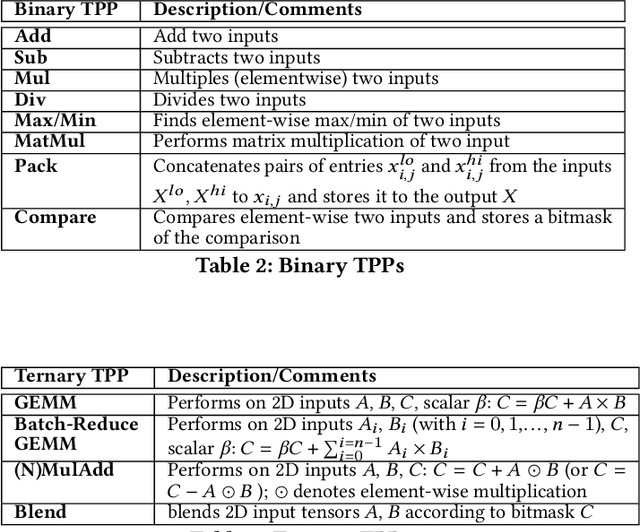
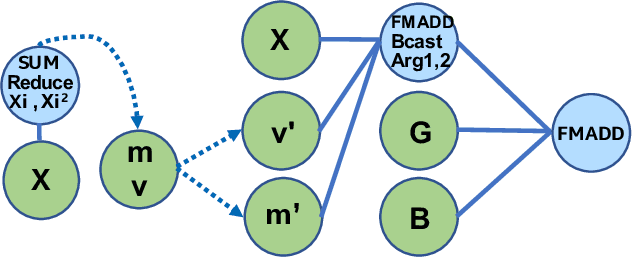
During the past decade, novel Deep Learning (DL) algorithms/workloads and hardware have been developed to tackle a wide range of problems. Despite the advances in workload/hardware ecosystems, the programming methodology of DL-systems is stagnant. DL-workloads leverage either highly-optimized, yet platform-specific and inflexible kernels from DL-libraries, or in the case of novel operators, reference implementations are built via DL-framework primitives with underwhelming performance. This work introduces the Tensor Processing Primitives (TPP), a programming abstraction striving for efficient, portable implementation of DL-workloads with high-productivity. TPPs define a compact, yet versatile set of 2D-tensor operators (or a virtual Tensor ISA), which subsequently can be utilized as building-blocks to construct complex operators on high-dimensional tensors. The TPP specification is platform-agnostic, thus code expressed via TPPs is portable, whereas the TPP implementation is highly-optimized and platform-specific. We demonstrate the efficacy of our approach using standalone kernels and end-to-end DL-workloads expressed entirely via TPPs that outperform state-of-the-art implementations on multiple platforms.