 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Anomaly Detection in Multivariate Time Series across Heterogeneous Domains
Mar 29, 2025

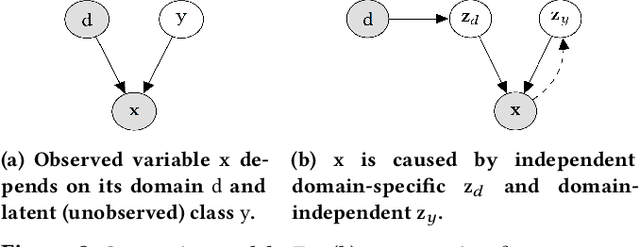
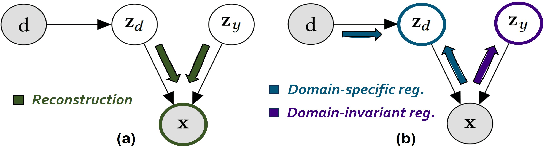
The widespread adoption of digital services, along with the scale and complexity at which they operate, has made incidents in IT operations increasingly more likely, diverse, and impactful. This has led to the rapid development of a central aspect of "Artificial Intelligence for IT Operations" (AIOps), focusing on detecting anomalies in vast amounts of multivariate time series data generated by service entities. In this paper, we begin by introducing a unifying framework for benchmarking unsupervised anomaly detection (AD) methods, and highlight the problem of shifts in normal behaviors that can occur in practical AIOps scenarios. To tackle anomaly detection under domain shift, we then cast the problem in the framework of domain generalization and propose a novel approach, Domain-Invariant VAE for Anomaly Detection (DIVAD), to learn domain-invariant representations for unsupervised anomaly detection. Our evaluation results using the Exathlon benchmark show that the two main DIVAD variants significantly outperform the best unsupervised AD method in maximum performance, with 20% and 15% improvements in maximum peak F1-scores, respectively. Evaluation using the Application Server Dataset further demonstrates the broader applicability of our domain generalization methods.
AnomalyBench: An Open Benchmark for Explainable Anomaly Detection
Oct 10, 2020
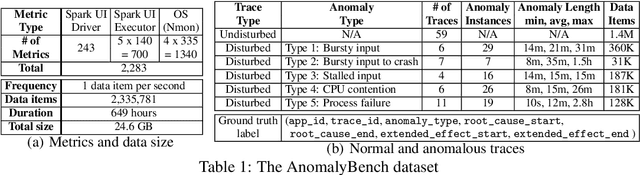
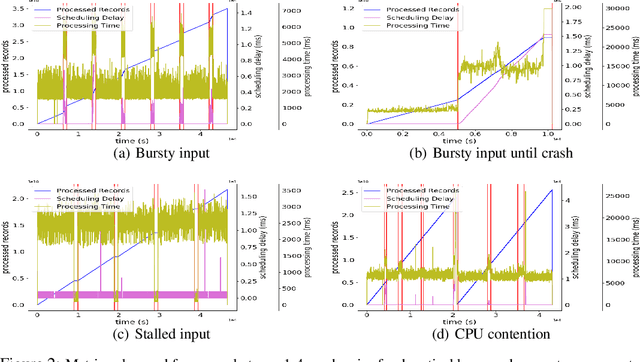

Access to high-quality data repositories and benchmarks have been instrumental in advancing the state of the art in many domains, as they provide the research community a common ground for training, testing, evaluating, comparing, and experimenting with novel machine learning models. Lack of such community resources for anomaly detection (AD) severely limits progress. In this report, we present AnomalyBench, the first comprehensive benchmark for explainable AD over high-dimensional (2000+) time series data. AnomalyBench has been systematically constructed based on real data traces from ~100 repeated executions of 10 large-scale stream processing jobs on a Spark cluster. 30+ of these executions were disturbed by introducing ~100 instances of different types of anomalous events (e.g., misbehaving inputs, resource contention, process failures). For each of these anomaly instances, ground truth labels for the root-cause interval as well as those for the effect interval are available, providing a means for supporting both AD tasks and explanation discovery (ED) tasks via root-cause analysis. We demonstrate the key design features and practical utility of AnomalyBench through an experimental study with three state-of-the-art semi-supervised AD techniques.