 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass-Weighted Evaluation Metrics for Imbalanced Data Classification
Oct 12, 2020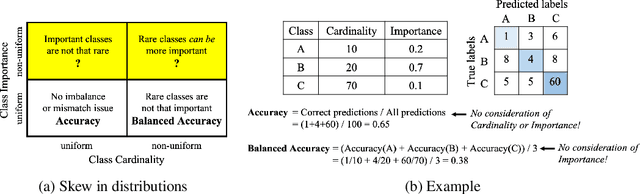
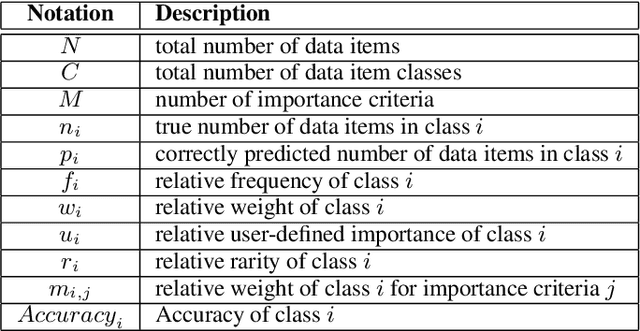
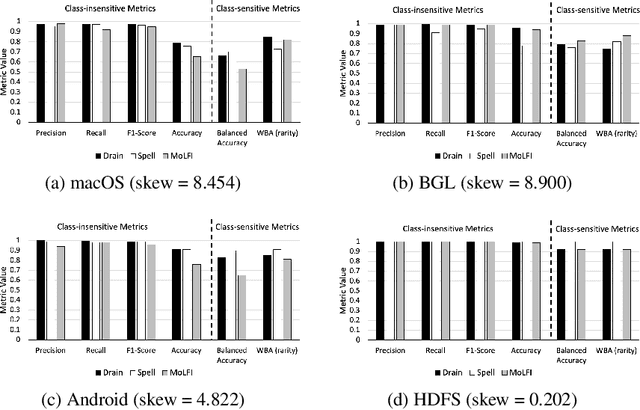
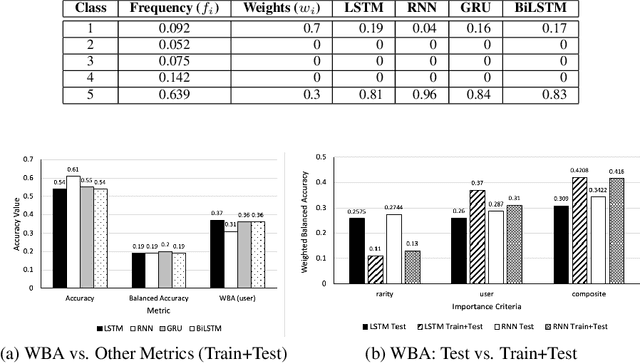
Class distribution skews in imbalanced datasets may lead to models with prediction bias towards majority classes, making fair assessment of classifiers a challenging task. Balanced Accuracy is a popular metric used to evaluate a classifier's prediction performance under such scenarios. However, this metric falls short when classes vary in importance, especially when class importance is skewed differently from class cardinality distributions. In this paper, we propose a simple and general-purpose evaluation framework for imbalanced data classification that is sensitive to arbitrary skews in class cardinalities and importances. Experiments with several state-of-the-art classifiers tested on real-world datasets and benchmarks from two different domains show that our new framework is more effective than Balanced Accuracy -- not only in evaluating and ranking model predictions, but also in training the models themselves.
MISIM: An End-to-End Neural Code Similarity System
Jun 15, 2020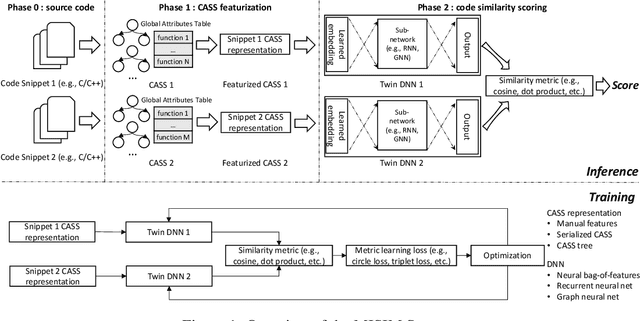
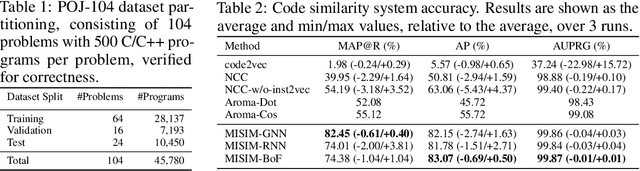
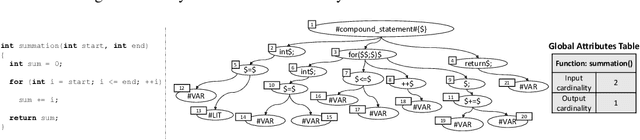
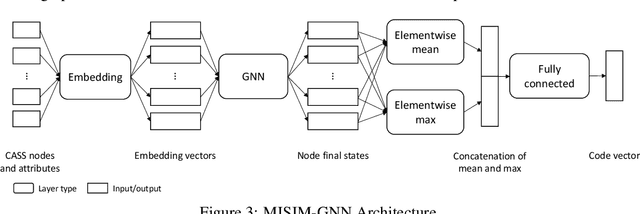
Code similarity systems are integral to a range of applications from code recommendation to automated construction of software tests and defect mitigation. In this paper, we present Machine Inferred Code Similarity (MISIM), a novel end-to-end code similarity system that consists of two core components. First, MISIM uses a novel context-aware similarity structure, which is designed to aid in lifting semantic meaning from code syntax. Second, MISIM provides a neural-based code similarity scoring system, which can be implemented with various neural network algorithms and topologies with learned parameters. We compare MISIM to three other state-of-the-art code similarity systems: (i) code2vec, (ii) Neural Code Comprehension, and (iii) Aroma. In our experimental evaluation across 45,780 programs, MISIM consistently outperformed all three systems, often by a large factor (upwards of 40.6x).
Context-Aware Parse Trees
Mar 24, 2020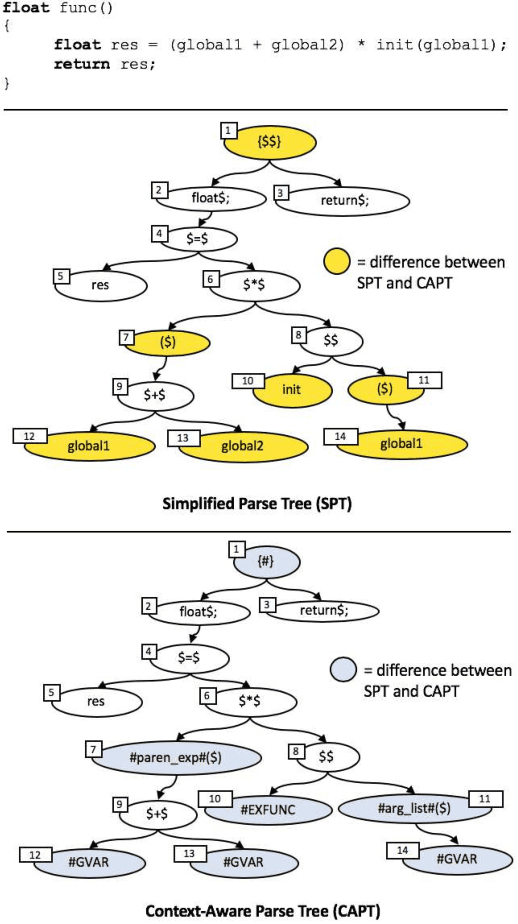
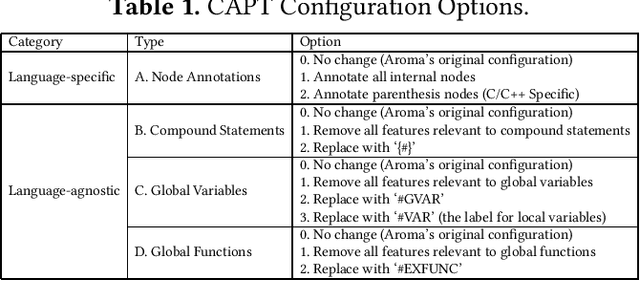
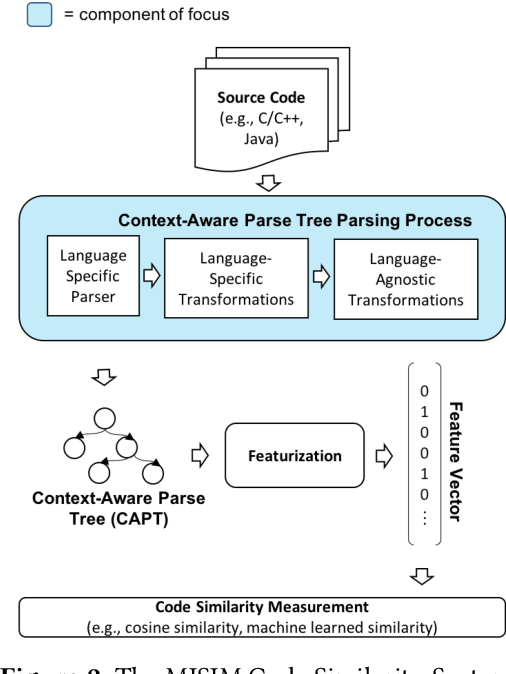
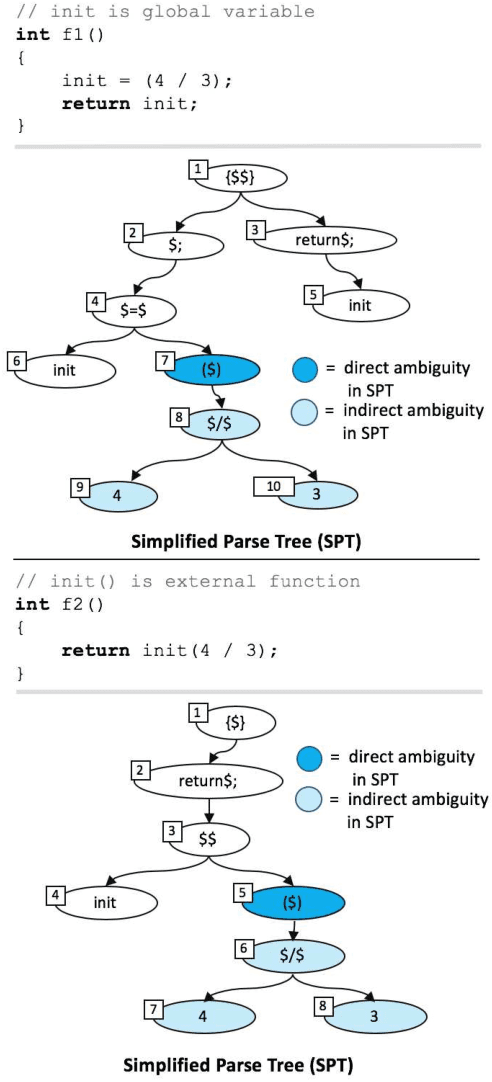
The simplified parse tree (SPT) presented in Aroma, a state-of-the-art code recommendation system, is a tree-structured representation used to infer code semantics by capturing program \emph{structure} rather than program \emph{syntax}. This is a departure from the classical abstract syntax tree, which is principally driven by programming language syntax. While we believe a semantics-driven representation is desirable, the specifics of an SPT's construction can impact its performance. We analyze these nuances and present a new tree structure, heavily influenced by Aroma's SPT, called a \emph{context-aware parse tree} (CAPT). CAPT enhances SPT by providing a richer level of semantic representation. Specifically, CAPT provides additional binding support for language-specific techniques for adding semantically-salient features, and language-agnostic techniques for removing syntactically-present but semantically-irrelevant features. Our research quantitatively demonstrates the value of our proposed semantically-salient features, enabling a specific CAPT configuration to be 39\% more accurate than SPT across the 48,610 programs we analyzed.
Learning Fitness Functions for Genetic Algorithms
Sep 10, 2019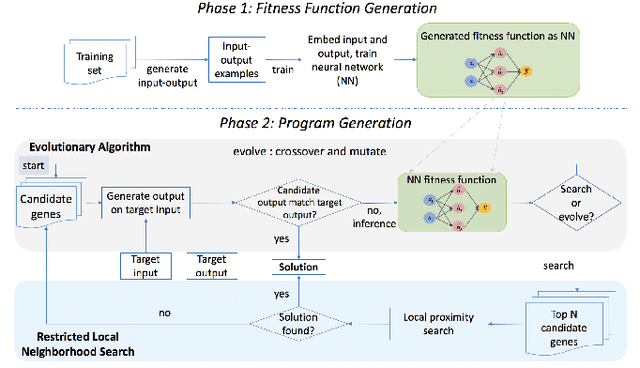
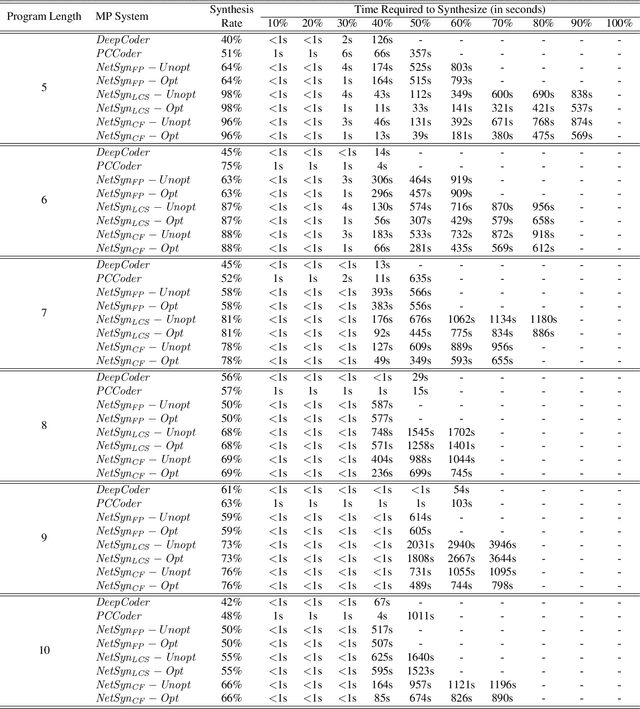
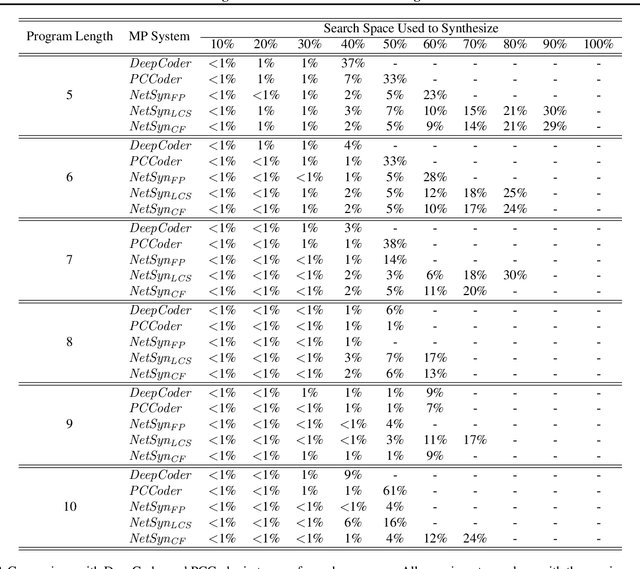
A genetic algorithm (GA) attempts to solve a problem using a pool of potential solutions that are iteratively refined using various selection techniques. Although GAs have been used successfully for many problems, one criticism is that hand-crafting a GA's fitness function, the test that aims to effectively guide its evolution, can be notably challenging. Moreover, the complexity of a GA's fitness function tends to grow proportionally with the complexity of the problem being solved. In this work, we present a novel approach to learn a GA's fitness function. For the purpose of simplicity, we limit the demonstration of this technique to automatic software program generation. However, our system has no specific restrictions that prevent it from being applied to other domains. We also augment the GA evolutionary process with a minimally intrusive search heuristic. This heuristic improves the GA's ability to discover correct programs from ones that are approximately correct and does so with negligible computational overhead. We compare our approach to two state-of-the-art program generation systems and demonstrate that it finds more correct programs with fewer candidate program generations.