 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Topic and Syntax Modeling with Part-of-Speech LDA
Mar 12, 2013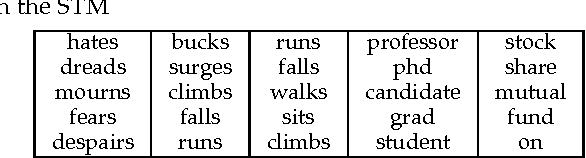
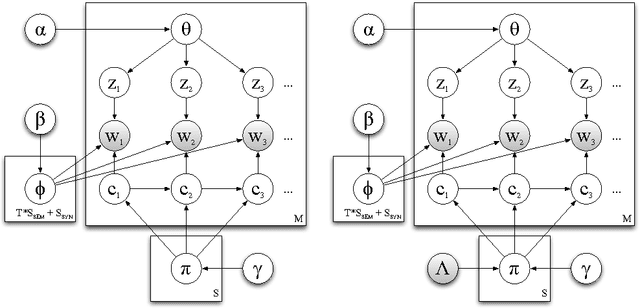
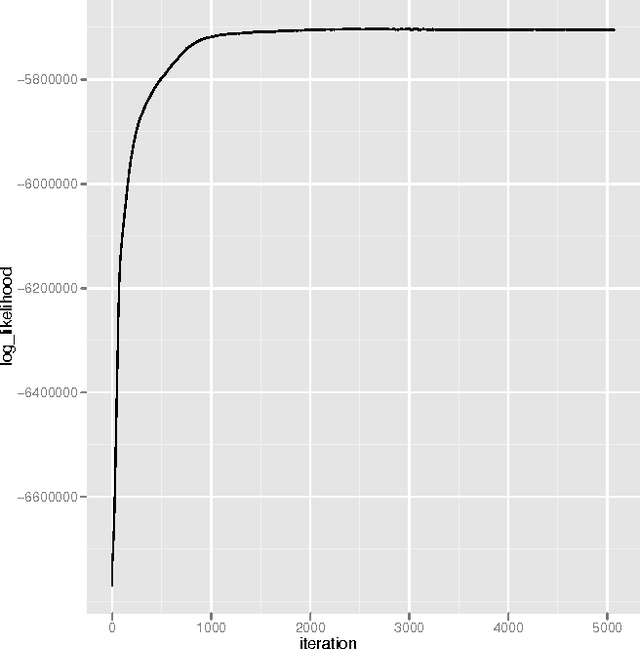
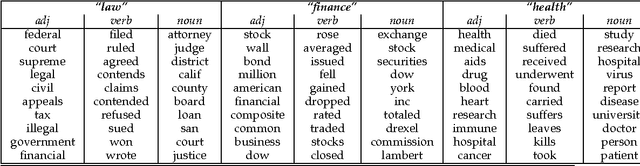
This article presents a probabilistic generative model for text based on semantic topics and syntactic classes called Part-of-Speech LDA (POSLDA). POSLDA simultaneously uncovers short-range syntactic patterns (syntax) and long-range semantic patterns (topics) that exist in document collections. This results in word distributions that are specific to both topics (sports, education, ...) and parts-of-speech (nouns, verbs, ...). For example, multinomial distributions over words are uncovered that can be understood as "nouns about weather" or "verbs about law". We describe the model and an approximate inference algorithm and then demonstrate the quality of the learned topics both qualitatively and quantitatively. Then, we discuss an NLP application where the output of POSLDA can lead to strong improvements in quality: unsupervised part-of-speech tagging. We describe algorithms for this task that make use of POSLDA-learned distributions that result in improved performance beyond the state of the art.