 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural reality of argument structure constructions
Feb 24, 2022

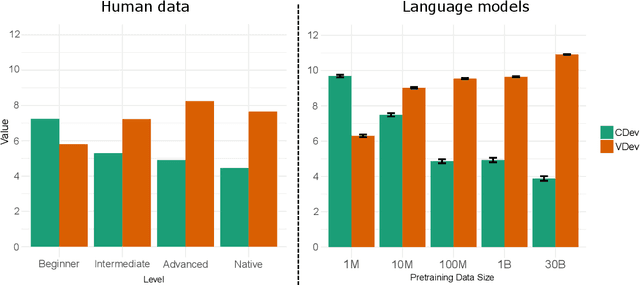
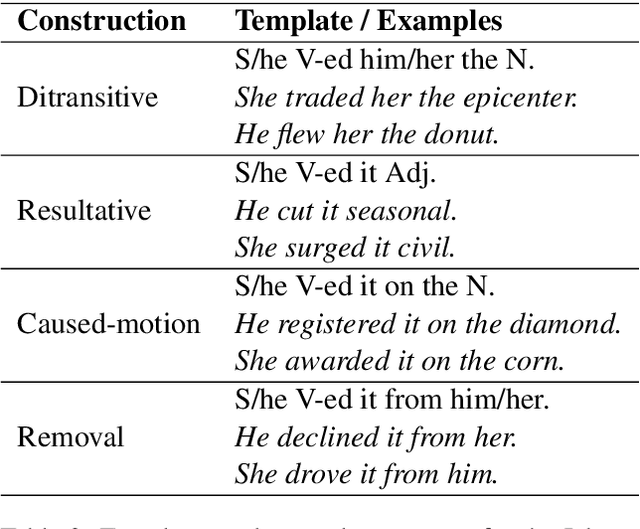
In lexicalist linguistic theories, argument structure is assumed to be predictable from the meaning of verbs. As a result, the verb is the primary determinant of the meaning of a clause. In contrast, construction grammarians propose that argument structure is encoded in constructions (or form-meaning pairs) that are distinct from verbs. Decades of psycholinguistic research have produced substantial empirical evidence in favor of the construction view. Here we adapt several psycholinguistic studies to probe for the existence of argument structure constructions (ASCs) in Transformer-based language models (LMs). First, using a sentence sorting experiment, we find that sentences sharing the same construction are closer in embedding space than sentences sharing the same verb. Furthermore, LMs increasingly prefer grouping by construction with more input data, mirroring the behaviour of non-native language learners. Second, in a "Jabberwocky" priming-based experiment, we find that LMs associate ASCs with meaning, even in semantically nonsensical sentences. Our work offers the first evidence for ASCs in LMs and highlights the potential to devise novel probing methods grounded in psycholinguistic research.
How is BERT surprised? Layerwise detection of linguistic anomalies
May 16, 2021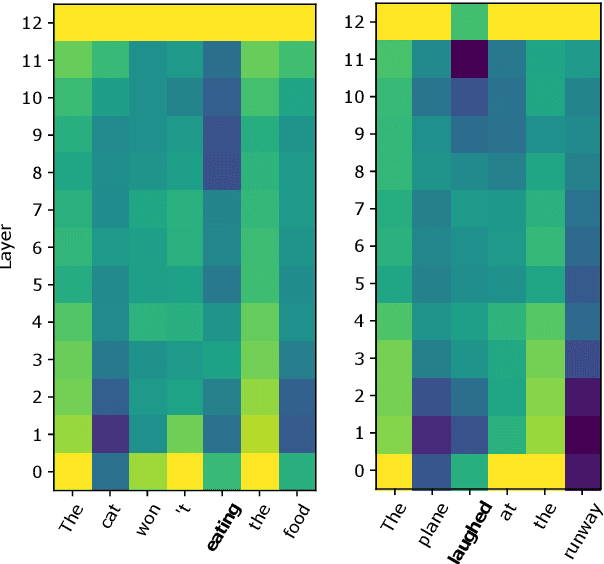
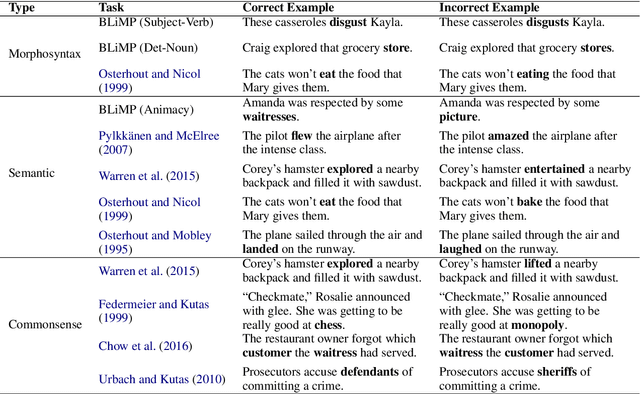
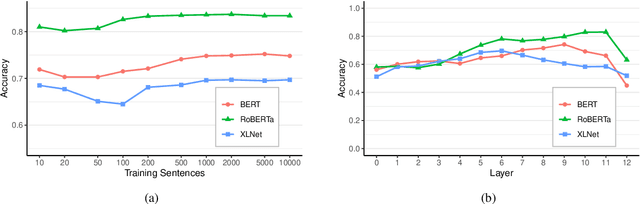
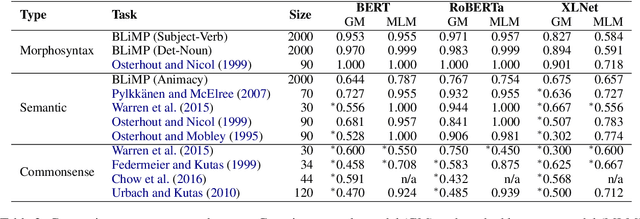
Transformer language models have shown remarkable ability in detecting when a word is anomalous in context, but likelihood scores offer no information about the cause of the anomaly. In this work, we use Gaussian models for density estimation at intermediate layers of three language models (BERT, RoBERTa, and XLNet), and evaluate our method on BLiMP, a grammaticality judgement benchmark. In lower layers, surprisal is highly correlated to low token frequency, but this correlation diminishes in upper layers. Next, we gather datasets of morphosyntactic, semantic, and commonsense anomalies from psycholinguistic studies; we find that the best performing model RoBERTa exhibits surprisal in earlier layers when the anomaly is morphosyntactic than when it is semantic, while commonsense anomalies do not exhibit surprisal at any intermediate layer. These results suggest that language models employ separate mechanisms to detect different types of linguistic anomalies.
Word class flexibility: A deep contextualized approach
Sep 19, 2020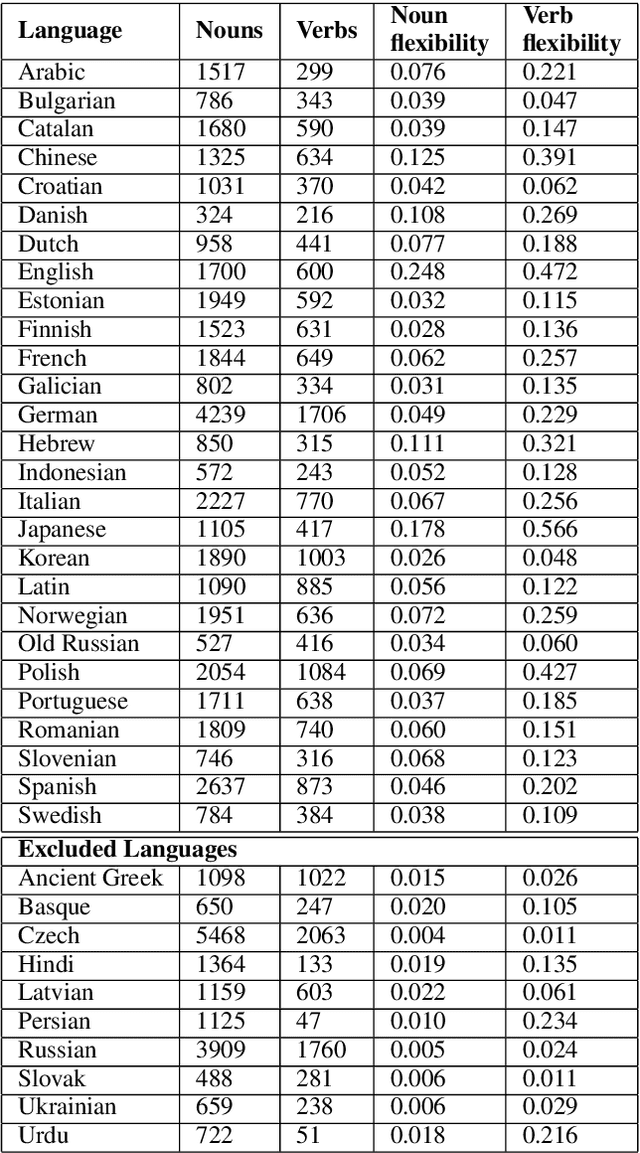
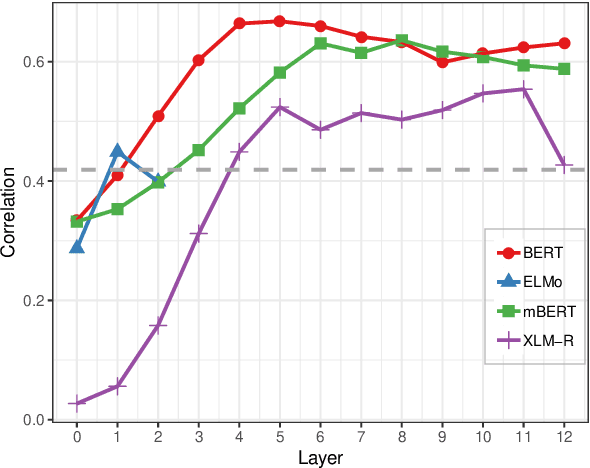
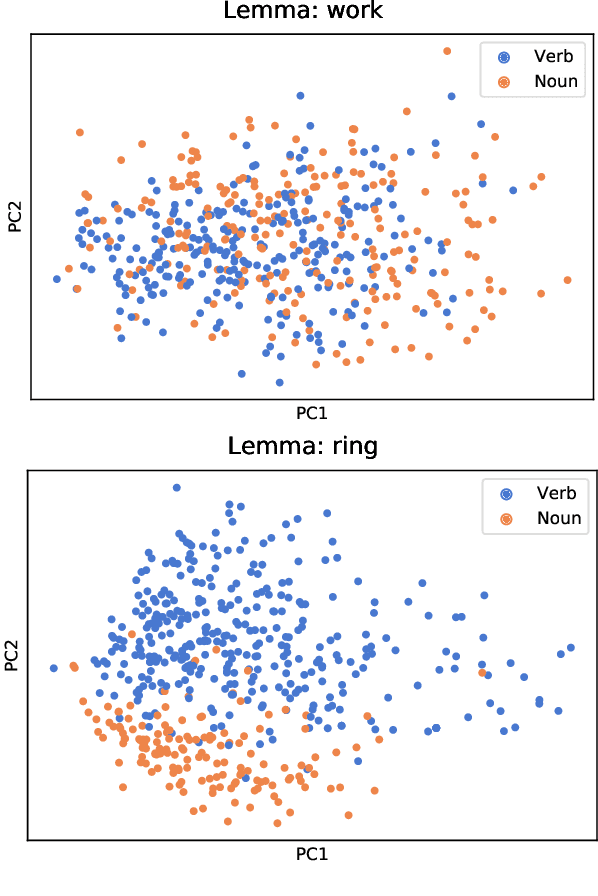
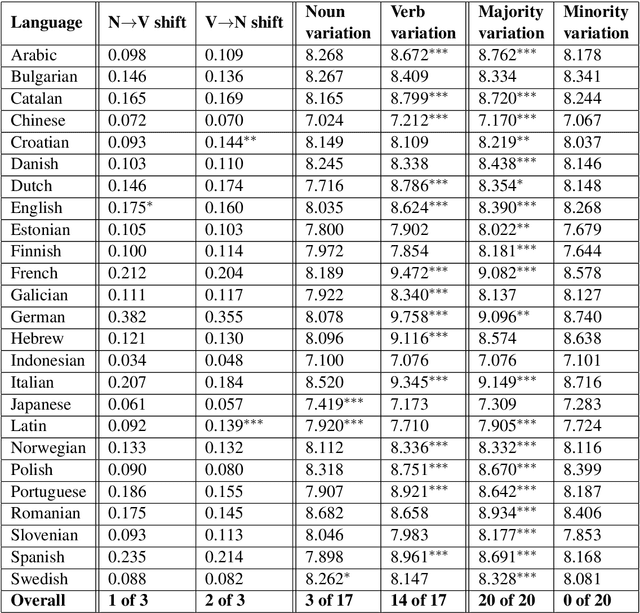
Word class flexibility refers to the phenomenon whereby a single word form is used across different grammatical categories. Extensive work in linguistic typology has sought to characterize word class flexibility across languages, but quantifying this phenomenon accurately and at scale has been fraught with difficulties. We propose a principled methodology to explore regularity in word class flexibility. Our method builds on recent work in contextualized word embeddings to quantify semantic shift between word classes (e.g., noun-to-verb, verb-to-noun), and we apply this method to 37 languages. We find that contextualized embeddings not only capture human judgment of class variation within words in English, but also uncover shared tendencies in class flexibility across languages. Specifically, we find greater semantic variation when flexible lemmas are used in their dominant word class, supporting the view that word class flexibility is a directional process. Our work highlights the utility of deep contextualized models in linguistic typology.