 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompute Cost Amortized Transformer for Streaming ASR
Jul 05, 2022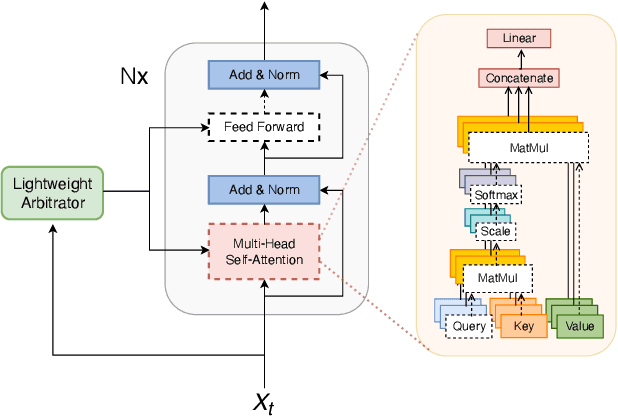
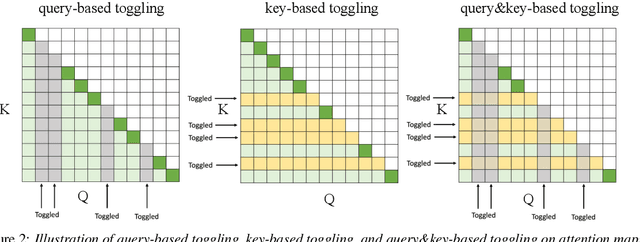
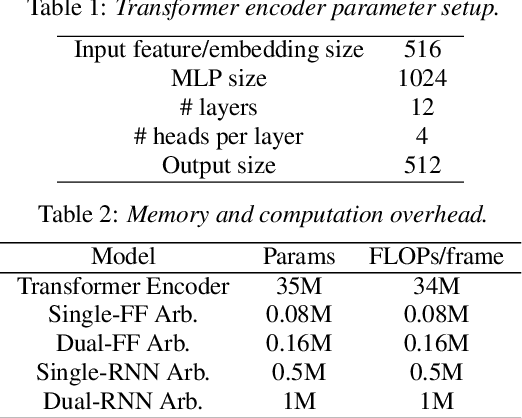
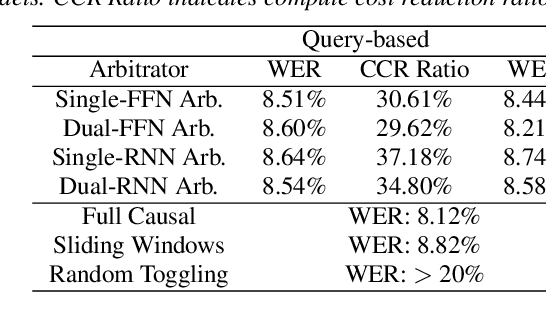
We present a streaming, Transformer-based end-to-end automatic speech recognition (ASR) architecture which achieves efficient neural inference through compute cost amortization. Our architecture creates sparse computation pathways dynamically at inference time, resulting in selective use of compute resources throughout decoding, enabling significant reductions in compute with minimal impact on accuracy. The fully differentiable architecture is trained end-to-end with an accompanying lightweight arbitrator mechanism operating at the frame-level to make dynamic decisions on each input while a tunable loss function is used to regularize the overall level of compute against predictive performance. We report empirical results from experiments using the compute amortized Transformer-Transducer (T-T) model conducted on LibriSpeech data. Our best model can achieve a 60% compute cost reduction with only a 3% relative word error rate (WER) increase.
Learning a Neural Diff for Speech Models
Aug 17, 2021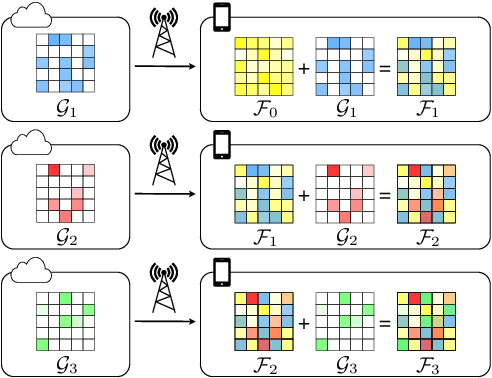
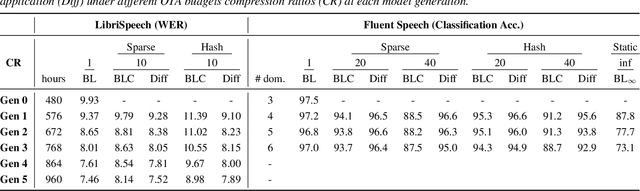
As more speech processing applications execute locally on edge devices, a set of resource constraints must be considered. In this work we address one of these constraints, namely over-the-network data budgets for transferring models from server to device. We present neural update approaches for release of subsequent speech model generations abiding by a data budget. We detail two architecture-agnostic methods which learn compact representations for transmission to devices. We experimentally validate our techniques with results on two tasks (automatic speech recognition and spoken language understanding) on open source data sets by demonstrating when applied in succession, our budgeted updates outperform comparable model compression baselines by significant margins.
Bifocal Neural ASR: Exploiting Keyword Spotting for Inference Optimization
Aug 03, 2021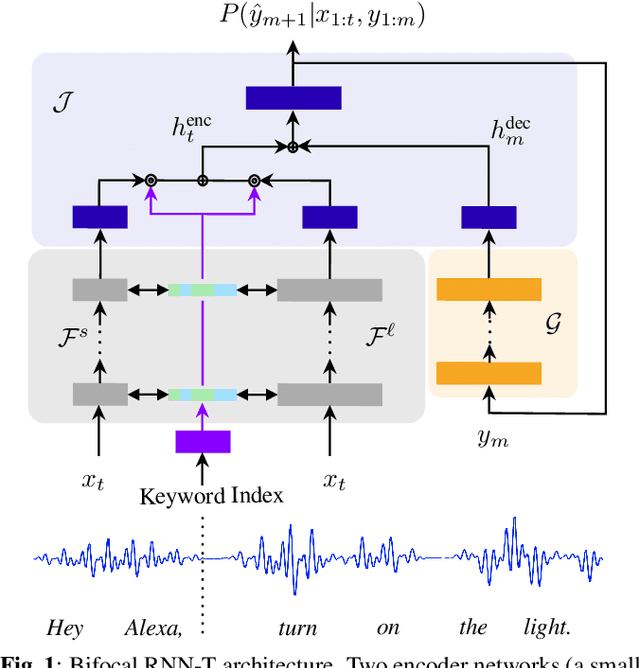
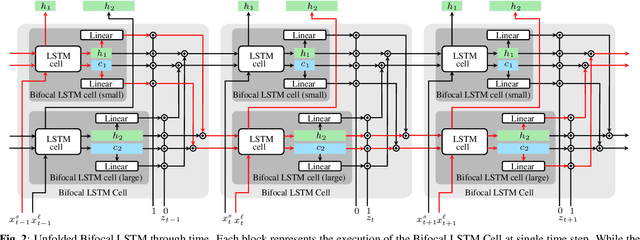
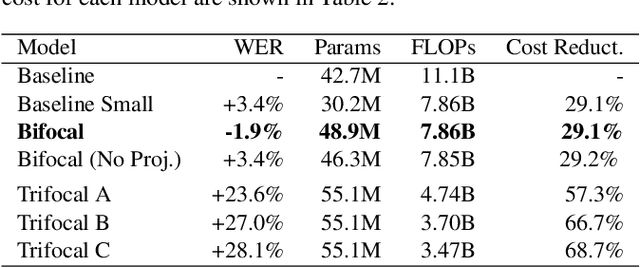
We present Bifocal RNN-T, a new variant of the Recurrent Neural Network Transducer (RNN-T) architecture designed for improved inference time latency on speech recognition tasks. The architecture enables a dynamic pivot for its runtime compute pathway, namely taking advantage of keyword spotting to select which component of the network to execute for a given audio frame. To accomplish this, we leverage a recurrent cell we call the Bifocal LSTM (BFLSTM), which we detail in the paper. The architecture is compatible with other optimization strategies such as quantization, sparsification, and applying time-reduction layers, making it especially applicable for deployed, real-time speech recognition settings. We present the architecture and report comparative experimental results on voice-assistant speech recognition tasks. Specifically, we show our proposed Bifocal RNN-T can improve inference cost by 29.1% with matching word error rates and only a minor increase in memory size.
Amortized Neural Networks for Low-Latency Speech Recognition
Aug 03, 2021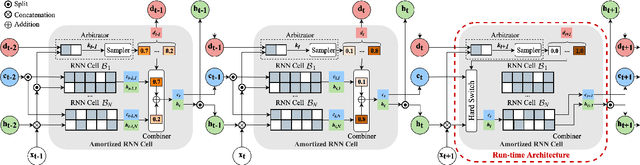
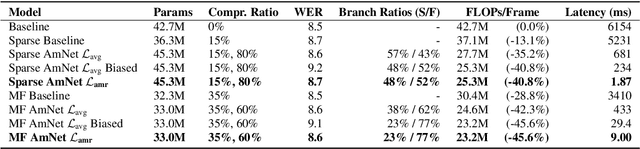
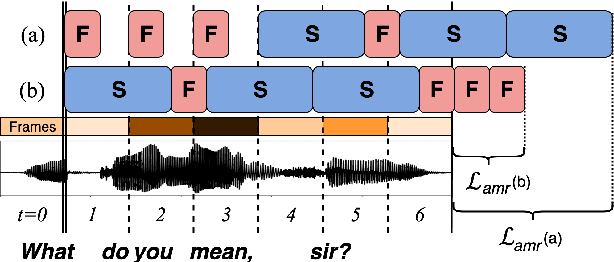
We introduce Amortized Neural Networks (AmNets), a compute cost- and latency-aware network architecture particularly well-suited for sequence modeling tasks. We apply AmNets to the Recurrent Neural Network Transducer (RNN-T) to reduce compute cost and latency for an automatic speech recognition (ASR) task. The AmNets RNN-T architecture enables the network to dynamically switch between encoder branches on a frame-by-frame basis. Branches are constructed with variable levels of compute cost and model capacity. Here, we achieve variable compute for two well-known candidate techniques: one using sparse pruning and the other using matrix factorization. Frame-by-frame switching is determined by an arbitrator network that requires negligible compute overhead. We present results using both architectures on LibriSpeech data and show that our proposed architecture can reduce inference cost by up to 45\% and latency to nearly real-time without incurring a loss in accuracy.