 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBifocal Neural ASR: Exploiting Keyword Spotting for Inference Optimization
Paper and Code
Aug 03, 2021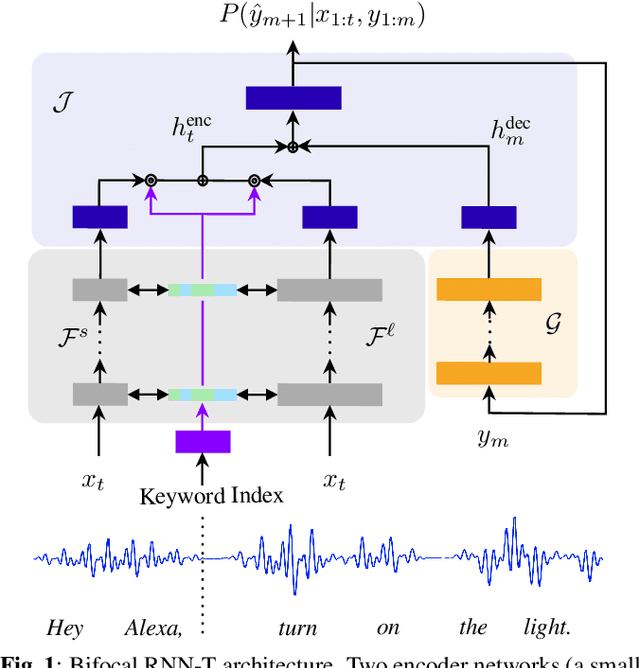
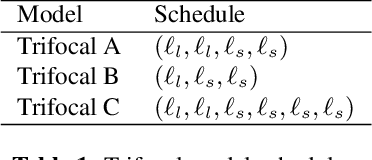
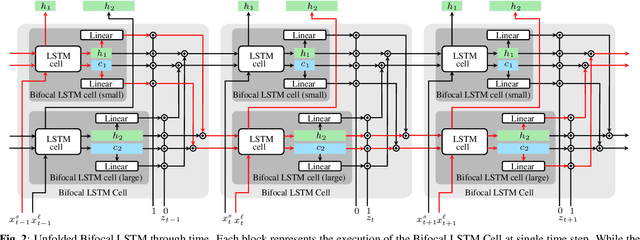
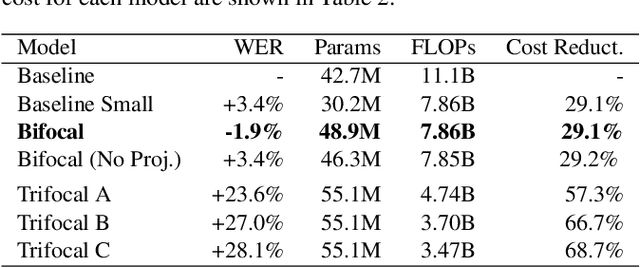
We present Bifocal RNN-T, a new variant of the Recurrent Neural Network Transducer (RNN-T) architecture designed for improved inference time latency on speech recognition tasks. The architecture enables a dynamic pivot for its runtime compute pathway, namely taking advantage of keyword spotting to select which component of the network to execute for a given audio frame. To accomplish this, we leverage a recurrent cell we call the Bifocal LSTM (BFLSTM), which we detail in the paper. The architecture is compatible with other optimization strategies such as quantization, sparsification, and applying time-reduction layers, making it especially applicable for deployed, real-time speech recognition settings. We present the architecture and report comparative experimental results on voice-assistant speech recognition tasks. Specifically, we show our proposed Bifocal RNN-T can improve inference cost by 29.1% with matching word error rates and only a minor increase in memory size.