 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmortized Neural Networks for Low-Latency Speech Recognition
Paper and Code
Aug 03, 2021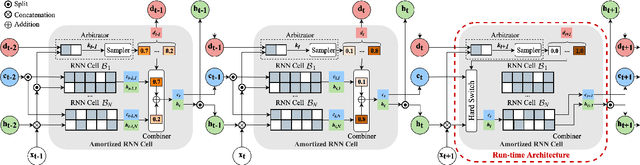
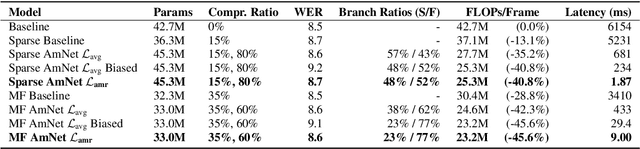
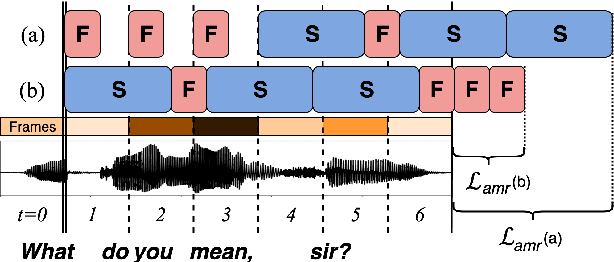
We introduce Amortized Neural Networks (AmNets), a compute cost- and latency-aware network architecture particularly well-suited for sequence modeling tasks. We apply AmNets to the Recurrent Neural Network Transducer (RNN-T) to reduce compute cost and latency for an automatic speech recognition (ASR) task. The AmNets RNN-T architecture enables the network to dynamically switch between encoder branches on a frame-by-frame basis. Branches are constructed with variable levels of compute cost and model capacity. Here, we achieve variable compute for two well-known candidate techniques: one using sparse pruning and the other using matrix factorization. Frame-by-frame switching is determined by an arbitrator network that requires negligible compute overhead. We present results using both architectures on LibriSpeech data and show that our proposed architecture can reduce inference cost by up to 45\% and latency to nearly real-time without incurring a loss in accuracy.