 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Estimation and Learning under Temporal Distribution Shift
May 21, 2025In this paper, we study the problem of estimation and learning under temporal distribution shift. Consider an observation sequence of length $n$, which is a noisy realization of a time-varying groundtruth sequence. Our focus is to develop methods to estimate the groundtruth at the final time-step while providing sharp point-wise estimation error rates. We show that, without prior knowledge on the level of temporal shift, a wavelet soft-thresholding estimator provides an optimal estimation error bound for the groundtruth. Our proposed estimation method generalizes existing researches Mazzetto and Upfal (2023) by establishing a connection between the sequence's non-stationarity level and the sparsity in the wavelet-transformed domain. Our theoretical findings are validated by numerical experiments. Additionally, we applied the estimator to derive sparsity-aware excess risk bounds for binary classification under distribution shift and to develop computationally efficient training objectives. As a final contribution, we draw parallels between our results and the classical signal processing problem of total-variation denoising (Mammen and van de Geer,1997; Tibshirani, 2014), uncovering novel optimal algorithms for such task.
Accelerator-Aware Training for Transducer-Based Speech Recognition
May 12, 2023



Machine learning model weights and activations are represented in full-precision during training. This leads to performance degradation in runtime when deployed on neural network accelerator (NNA) chips, which leverage highly parallelized fixed-point arithmetic to improve runtime memory and latency. In this work, we replicate the NNA operators during the training phase, accounting for the degradation due to low-precision inference on the NNA in back-propagation. Our proposed method efficiently emulates NNA operations, thus foregoing the need to transfer quantization error-prone data to the Central Processing Unit (CPU), ultimately reducing the user perceived latency (UPL). We apply our approach to Recurrent Neural Network-Transducer (RNN-T), an attractive architecture for on-device streaming speech recognition tasks. We train and evaluate models on 270K hours of English data and show a 5-7% improvement in engine latency while saving up to 10% relative degradation in WER.
* Accepted to SLT 2022
Sub-8-bit quantization for on-device speech recognition: a regularization-free approach
Oct 17, 2022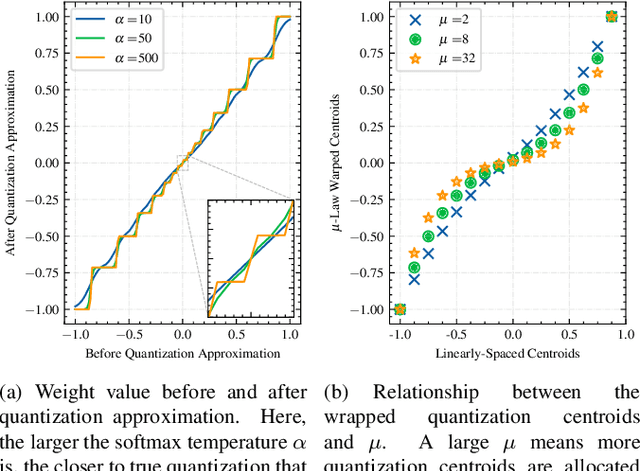

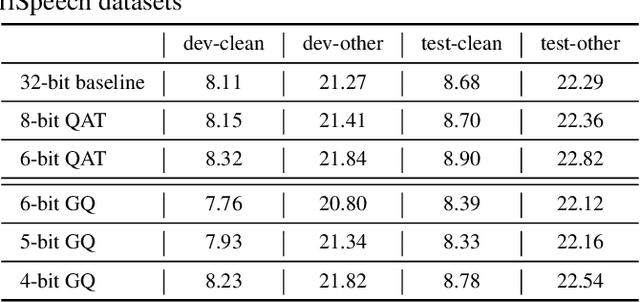
For on-device automatic speech recognition (ASR), quantization aware training (QAT) is ubiquitous to achieve the trade-off between model predictive performance and efficiency. Among existing QAT methods, one major drawback is that the quantization centroids have to be predetermined and fixed. To overcome this limitation, we introduce a regularization-free, "soft-to-hard" compression mechanism with self-adjustable centroids in a mu-Law constrained space, resulting in a simpler yet more versatile quantization scheme, called General Quantizer (GQ). We apply GQ to ASR tasks using Recurrent Neural Network Transducer (RNN-T) and Conformer architectures on both LibriSpeech and de-identified far-field datasets. Without accuracy degradation, GQ can compress both RNN-T and Conformer into sub-8-bit, and for some RNN-T layers, to 1-bit for fast and accurate inference. We observe a 30.73% memory footprint saving and 31.75% user-perceived latency reduction compared to 8-bit QAT via physical device benchmarking.
Sub-8-Bit Quantization Aware Training for 8-Bit Neural Network Accelerator with On-Device Speech Recognition
Jun 30, 2022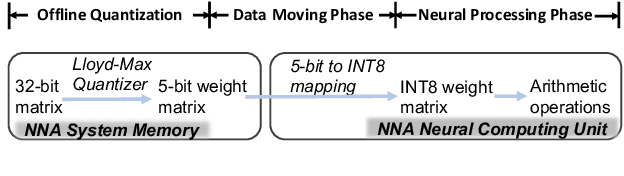
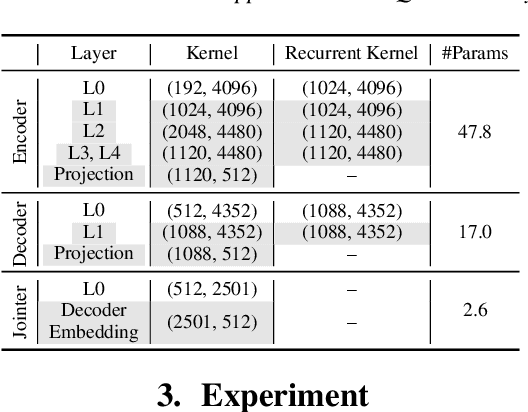
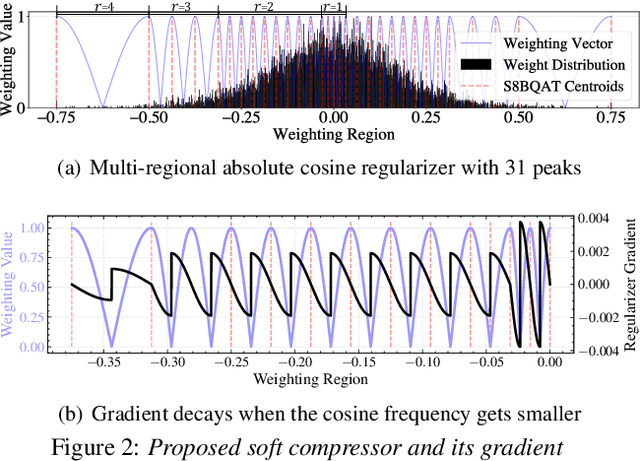
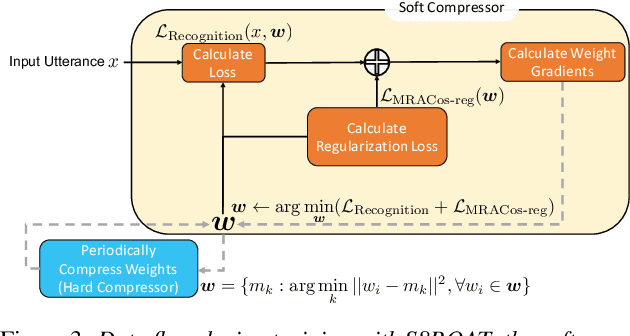
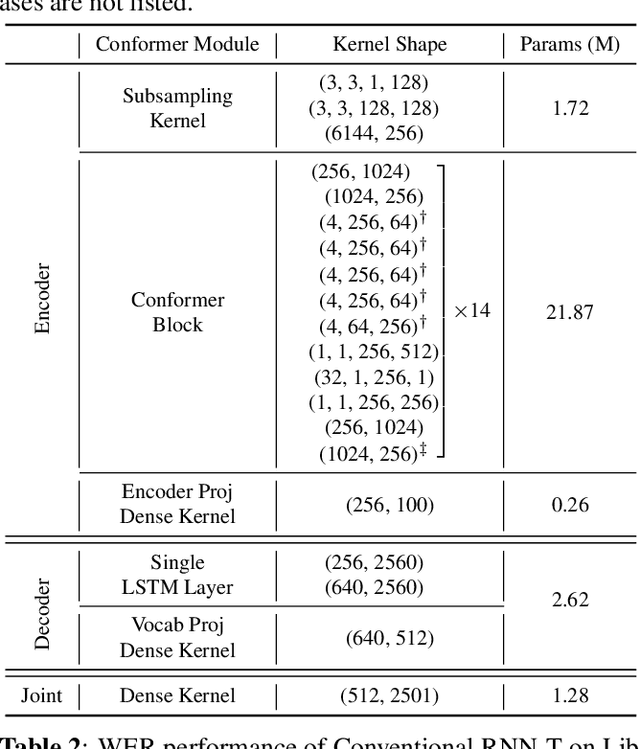
We present a novel sub-8-bit quantization-aware training (S8BQAT) scheme for 8-bit neural network accelerators. Our method is inspired from Lloyd-Max compression theory with practical adaptations for a feasible computational overhead during training. With the quantization centroids derived from a 32-bit baseline, we augment training loss with a Multi-Regional Absolute Cosine (MRACos) regularizer that aggregates weights towards their nearest centroid, effectively acting as a pseudo compressor. Additionally, a periodically invoked hard compressor is introduced to improve the convergence rate by emulating runtime model weight quantization. We apply S8BQAT on speech recognition tasks using Recurrent Neural NetworkTransducer (RNN-T) architecture. With S8BQAT, we are able to increase the model parameter size to reduce the word error rate by 4-16% relatively, while still improving latency by 5%.
Sparsification via Compressed Sensing for Automatic Speech Recognition
Feb 09, 2021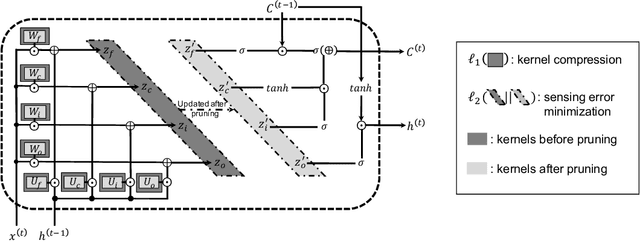
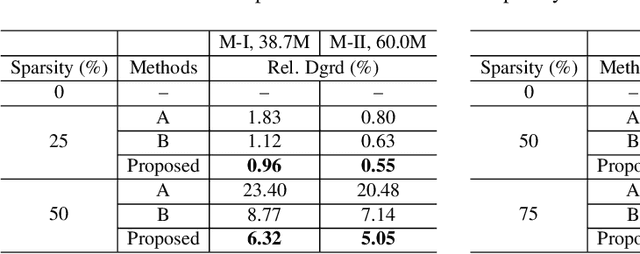
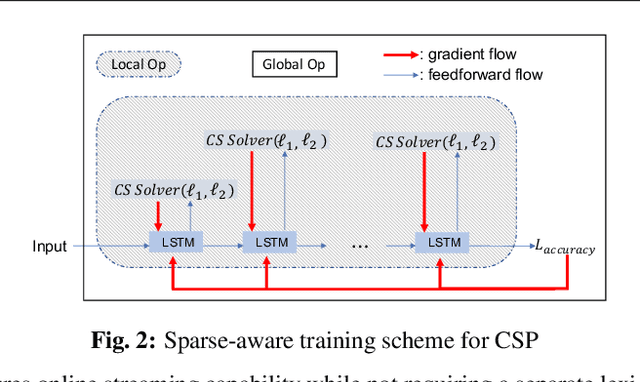
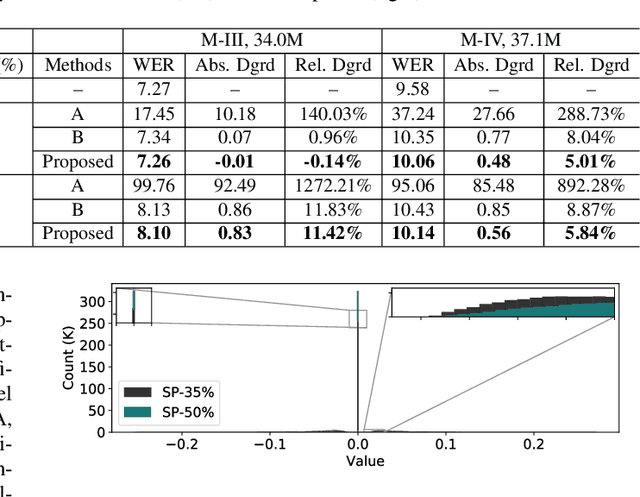
In order to achieve high accuracy for machine learning (ML) applications, it is essential to employ models with a large number of parameters. Certain applications, such as Automatic Speech Recognition (ASR), however, require real-time interactions with users, hence compelling the model to have as low latency as possible. Deploying large scale ML applications thus necessitates model quantization and compression, especially when running ML models on resource constrained devices. For example, by forcing some of the model weight values into zero, it is possible to apply zero-weight compression, which reduces both the model size and model reading time from the memory. In the literature, such methods are referred to as sparse pruning. The fundamental questions are when and which weights should be forced to zero, i.e. be pruned. In this work, we propose a compressed sensing based pruning (CSP) approach to effectively address those questions. By reformulating sparse pruning as a sparsity inducing and compression-error reduction dual problem, we introduce the classic compressed sensing process into the ML model training process. Using ASR task as an example, we show that CSP consistently outperforms existing approaches in the literature.