 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerator-Aware Training for Transducer-Based Speech Recognition
May 12, 2023



Machine learning model weights and activations are represented in full-precision during training. This leads to performance degradation in runtime when deployed on neural network accelerator (NNA) chips, which leverage highly parallelized fixed-point arithmetic to improve runtime memory and latency. In this work, we replicate the NNA operators during the training phase, accounting for the degradation due to low-precision inference on the NNA in back-propagation. Our proposed method efficiently emulates NNA operations, thus foregoing the need to transfer quantization error-prone data to the Central Processing Unit (CPU), ultimately reducing the user perceived latency (UPL). We apply our approach to Recurrent Neural Network-Transducer (RNN-T), an attractive architecture for on-device streaming speech recognition tasks. We train and evaluate models on 270K hours of English data and show a 5-7% improvement in engine latency while saving up to 10% relative degradation in WER.
* Accepted to SLT 2022
Sub-8-Bit Quantization Aware Training for 8-Bit Neural Network Accelerator with On-Device Speech Recognition
Jun 30, 2022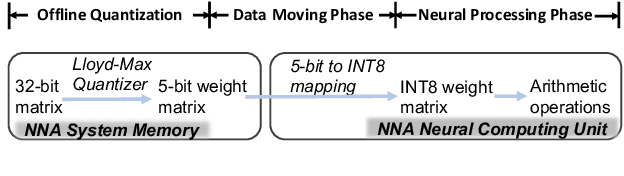
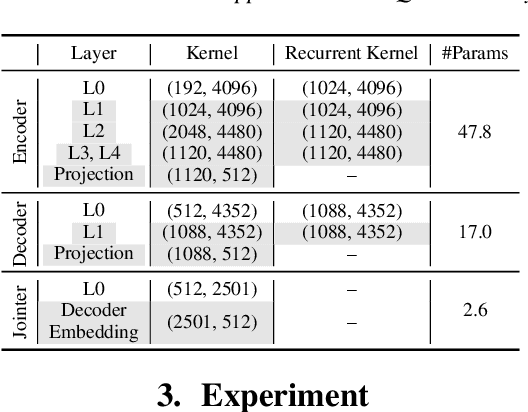
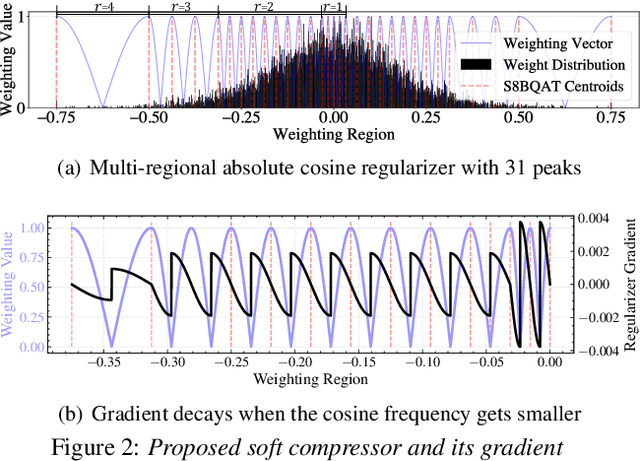
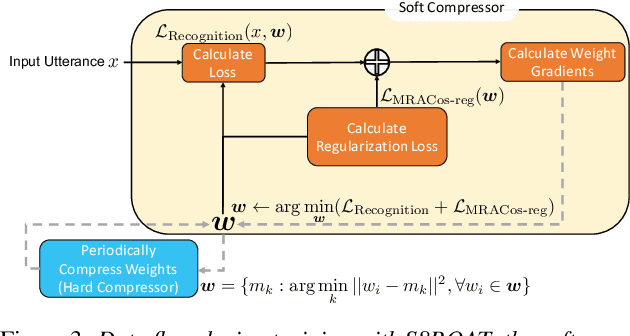
We present a novel sub-8-bit quantization-aware training (S8BQAT) scheme for 8-bit neural network accelerators. Our method is inspired from Lloyd-Max compression theory with practical adaptations for a feasible computational overhead during training. With the quantization centroids derived from a 32-bit baseline, we augment training loss with a Multi-Regional Absolute Cosine (MRACos) regularizer that aggregates weights towards their nearest centroid, effectively acting as a pseudo compressor. Additionally, a periodically invoked hard compressor is introduced to improve the convergence rate by emulating runtime model weight quantization. We apply S8BQAT on speech recognition tasks using Recurrent Neural NetworkTransducer (RNN-T) architecture. With S8BQAT, we are able to increase the model parameter size to reduce the word error rate by 4-16% relatively, while still improving latency by 5%.