 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Acoustic and Semantic Contextual Biasing in Neural Transducers for Speech Recognition
May 09, 2023Attention-based contextual biasing approaches have shown significant improvements in the recognition of generic and/or personal rare-words in End-to-End Automatic Speech Recognition (E2E ASR) systems like neural transducers. These approaches employ cross-attention to bias the model towards specific contextual entities injected as bias-phrases to the model. Prior approaches typically relied on subword encoders for encoding the bias phrases. However, subword tokenizations are coarse and fail to capture granular pronunciation information which is crucial for biasing based on acoustic similarity. In this work, we propose to use lightweight character representations to encode fine-grained pronunciation features to improve contextual biasing guided by acoustic similarity between the audio and the contextual entities (termed acoustic biasing). We further integrate pretrained neural language model (NLM) based encoders to encode the utterance's semantic context along with contextual entities to perform biasing informed by the utterance's semantic context (termed semantic biasing). Experiments using a Conformer Transducer model on the Librispeech dataset show a 4.62% - 9.26% relative WER improvement on different biasing list sizes over the baseline contextual model when incorporating our proposed acoustic and semantic biasing approach. On a large-scale in-house dataset, we observe 7.91% relative WER improvement compared to our baseline model. On tail utterances, the improvements are even more pronounced with 36.80% and 23.40% relative WER improvements on Librispeech rare words and an in-house testset respectively.
Multi-task RNN-T with Semantic Decoder for Streamable Spoken Language Understanding
Apr 01, 2022
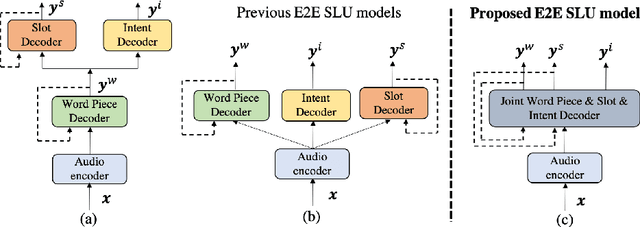
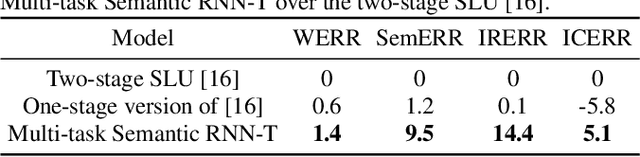
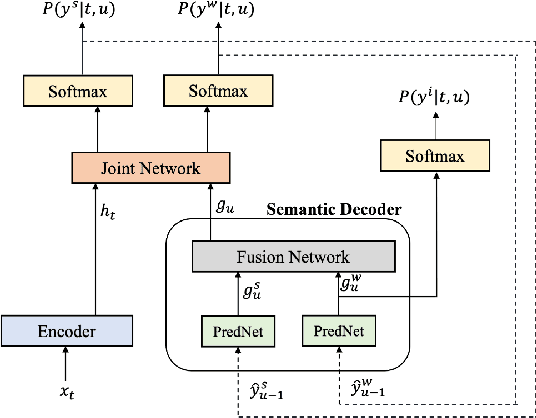
End-to-end Spoken Language Understanding (E2E SLU) has attracted increasing interest due to its advantages of joint optimization and low latency when compared to traditionally cascaded pipelines. Existing E2E SLU models usually follow a two-stage configuration where an Automatic Speech Recognition (ASR) network first predicts a transcript which is then passed to a Natural Language Understanding (NLU) module through an interface to infer semantic labels, such as intent and slot tags. This design, however, does not consider the NLU posterior while making transcript predictions, nor correct the NLU prediction error immediately by considering the previously predicted word-pieces. In addition, the NLU model in the two-stage system is not streamable, as it must wait for the audio segments to complete processing, which ultimately impacts the latency of the SLU system. In this work, we propose a streamable multi-task semantic transducer model to address these considerations. Our proposed architecture predicts ASR and NLU labels auto-regressively and uses a semantic decoder to ingest both previously predicted word-pieces and slot tags while aggregating them through a fusion network. Using an industry scale SLU and a public FSC dataset, we show the proposed model outperforms the two-stage E2E SLU model for both ASR and NLU metrics.