 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Differentiable Relaxation of Graph Segmentation and Alignment for AMR Parsing
Paper and Code
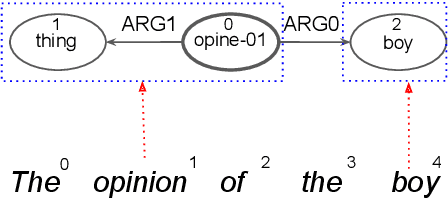
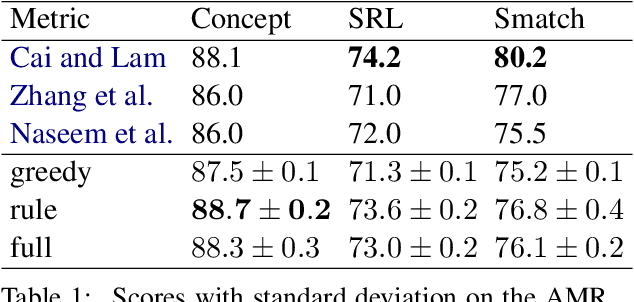
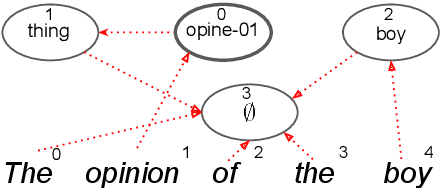
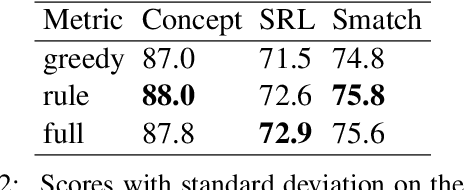
Abstract Meaning Representations (AMR) are a broad-coverage semantic formalism which represents sentence meaning as a directed acyclic graph. To train most AMR parsers, one needs to segment the graph into subgraphs and align each such subgraph to a word in a sentence; this is normally done at preprocessing, relying on hand-crafted rules. In contrast, we treat both alignment and segmentation as latent variables in our model and induce them as part of end-to-end training. As marginalizing over the structured latent variables is infeasible, we use the variational autoencoding framework. To ensure end-to-end differentiable optimization, we introduce a continuous differentiable relaxation of the segmentation and alignment problems. We observe that inducing segmentation yields substantial gains over using a `greedy' segmentation heuristic. The performance of our method also approaches that of a model that relies on \citet{Lyu2018AMRPA}'s segmentation rules, which were hand-crafted to handle individual AMR constructions.