 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale Invariant Privacy Preserving Video via Wavelet Decomposition
Nov 07, 2022Video surveillance has become ubiquitous in the modern world. Mobile devices, surveillance cameras, and IoT devices, all can record video that can violate our privacy. One proposed solution for this is privacy-preserving video, which removes identifying information from the video as it is produced. Several algorithms for this have been proposed, but all of them suffer from scale issues: in order to sufficiently anonymize near-camera objects, distant objects become unidentifiable. In this paper, we propose a scale-invariant method, based on wavelet decomposition.
Collaborative Remote Control of Unmanned Ground Vehicles in Virtual Reality
Aug 24, 2022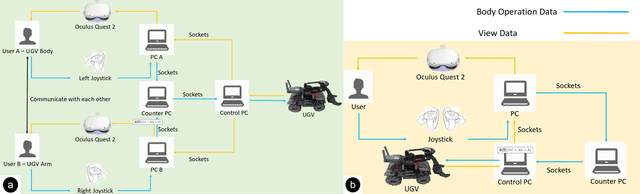
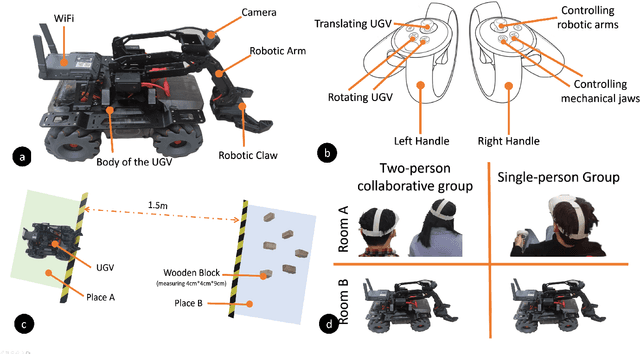
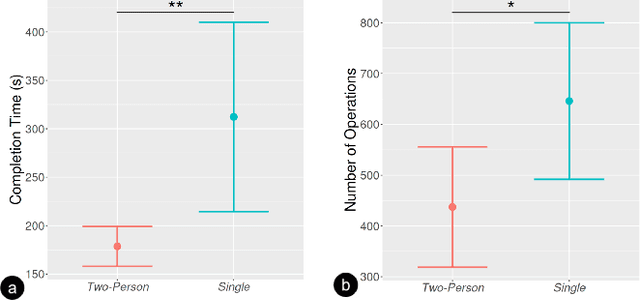
Virtual reality (VR) technology is commonly used in entertainment applications; however, it has also been deployed in practical applications in more serious aspects of our lives, such as safety. To support people working in dangerous industries, VR can ensure operators manipulate standardized tasks and work collaboratively to deal with potential risks. Surprisingly, little research has focused on how people can collaboratively work in VR environments. Few studies have paid attention to the cognitive load of operators in their collaborative tasks. Once task demands become complex, many researchers focus on optimizing the design of the interaction interfaces to reduce the cognitive load on the operator. That approach could be of merit; however, it can actually subject operators to a more significant cognitive load and potentially more errors and a failure of collaboration. In this paper, we propose a new collaborative VR system to support two teleoperators working in the VR environment to remote control an uncrewed ground vehicle. We use a compared experiment to evaluate the collaborative VR systems, focusing on the time spent on tasks and the total number of operations. Our results show that the total number of processes and the cognitive load during operations were significantly lower in the two-person group than in the single-person group. Our study sheds light on designing VR systems to support collaborative work with respect to the flow of work of teleoperators instead of simply optimizing the design outcomes.
Mirror-Yolo: An attention-based instance segmentation and detection model for mirrors
Feb 17, 2022
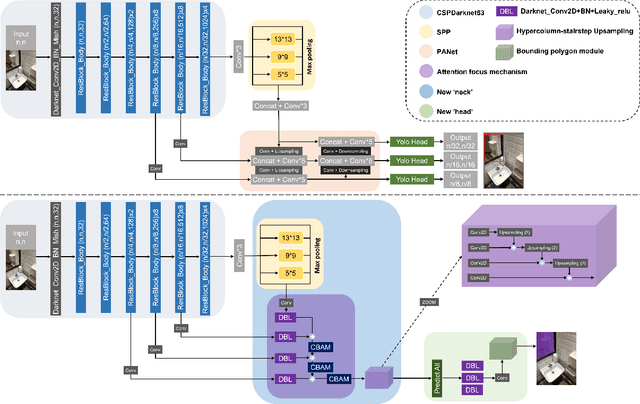
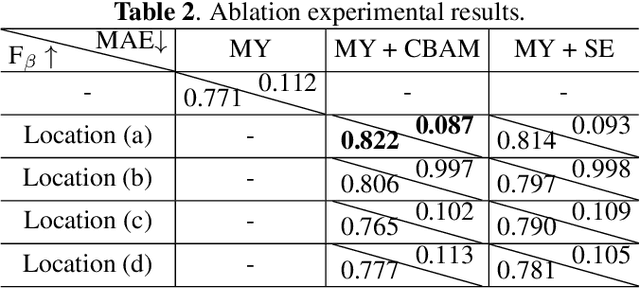
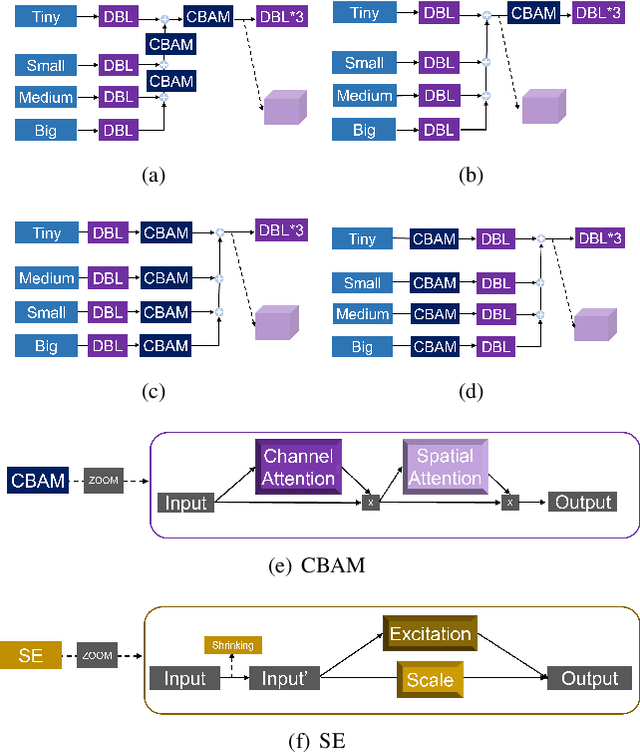
Mirrors can degrade the performance of computer vision models, however to accurately detect mirrors in images remains challenging. YOLOv4 achieves phenomenal results both in object detection accuracy and speed, nevertheless the model often fails in detecting mirrors. In this paper, a novel mirror detection method `Mirror-YOLO' is proposed, which mainly targets on mirror detection. Based on YOLOv4, the proposed model embeds an attention mechanism for better feature acquisition, and a hypercolumn-stairstep approach for feature map fusion. Mirror-YOLO can also produce accurate bounding polygons for instance segmentation. The effectiveness of our proposed model is demonstrated by our experiments, compared to the existing mirror detection methods, the proposed Mirror-YOLO achieves better performance in detection accuracy on the mirror image dataset.
A Unified Gradient Regularization Family for Adversarial Examples
Nov 19, 2015



Adversarial examples are augmented data points generated by imperceptible perturbation of input samples. They have recently drawn much attention with the machine learning and data mining community. Being difficult to distinguish from real examples, such adversarial examples could change the prediction of many of the best learning models including the state-of-the-art deep learning models. Recent attempts have been made to build robust models that take into account adversarial examples. However, these methods can either lead to performance drops or lack mathematical motivations. In this paper, we propose a unified framework to build robust machine learning models against adversarial examples. More specifically, using the unified framework, we develop a family of gradient regularization methods that effectively penalize the gradient of loss function w.r.t. inputs. Our proposed framework is appealing in that it offers a unified view to deal with adversarial examples. It incorporates another recently-proposed perturbation based approach as a special case. In addition, we present some visual effects that reveals semantic meaning in those perturbations, and thus support our regularization method and provide another explanation for generalizability of adversarial examples. By applying this technique to Maxout networks, we conduct a series of experiments and achieve encouraging results on two benchmark datasets. In particular,we attain the best accuracy on MNIST data (without data augmentation) and competitive performance on CIFAR-10 data.