 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCNAC: A Variable-Channel Neural Audio Codec for Mono, Stereo, and Surround Sound
Jan 21, 2026We present VCNAC, a variable channel neural audio codec. Our approach features a single encoder and decoder parametrization that enables native inference for different channel setups, from mono speech to cinematic 5.1 channel surround audio. Channel compatibility objectives ensure that multi-channel content maintains perceptual quality when decoded to fewer channels. The shared representation enables training of generative language models on a single set of codebooks while supporting inference-time scalability across modalities and channel configurations. Evaluation using objective spatial audio metrics and subjective listening tests demonstrates that our unified approach maintains high reconstruction quality across mono, stereo, and surround audio configurations.
SIFT-50M: A Large-Scale Multilingual Dataset for Speech Instruction Fine-Tuning
Apr 12, 2025We introduce SIFT (Speech Instruction Fine-Tuning), a 50M-example dataset designed for instruction fine-tuning and pre-training of speech-text large language models (LLMs). SIFT-50M is built from publicly available speech corpora, which collectively contain 14K hours of speech, and leverages LLMs along with off-the-shelf expert models. The dataset spans five languages, encompassing a diverse range of speech understanding as well as controllable speech generation instructions. Using SIFT-50M, we train SIFT-LLM, which outperforms existing speech-text LLMs on instruction-following benchmarks while achieving competitive performance on foundational speech tasks. To support further research, we also introduce EvalSIFT, a benchmark dataset specifically designed to evaluate the instruction-following capabilities of speech-text LLMs.
Promptformer: Prompted Conformer Transducer for ASR
Jan 14, 2024



Context cues carry information which can improve multi-turn interactions in automatic speech recognition (ASR) systems. In this paper, we introduce a novel mechanism inspired by hyper-prompting to fuse textual context with acoustic representations in the attention mechanism. Results on a test set with multi-turn interactions show that our method achieves 5.9% relative word error rate reduction (rWERR) over a strong baseline. We show that our method does not degrade in the absence of context and leads to improvements even if the model is trained without context. We further show that leveraging a pre-trained sentence-piece model for context embedding generation can outperform an external BERT model.
Bi-Linear Homogeneity Enforced Calibration for Pipelined ADCs
Sep 06, 2023Pipelined analog-to-digital converters (ADCs) are key enablers in many state-of-the-art signal processing systems with high sampling rates. In addition to high sampling rates, such systems often demand a high linearity. To meet these challenging linearity requirements, ADC calibration techniques were heavily investigated throughout the past decades. One limitation in ADC calibration is the need for a precisely known test signal. In our previous work, we proposed the homogeneity enforced calibration (HEC) approach, which circumvents this need by consecutively feeding a test signal and a scaled version of it into the ADC. The calibration itself is performed using only the corresponding output samples, such that the test signal can remain unknown. On the downside, the HEC approach requires the option to accurately scale the test signal, impeding an on-chip implementation. In this work, we provide a thorough analysis of the HEC approach, including the effects of an inaccurately scaled test signal. Furthermore, the bi-linear homogeneity enforced calibration (BL-HEC) approach is introduced and suggested to account for an inaccurate scaling and, therefore, to facilitate an on-chip implementation. In addition, a comprehensive stability and convergence analysis of the BL-HEC approach is carried out. Finally, we verify our concept with simulations.
Personalized Predictive ASR for Latency Reduction in Voice Assistants
May 23, 2023Streaming Automatic Speech Recognition (ASR) in voice assistants can utilize prefetching to partially hide the latency of response generation. Prefetching involves passing a preliminary ASR hypothesis to downstream systems in order to prefetch and cache a response. If the final ASR hypothesis after endpoint detection matches the preliminary one, the cached response can be delivered to the user, thus saving latency. In this paper, we extend this idea by introducing predictive automatic speech recognition, where we predict the full utterance from a partially observed utterance, and prefetch the response based on the predicted utterance. We introduce two personalization approaches and investigate the tradeoff between potential latency gains from successful predictions and the cost increase from failed predictions. We evaluate our methods on an internal voice assistant dataset as well as the public SLURP dataset.
Contextual-Utterance Training for Automatic Speech Recognition
Oct 27, 2022



Recent studies of streaming automatic speech recognition (ASR) recurrent neural network transducer (RNN-T)-based systems have fed the encoder with past contextual information in order to improve its word error rate (WER) performance. In this paper, we first propose a contextual-utterance training technique which makes use of the previous and future contextual utterances in order to do an implicit adaptation to the speaker, topic and acoustic environment. Also, we propose a dual-mode contextual-utterance training technique for streaming automatic speech recognition (ASR) systems. This proposed approach allows to make a better use of the available acoustic context in streaming models by distilling "in-place" the knowledge of a teacher, which is able to see both past and future contextual utterances, to the student which can only see the current and past contextual utterances. The experimental results show that a conformer-transducer system trained with the proposed techniques outperforms the same system trained with the classical RNN-T loss. Specifically, the proposed technique is able to reduce both the WER and the average last token emission latency by more than 6% and 40ms relative, respectively.
Multi-channel Opus compression for far-field automatic speech recognition with a fixed bitrate budget
Jun 15, 2021

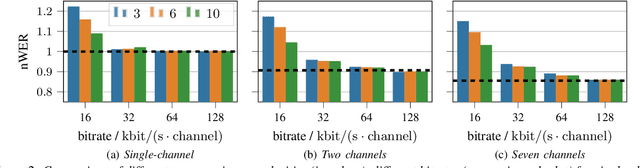
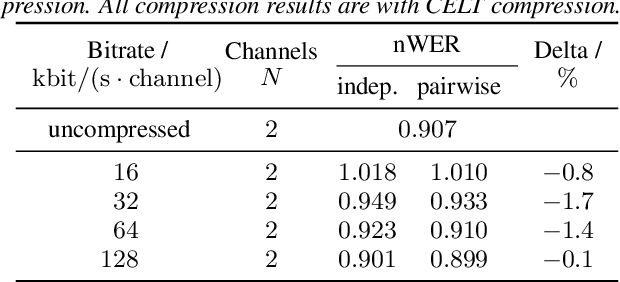
Automatic speech recognition (ASR) in the cloud allows the use of larger models and more powerful multi-channel signal processing front-ends compared to on-device processing. However, it also adds an inherent latency due to the transmission of the audio signal, especially when transmitting multiple channels of a microphone array. One way to reduce the network bandwidth requirements is client-side compression with a lossy codec such as Opus. However, this compression can have a detrimental effect especially on multi-channel ASR front-ends, due to the distortion and loss of spatial information introduced by the codec. In this publication, we propose an improved approach for the compression of microphone array signals based on Opus, using a modified joint channel coding approach and additionally introducing a multi-channel spatial decorrelating transform to reduce redundancy in the transmission. We illustrate the effect of the proposed approach on the spatial information retained in multi-channel signals after compression, and evaluate the performance on far-field ASR with a multi-channel beamforming front-end. We demonstrate that our approach can lead to a 37.5 % bitrate reduction or a 5.1 % relative word error rate reduction for a fixed bitrate budget in a seven channel setup.
Spatial Diffuseness Features for DNN-Based Speech Recognition in Noisy and Reverberant Environments
Feb 16, 2015


We propose a spatial diffuseness feature for deep neural network (DNN)-based automatic speech recognition to improve recognition accuracy in reverberant and noisy environments. The feature is computed in real-time from multiple microphone signals without requiring knowledge or estimation of the direction of arrival, and represents the relative amount of diffuse noise in each time and frequency bin. It is shown that using the diffuseness feature as an additional input to a DNN-based acoustic model leads to a reduced word error rate for the REVERB challenge corpus, both compared to logmelspec features extracted from noisy signals, and features enhanced by spectral subtraction.