 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCNAC: A Variable-Channel Neural Audio Codec for Mono, Stereo, and Surround Sound
Jan 21, 2026We present VCNAC, a variable channel neural audio codec. Our approach features a single encoder and decoder parametrization that enables native inference for different channel setups, from mono speech to cinematic 5.1 channel surround audio. Channel compatibility objectives ensure that multi-channel content maintains perceptual quality when decoded to fewer channels. The shared representation enables training of generative language models on a single set of codebooks while supporting inference-time scalability across modalities and channel configurations. Evaluation using objective spatial audio metrics and subjective listening tests demonstrates that our unified approach maintains high reconstruction quality across mono, stereo, and surround audio configurations.
SIFT-50M: A Large-Scale Multilingual Dataset for Speech Instruction Fine-Tuning
Apr 12, 2025We introduce SIFT (Speech Instruction Fine-Tuning), a 50M-example dataset designed for instruction fine-tuning and pre-training of speech-text large language models (LLMs). SIFT-50M is built from publicly available speech corpora, which collectively contain 14K hours of speech, and leverages LLMs along with off-the-shelf expert models. The dataset spans five languages, encompassing a diverse range of speech understanding as well as controllable speech generation instructions. Using SIFT-50M, we train SIFT-LLM, which outperforms existing speech-text LLMs on instruction-following benchmarks while achieving competitive performance on foundational speech tasks. To support further research, we also introduce EvalSIFT, a benchmark dataset specifically designed to evaluate the instruction-following capabilities of speech-text LLMs.
Promptformer: Prompted Conformer Transducer for ASR
Jan 14, 2024



Context cues carry information which can improve multi-turn interactions in automatic speech recognition (ASR) systems. In this paper, we introduce a novel mechanism inspired by hyper-prompting to fuse textual context with acoustic representations in the attention mechanism. Results on a test set with multi-turn interactions show that our method achieves 5.9% relative word error rate reduction (rWERR) over a strong baseline. We show that our method does not degrade in the absence of context and leads to improvements even if the model is trained without context. We further show that leveraging a pre-trained sentence-piece model for context embedding generation can outperform an external BERT model.
Unified Modeling of Multi-Domain Multi-Device ASR Systems
May 13, 2022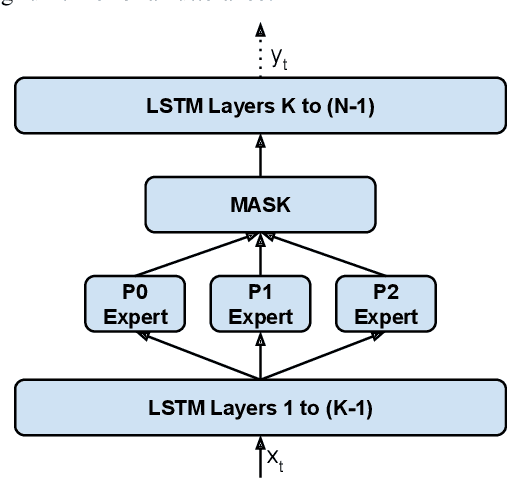

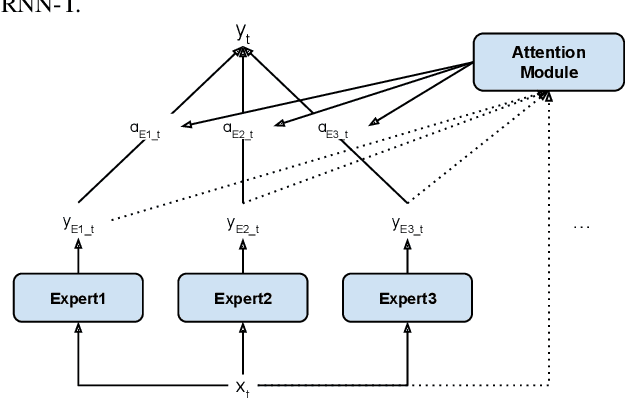
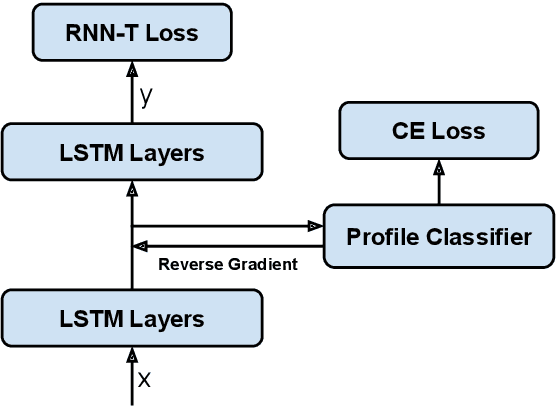
Modern Automatic Speech Recognition (ASR) systems often use a portfolio of domain-specific models in order to get high accuracy for distinct user utterance types across different devices. In this paper, we propose an innovative approach that integrates the different per-domain per-device models into a unified model, using a combination of domain embedding, domain experts, mixture of experts and adversarial training. We run careful ablation studies to show the benefit of each of these innovations in contributing to the accuracy of the overall unified model. Experiments show that our proposed unified modeling approach actually outperforms the carefully tuned per-domain models, giving relative gains of up to 10% over a baseline model with negligible increase in the number of parameters.