 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Semantic Disentangled Privacy-preserving Speech Representation Learning
May 19, 2025The use of audio recordings of human speech to train LLMs poses privacy concerns due to these models' potential to generate outputs that closely resemble artifacts in the training data. In this study, we propose a speaker privacy-preserving representation learning method through the Universal Speech Codec (USC), a computationally efficient encoder-decoder model that disentangles speech into: $\textit{(i)}$ privacy-preserving semantically rich representations, capturing content and speech paralinguistics, and $\textit{(ii)}$ residual acoustic and speaker representations that enables high-fidelity reconstruction. Extensive evaluations presented show that USC's semantic representation preserves content, prosody, and sentiment, while removing potentially identifiable speaker attributes. Combining both representations, USC achieves state-of-the-art speech reconstruction. Additionally, we introduce an evaluation methodology for measuring privacy-preserving properties, aligning with perceptual tests. We compare USC against other codecs in the literature and demonstrate its effectiveness on privacy-preserving representation learning, illustrating the trade-offs of speaker anonymization, paralinguistics retention and content preservation in the learned semantic representations. Audio samples are shared in $\href{https://www.amazon.science/usc-samples}{https://www.amazon.science/usc-samples}$.
Promptformer: Prompted Conformer Transducer for ASR
Jan 14, 2024



Context cues carry information which can improve multi-turn interactions in automatic speech recognition (ASR) systems. In this paper, we introduce a novel mechanism inspired by hyper-prompting to fuse textual context with acoustic representations in the attention mechanism. Results on a test set with multi-turn interactions show that our method achieves 5.9% relative word error rate reduction (rWERR) over a strong baseline. We show that our method does not degrade in the absence of context and leads to improvements even if the model is trained without context. We further show that leveraging a pre-trained sentence-piece model for context embedding generation can outperform an external BERT model.
Lattention: Lattice-attention in ASR rescoring
Nov 19, 2021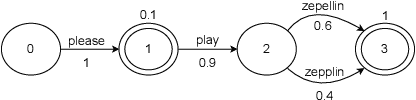
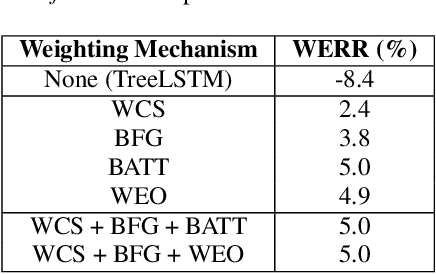
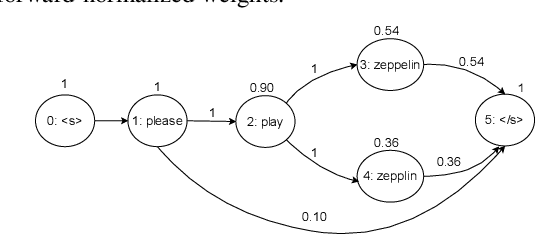
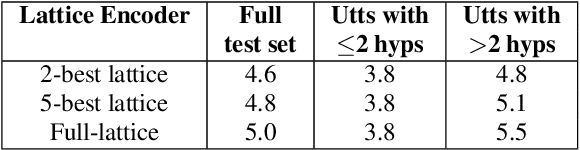
Lattices form a compact representation of multiple hypotheses generated from an automatic speech recognition system and have been shown to improve performance of downstream tasks like spoken language understanding and speech translation, compared to using one-best hypothesis. In this work, we look into the effectiveness of lattice cues for rescoring n-best lists in second-pass. We encode lattices with a recurrent network and train an attention encoder-decoder model for n-best rescoring. The rescoring model with attention to lattices achieves 4-5% relative word error rate reduction over first-pass and 6-8% with attention to both lattices and acoustic features. We show that rescoring models with attention to lattices outperform models with attention to n-best hypotheses. We also study different ways to incorporate lattice weights in the lattice encoder and demonstrate their importance for n-best rescoring.