 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptformer: Prompted Conformer Transducer for ASR
Jan 14, 2024



Context cues carry information which can improve multi-turn interactions in automatic speech recognition (ASR) systems. In this paper, we introduce a novel mechanism inspired by hyper-prompting to fuse textual context with acoustic representations in the attention mechanism. Results on a test set with multi-turn interactions show that our method achieves 5.9% relative word error rate reduction (rWERR) over a strong baseline. We show that our method does not degrade in the absence of context and leads to improvements even if the model is trained without context. We further show that leveraging a pre-trained sentence-piece model for context embedding generation can outperform an external BERT model.
Contextual-Utterance Training for Automatic Speech Recognition
Oct 27, 2022



Recent studies of streaming automatic speech recognition (ASR) recurrent neural network transducer (RNN-T)-based systems have fed the encoder with past contextual information in order to improve its word error rate (WER) performance. In this paper, we first propose a contextual-utterance training technique which makes use of the previous and future contextual utterances in order to do an implicit adaptation to the speaker, topic and acoustic environment. Also, we propose a dual-mode contextual-utterance training technique for streaming automatic speech recognition (ASR) systems. This proposed approach allows to make a better use of the available acoustic context in streaming models by distilling "in-place" the knowledge of a teacher, which is able to see both past and future contextual utterances, to the student which can only see the current and past contextual utterances. The experimental results show that a conformer-transducer system trained with the proposed techniques outperforms the same system trained with the classical RNN-T loss. Specifically, the proposed technique is able to reduce both the WER and the average last token emission latency by more than 6% and 40ms relative, respectively.
Adversarial Transformation of Spoofing Attacks for Voice Biometrics
Jan 04, 2022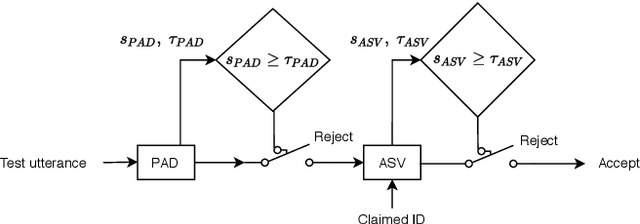
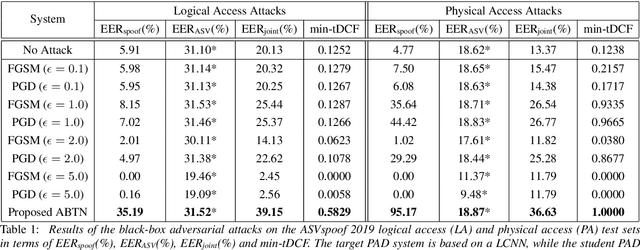
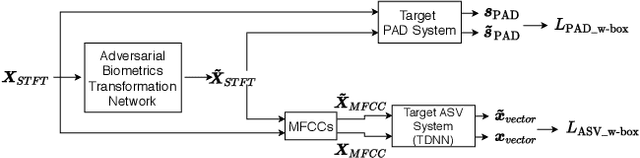
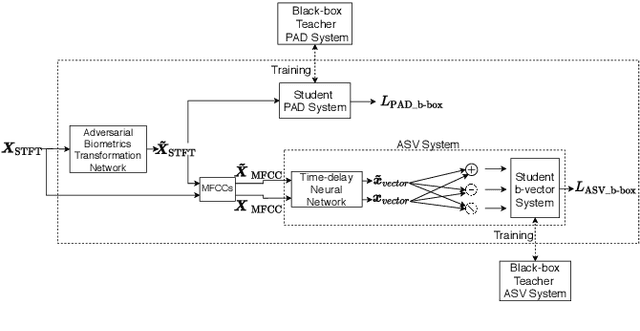
Voice biometric systems based on automatic speaker verification (ASV) are exposed to \textit{spoofing} attacks which may compromise their security. To increase the robustness against such attacks, anti-spoofing or presentation attack detection (PAD) systems have been proposed for the detection of replay, synthesis and voice conversion based attacks. Recently, the scientific community has shown that PAD systems are also vulnerable to adversarial attacks. However, to the best of our knowledge, no previous work have studied the robustness of full voice biometrics systems (ASV + PAD) to these new types of adversarial \textit{spoofing} attacks. In this work, we develop a new adversarial biometrics transformation network (ABTN) which jointly processes the loss of the PAD and ASV systems in order to generate white-box and black-box adversarial \textit{spoofing} attacks. The core idea of this system is to generate adversarial \textit{spoofing} attacks which are able to fool the PAD system without being detected by the ASV system. The experiments were carried out on the ASVspoof 2019 corpus, including both logical access (LA) and physical access (PA) scenarios. The experimental results show that the proposed ABTN clearly outperforms some well-known adversarial techniques in both white-box and black-box attack scenarios.
PANACEA cough sound-based diagnosis of COVID-19 for the DiCOVA 2021 Challenge
Jun 07, 2021
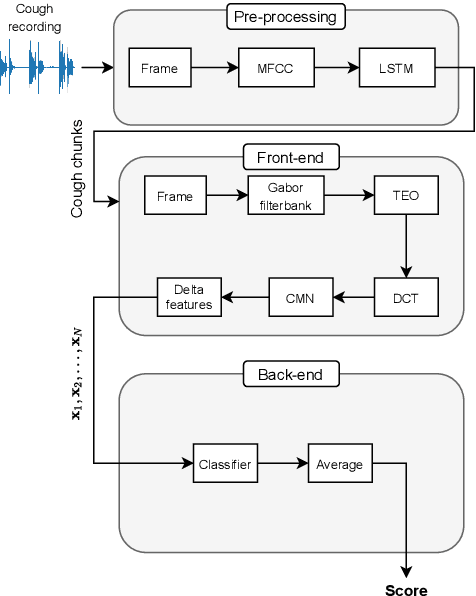
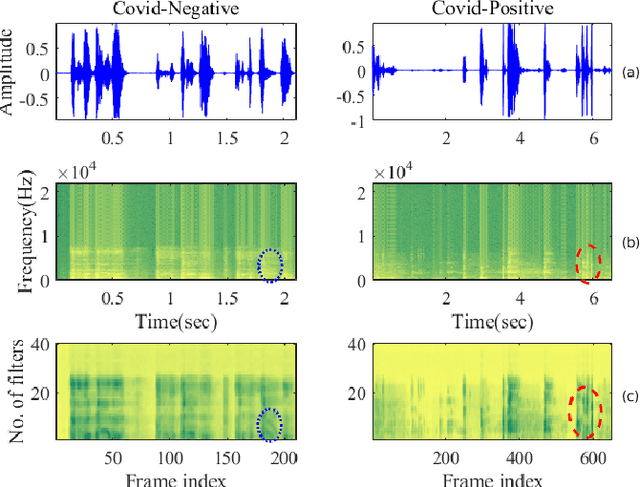
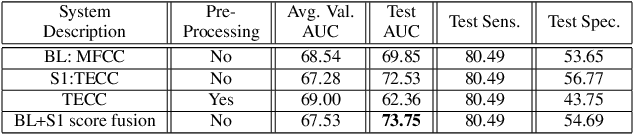
The COVID-19 pandemic has led to the saturation of public health services worldwide. In this scenario, the early diagnosis of SARS-Cov-2 infections can help to stop or slow the spread of the virus and to manage the demand upon health services. This is especially important when resources are also being stretched by heightened demand linked to other seasonal diseases, such as the flu. In this context, the organisers of the DiCOVA 2021 challenge have collected a database with the aim of diagnosing COVID-19 through the use of coughing audio samples. This work presents the details of the automatic system for COVID-19 detection from cough recordings presented by team PANACEA. This team consists of researchers from two European academic institutions and one company: EURECOM (France), University of Granada (Spain), and Biometric Vox S.L. (Spain). We developed several systems based on established signal processing and machine learning methods. Our best system employs a Teager energy operator cepstral coefficients (TECCs) based frontend and Light gradient boosting machine (LightGBM) backend. The AUC obtained by this system on the test set is 76.31% which corresponds to a 10% improvement over the official baseline.
Multi-view Temporal Alignment for Non-parallel Articulatory-to-Acoustic Speech Synthesis
Dec 30, 2020
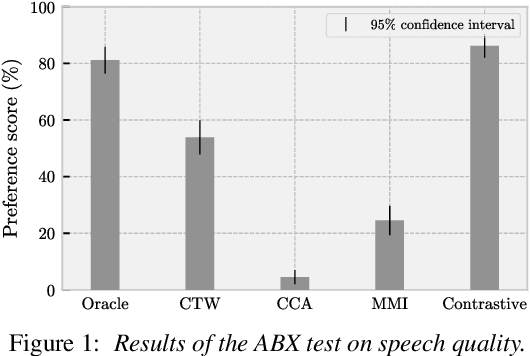
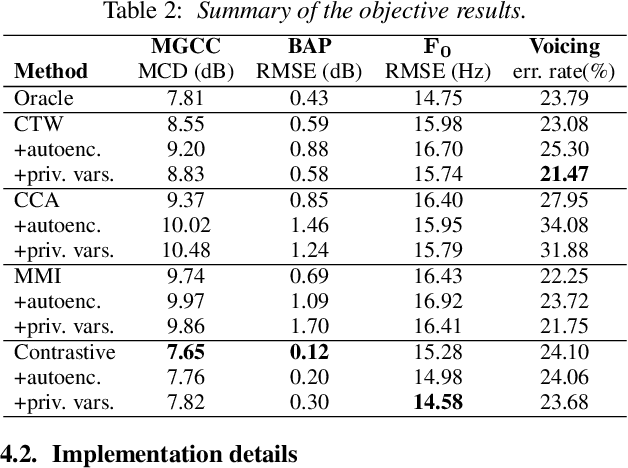
Articulatory-to-acoustic (A2A) synthesis refers to the generation of audible speech from captured movement of the speech articulators. This technique has numerous applications, such as restoring oral communication to people who cannot longer speak due to illness or injury. Most successful techniques so far adopt a supervised learning framework, in which time-synchronous articulatory-and-speech recordings are used to train a supervised machine learning algorithm that can be used later to map articulator movements to speech. This, however, prevents the application of A2A techniques in cases where parallel data is unavailable, e.g., a person has already lost her/his voice and only articulatory data can be captured. In this work, we propose a solution to this problem based on the theory of multi-view learning. The proposed algorithm attempts to find an optimal temporal alignment between pairs of non-aligned articulatory-and-acoustic sequences with the same phonetic content by projecting them into a common latent space where both views are maximally correlated and then applying dynamic time warping. Several variants of this idea are discussed and explored. We show that the quality of speech generated in the non-aligned scenario is comparable to that obtained in the parallel scenario.
Silent Speech Interfaces for Speech Restoration: A Review
Sep 27, 2020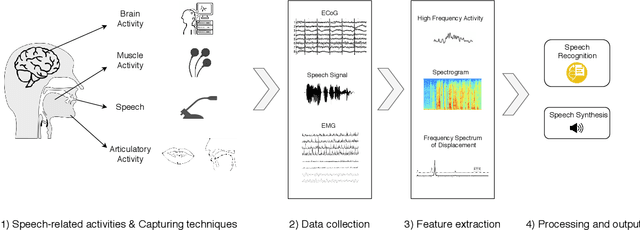

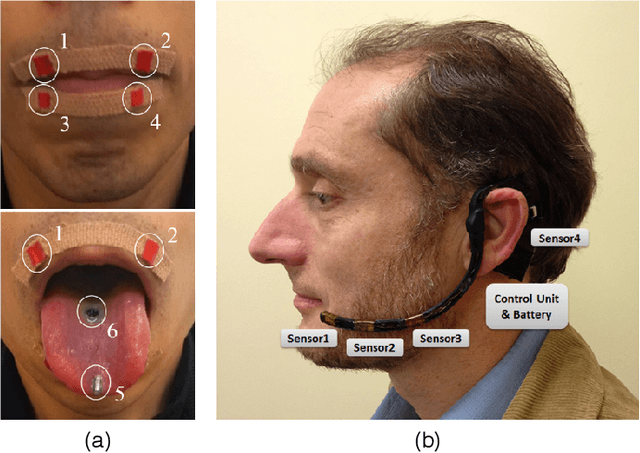

This review summarises the status of silent speech interface (SSI) research. SSIs rely on non-acoustic biosignals generated by the human body during speech production to enable communication whenever normal verbal communication is not possible or not desirable. In this review, we focus on the first case and present latest SSI research aimed at providing new alternative and augmentative communication methods for persons with severe speech disorders. SSIs can employ a variety of biosignals to enable silent communication, such as electrophysiological recordings of neural activity, electromyographic (EMG) recordings of vocal tract movements or the direct tracking of articulator movements using imaging techniques. Depending on the disorder, some sensing techniques may be better suited than others to capture speech-related information. For instance, EMG and imaging techniques are well suited for laryngectomised patients, whose vocal tract remains almost intact but are unable to speak after the removal of the vocal folds, but fail for severely paralysed individuals. From the biosignals, SSIs decode the intended message, using automatic speech recognition or speech synthesis algorithms. Despite considerable advances in recent years, most present-day SSIs have only been validated in laboratory settings for healthy users. Thus, as discussed in this paper, a number of challenges remain to be addressed in future research before SSIs can be promoted to real-world applications. If these issues can be addressed successfully, future SSIs will improve the lives of persons with severe speech impairments by restoring their communication capabilities.